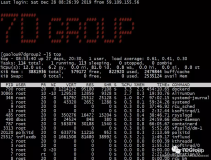
使用w查看系统负载
w/uptime/top 查看系统负载
[root@lsxlinux02 awk]# w //当负载大于cpu核数时,cpu使用率不会过大,不太损耗cpu
04:46:08 up 23:19, 2 users, load average: 0.00, 0.01, 0.05
USER TTY LOGIN@ IDLE JCPU PCPU WHAT
root tty1 五05 11:03m 1.83s 1.83s -bash
root pts/0 03:44 0.00s 0.39s 0.01s w
系统时间 启动多久 登录几个用户 系统负载:分别是1、5、15分钟平均负载(单位时间内,使用活动的进程)
登录的用户 登录的终端 登录的时间
[root@lsx-02 ~]# uptime
21:12:21 up 21:50, 3 users, load average: 0.00, 0.01, 0.05
load average: 0.00, 0.01, 0.05 负载多少算合适呢?
需要看有几核逻辑cpu
cat /proc/cpuinfo 查看cpu核数
[root@lsx-02 ~]# cat /proc/cpuinfo
processor : 0说明只有一核逻辑cpu(n-1)当负载为一的时候最合理 一核cpu处理一个进程
vendor_id : GenuineIntel
cpu family : 6
model : 42
model name : Intel(R) Core(TM) i5-2540M CPU @ 2.60GHz
stepping : 7
microcode : 0x15
cpu MHz : 2591.639
10.2 vmstat命令
vmstat 监控系统状态(查看系统瓶颈)
用法 vmstat 1
关键的几列:r,b,swpd,si,so,bi,bo,us,wa
当系统负载值偏高时,可以使用vmstat查看是哪里出了问题。
比如负载大于CPU核数了,cpu不够用了。是什么原因导致?进程在干什么?都有哪些任务在使用cpu?这时更想查看系统瓶颈在哪
[root@lsx-02 ~]# vmstat 1 3 一秒钟显示一次,只要显示3次
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 46844 95764 0 367396 0 1 14 13 23 24 1 0 99 0 0
0 0 46844 95740 0 367396 0 0 0 0 14 17 0 0 100 0 0
0 0 46844 95740 0 367396 0 0 0 0 18 17 0 0 100 0 0
参数 说明
r run 表示多少进程处于run状态(只要是在排队等待就是run状态)(如果该数值长期大于cpu数量,说明cpu资源不够了)
b 被cpu其他的硬盘、网络阻断了,卡死状态。block 等待资源的进程数(I/O)
swpd 当内存不够的时候,会把内存一部分数据放在swap交换分区(变化频繁,内存不够)(swap会影响si、so)
si 有多少kb数据由内存交换区进入内存数量。参照物内存
so 由内存进入内存交换区数量
bi 和磁盘有关。从磁盘出来进入内存 读的数据量有多少
bo 写入到磁盘里去(bi、bo这两数字大在频繁读写影响b)
us 用户级别跑的资源应用占用cpu百分比 不超过100。(如果长期大于50,系统资源不够)
sy 系统本身占用多少
id 空闲 (us + sy + id =100)
wa 等待cpu百分比,有多少进程等待cpu。列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
10.3 top命令
Top动态的查看和ps静态
W查看系统负载、vmstat查看系统瓶颈(知道了,内存不够、磁盘读写太高。能否知道具体是哪个进程呢?)、可以使用top查看进程使用资源情况。
top查看进程使用资源情况
[root@lsx-02 ~]# top
top - 21:53:01 up 22:30, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 214 total, 2 running, 212 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem: 615596 total, 520364 used, 95232 free, 0 buffers
KiB Swap: 2097148 total, 46844 used, 2050304 free. 367556 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11845 root 20 0 0 0 0 S 0.3 0.0 0:04.62 kworker/0:1
11914 root 20 0 123704 1676 1160 R 0.3 0.3 0:00.53 top
1 root 20 0 49900 3408 2048 S 0.0 0.6 0:05.38 systemd
参数 说明
task 共有多少任务 在跑的有几个 几个处于睡眠 多少停止 多少处于僵尸僵尸:主进程被意外终止了,子进程在那
Cpu百分比 us占用多少 sy占用多少 id空闲 多少wa st被偷走的cpu百分比
st 被偷走的cpu百分比(如果主机做了虚拟化、一些虚拟机会偷走一些cpu)
us 长时间处于60%以上对cpu没什么好处(和负载不同,负载可以很高,us可以很低。如果us很高,负载肯定很高。因为cpu很慢,其他进程就要等待,负载就更高)
RES 物理内存大小k
PID 进程序号。杀进程可以使用pid
COMMAND 进程名字
大写的P 按cpu排序(按占用的大到小的顺序)
大写的M 按内存排序
数字1 所有cpu使用百分比的情况(平常看到的是平均值)显示所有核cpu
q 退出
top -c 显示详细的进程信息
top -bn1 静态显示所有进程
[root@lsx-02 ~]# top -bn1 适合写脚本的时候使用
top - 22:17:36 up 22:55, 3 users, load average: 0.03, 0.03, 0.05
Tasks: 213 total, 2 running, 211 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.5 us, 0.2 sy, 0.0 ni, 99.0 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem: 615596 total, 520332 used, 95264 free, 0 buffers
KiB Swap: 2097148 total, 46832 used, 2050316 free. 367564 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11942 root 20 0 123712 1508 1064 R 10.9 0.2 0:00.52 top
11845 root 20 0 0 0 0 S 5.5 0.0 0:05.89 kworker/0:1
1 root 20 0 49900 3408 2048 S 0.0 0.6 0:05.43 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:04.55 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
10.4 sar命令
Sar是一个全面的分析系统状态的工具。这里主要查看网卡的流量
yum install -y sysstat
[root@localhost ~]# yum install -y sysstat
[root@localhost ~]# sar //如果不加选项参数,默认调用保留的历史文件
无法打开 /var/log/sa/sa23: 没有那个文件或目录(sar每十分钟会抓一遍系统的状态放到这个文件里)
sar -n DEV 1 4 //显示网卡流量每秒钟1次一共4次
[root@localhost ~]# sar -n DEV 1 4
Linux 3.10.0-123.el7.x86_64 (localhost.localdomain) 2017年11月23日 _x8664
22时27分14秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmc
22时27分15秒 eno16777728 0.99 0.99 0.06 0.20 0.00 0.00
22时27分15秒 lo 0.00 0.00 0.00 0.00 0.00 0.00
22时27分15秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmc
22时27分16秒 eno16777728 1.00 1.00 0.06 0.40 0.00 0.00
22时27分16秒 lo 0.00 0.00 0.00 0.00 0.00 0.00
参数 说明
rxpck/s 接收的数据包量。单位个。(受到攻击就是别人向你的网卡发送大量数据包,量大网卡接收不了,导致网络堵塞,网站不能打开)。
rx 接收到的数据包
tx 发送出去的数据包
rxpck/s数据包多少算合适?
2000+正常 上万不太正常。还需要借用抓包工具判断是否被攻击
如果rxpck大于4000或者rxkb大于5000000,可能被攻击
平时也要看网卡的流量是否跑满。100M带宽换算成可以理解的速率12M每秒。也要看下txkB/s
rxkB/s 接收的数据量。单位kb
[root@lsx-02 ~]# sar
Linux 3.10.0-123.el7.x86_64 (lsx-02) 2017年09月16日 _x8664 (1 CPU)
22时50分01秒 CPU %user %nice %system %iowait %steal %idle
23时00分02秒 all 0.01 0.00 0.12 0.01 0.00 99.87
平均时间: all 0.01 0.00 0.12 0.01 0.00 99.87
[root@lsx-02 ~]# ls /var/log/sa/ 已经生成
sa16
sar -f /var/log/sa/saxx 历史文件
[root@lsx-02 ~]# sar -n DEV -f /var/log/sa/sa16 可以查看历史数据 最多保留一个月
Linux 3.10.0-123.el7.x86_64 (lsx-02) 2017年09月16日 _x8664 (1 CPU)
22时50分01秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
23时00分02秒 eno16777736 0.12 0.11 0.01 0.01 0.00 0.00 0.00
23时00分02秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: eno16777736 0.12 0.11 0.01 0.01 0.00 0.00 0.00
平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sar17 要第二天才生成,是可以直接cat
sa(二进制文件) 只能通过sar –f 查看
sar -q 系统负载(一般sar -q查看历史数据)
sar -q 1 3
Linux 3.10.0-123.el7.x86_64 (localhost.localdomain) 2017年11月23日 _x8664 (1 CPU)
22时55分23秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
22时55分24秒 1 224 0.00 0.01 0.05 0
22时55分25秒 1 224 0.00 0.01 0.05 0
22时55分26秒 1 224 0.00 0.01 0.05 0
平均时间: 1 224 0.00 0.01 0.05 0
sar -b 磁盘读写
sar -b 1 2
Linux 3.10.0-123.el7.x86_64 (localhost.localdomain) 2017年11月23日 _x8664 (1 CPU)
22时56分36秒 tps rtps wtps bread/s bwrtn/s
22时56分37秒 0.00 0.00 0.00 0.00 0.00
22时56分38秒 0.00 0.00 0.00 0.00 0.00
平均时间: 0.00 0.00 0.00 0.00 0.00
10.5 nload命令
nload命令
yum install -y epel-release
yum install -y nload
nload
监控网卡流量 分别是网卡名称、ip、个数。按方向键切换。 当前值、平均值、最小值、最大值
买带宽通常是出去的(out)。100M带宽,MAX最大76M还没跑满但是也快满了。
量很大(如100M)Curr=100M说明已经满了
如果被攻击进来的(Inconing)会很大
本文转自 虾米的春天 51CTO博客,原文链接:http://blog.51cto.com/lsxme/2044961,如需转载请自行联系原作者