目录
Hive数据分析
这里我是用500w条搜狗搜索数据,使用Hive对其进行了分析,并使用Excel绘制图表。
一、数据处理
搜狗搜索日志的数据由六个字段构成,依次是:访问时间(st),用户ID(uid),搜索关键词(keyword),网页排名(Rank),点击次序(Order),网址(URL),字段之间用TAB键隔开,且每条数据占据一行,500w行共500w条原始数据。数据的时间均匀分布在2012年12月30日整天及31日小部分;用户ID可以独立且唯一的标识一个用户,且每个用户在数据集中可以有多条数据,根据用户使用浏览器访问搜索引擎时的 Cookie 信息自动赋值,即同一次使用浏览器输入的,不同查询对应同一个用户 ID;搜索关键词为用户在浏览器搜索栏中输入的字符,可以为几个单词,也可以为一个句子等;网页排名指网页在浏览器搜索结果中的排序;点击次序记录用户点击该页面的次序。
数据的前期处理对于数据分析来说至关重要。这里我使用Python对500w行数据进行了处理,具体处理内容有(1)处理不符合规范数据;(2)时间分段。
1.1处理不符合规范的数据。
具体来说,不符合规范的数据具有如下特点中的一个或者多个:字段为空、字段中的数据无效、一条记录中的TAB键个数不为5等。通过对于1w条搜狗搜索日志的查看发现,数据集较为规整,不符合规范的数据数目较少。又因为我们拥有数量庞大的数据集,所以在这里对于不符合规范的数据不进行修正处理,而是直接舍弃。
Python十分适合于数据的处理,仅需几行代码就可以实现我们的需求。处理程序的主要逻辑为: 1 æå¼æ°æ®éæä»¶ï¼ 2 å½æ°æ®éä¸ä¸ºç©ºæ¶ï¼è¯»åä¸æ¡æ°æ®ï¼å½æ°æ®é为空æ¶ï¼ç¨åºç»æï¼ 3 æ£æ¥è¯¥æ¡æ°æ®æ¯å¦ç¬¦åè§èï¼è¥ç¬¦åè§èï¼æ§è¡æ¥éª¤ 4 ï¼è¥ä¸ç¬¦åè§èï¼æ§è¡æ¥éª¤ 5 ï¼ 4 å°è¯¥æ¡æ°æ®åå ¥ç»æéï¼æ§è¡æ¥éª¤ 2 ï¼ 5 èå¼è¯¥æ°æ®ï¼æ§è¡æ¥éª¤ 2 。用流程图可以表示为图1.1,实现代码见代码(1)。经过执行发现该数据集中并没有不符合规范的数据。
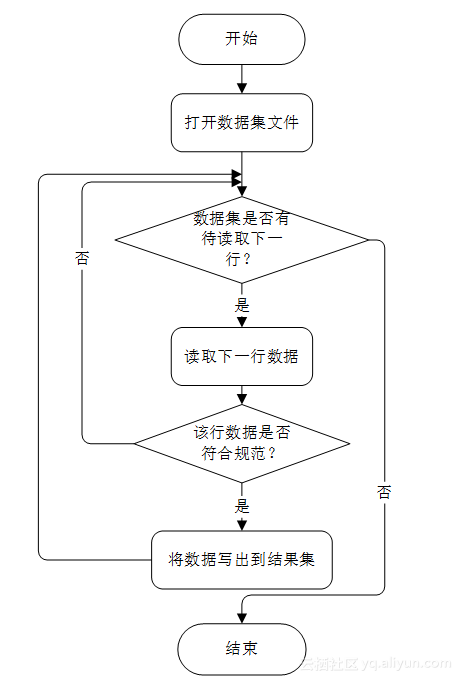
图1.1 处理数据程序流程图
1.2访问时间分段。
后续再hive中对数据进行分析时,需要对时间以小时为单位进行分析,而原始数据集中时间的格式为:20111230095200,即年月日小时分钟秒,我们将其分割为:201112 30 09 5200的形式,其中字段之间用TAB键分隔。处理程序比较简单,其主要逻辑为: 1 æå¼ä¸è¿°æ¥éª¤çç»ææ°æ®éæä»¶ï¼ 2 å½æ°æ®éä¸ä¸ºç©ºæ¶ï¼è¯»åä¸æ¡æ°æ®ï¼å½æ°æ®é为空æ¶ï¼ç¨åºç»æï¼ 3 将该行数据的对应位置插入TAB键,输出到时间分段结果集文件。实现代码见代码(2),结果如图1.2所示:
图1.2 时间分段处理结果
二、基本统计信息
想要使用hive分析搜狗搜索数据,首先要在hive数据库建立数据集对应的表。这里我们首先将数据集传到HDFS上,如语句(1)所示;然后创建一个搜狗数据分析专用的数据集,如语句(2)所示;然后再该数据集中创建搜狗搜索数据表,如语句(3)所示。
通过以上步骤建立了一个可供查询的搜狗搜索数据集sougoudata,对该表的基本信息进行统计。(1)sougoudata表中的总数据条数有500w条,可使用语句(4)查询。(2)sougoudata表中每个字段都非空的记录的条数为500w条,用语句(5)查询。
三、数据属性基础分析
在sougoudata表中每一行都有六个字段,下面我们针对这些字段做一些分析。
3.1用户ID分析
在该数据集中共有1352664个独立UID,即有1352664个用户,其中每个用户平均查询3.696409次,使用语句(6),语句(7)查询。对于UID我们进行两方面的分析:UID的查询次数、UID频度排名分析。
3.1.1UID的查询次数。
一方面,通过查询可以得到查询次数与用户人数分布情况,查询次数从1~14,用户人数的结果数据为:549148,257163,149562,96221,66167,47649,35337,26931,21013,16451,13385,10717,9013,7301,该数据可由语句(8)得到。如图3.1所示,图中可以看出用户人数虽查询次数的增大而减小,用户查询次数主要集中在一次、两次、三次;图3.2可以很好的反应查询次数与用户人数之间的比例关系,查询次数为1的用户占据总人数的44%,查询次数为2的用户占据总人数的20%,查询次数为3的用户占据总人数的11%。通过以上统计数据可以看出大多数用户对于搜索引擎的使用次数很低,这也可以说明该引擎的用户使用频度不高,用户依赖性可能较差。
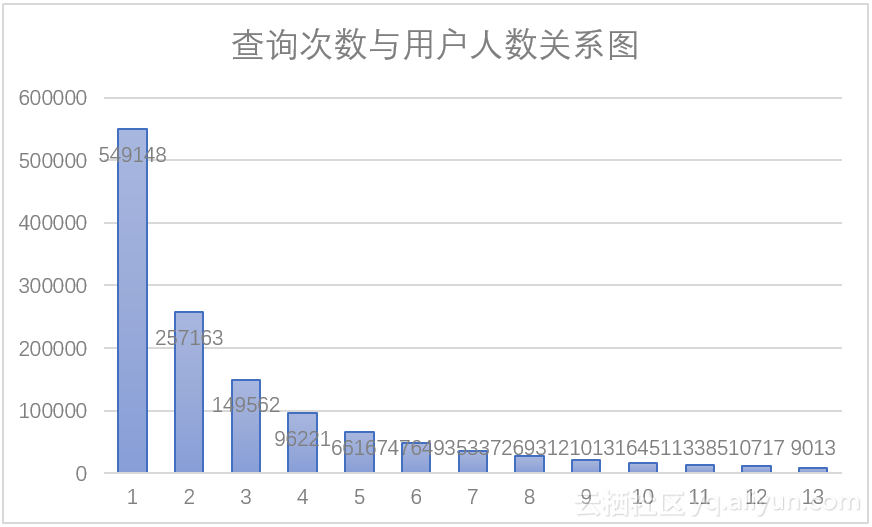
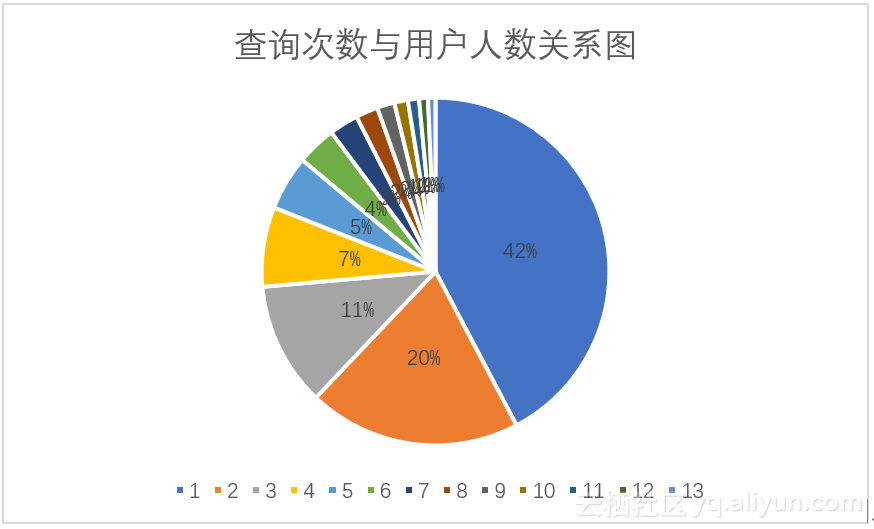
图3.1 查询次数与用户人数柱状图 图3.2 查询次数与用户人数饼形图
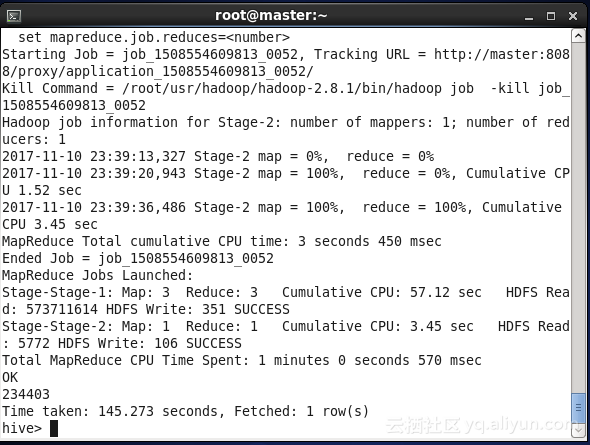
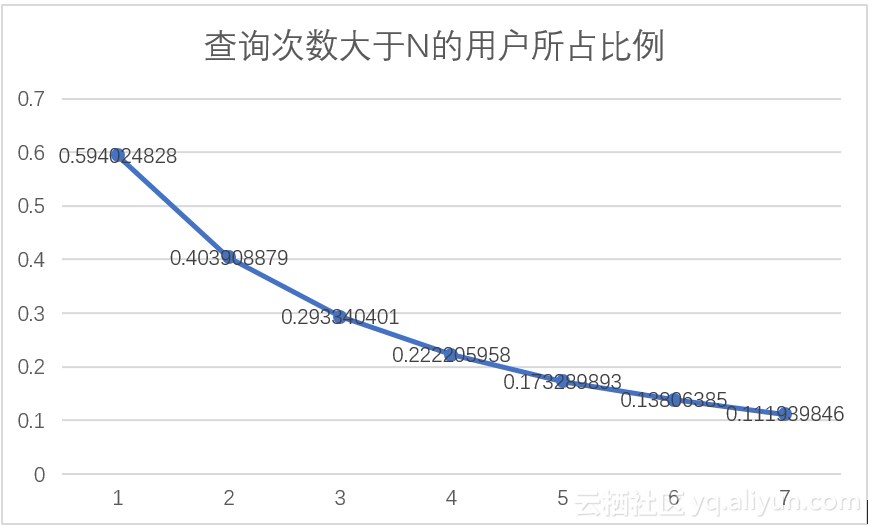
另一方面,通过语句(9)的查询,可以得到查询次数大于1,2,3,4……次的用户的数据,其结果如表3.1所示,查询语句执行截图如图3.3所示。将表中数据用折线图表示,如图3.4所示,可以发现,查询次数大于N次中,N的数值越大,用户数越少;随着N值的增大,折线的斜率逐渐减小。由此,我们得出这样的推论,查询次数大于N的用户随着N值的增加逐渐稳定。
表3.1 查询次数大于N的用户表
| 查询次数大于N次 |
用户数 |
| 1 |
803516 |
| 2 |
546353 |
| 3 |
396791 |
| 4 |
300570 |
| 5 |
234403 |
| 6 |
186754 |
| 7 |
151417 |
 Â
Â
图3.3 语句执行截图 图3.4 查询次数大于N的用户折线图
3.1.2UID频度排名分析。
对UID依据频度进行排名可以得到使用引擎次数最多的用户的信息,这里我们使用语句(10)查询得到结果,其中排名前10的UID如表3.2所示。其中,排名为1的UID:02a8557754445a9b1b22a37b40d6db38在一天之内使用了11528次搜狗浏览器,是排名为2的UID的5倍,平均每7秒发送一条查询信息,这明显是不正常的,这里我怀疑该用户可能是爬虫程序,在后续数据深入分析中我将进一步研究该用户的行为。
表3.2 UID频度排名表
| UID |
频度 |
| 02a8557754445a9b1b22a37b40d6db38 |
11528 |
| cc7063efc64510c20bcdd604e12a3b26 |
2571 |
| 9faa09e57c277063e6eb70d178df8529 |
2226 |
| 7a28a70fe4aaff6c35f8517613fb5c67 |
1292 |
| b1e371de5729cdda9270b7ad09484c4f |
1277 |
| c72ce1164bcd263ba1f69292abdfdf7c |
1120 |
| 2e89e70371147e04dd04d498081b9f61 |
837 |
| 06c7d0a3e459cab90acab6996b9d6bed |
720 |
| beb8a029d374d9599e987ede4cf31111 |
676 |
| b3c94c37fb154d46c30a360c7941ff7e |
676 |
3.2搜索关键词分析
关键词是用户提供给搜索引擎,搜索引擎返回页面的依据。对于关键字的分析可以很好的了解用户群体的关注点,以及用户的搜索行为特点等。
3.2.1热词分析
一方面,我们对用户的关注点进行分析,即分析热词。通过语句(11)可以将关键字按照频度排序,查询结果如表3.3所示,这里我们只取频度最高的10个关键词。在频度最高的10个词中,与百度公司有关的有三个,且占据排名前两位,根据经验做一点不成熟的推断:百度是一个搜索中转站,当用户想要搜索网页时,通常会先进入百度,然后使百度搜索自己想要的内容,这说明百度公司在搜索行业的分量很重,用户对于百度搜索返回的结果认同度较高。另外,从关键词所属的类别我们可以看出:游戏、社交、视频、新闻是用户搜索的主要目的。
表3.3 关键字频度表
| 关键词 |
频度 |
| 百度 |
38441 |
| baidu |
18312 |
| 人体艺术 |
14475 |
| 4399小游戏 |
11438 |
| qq空间 |
10317 |
| 优酷 |
10158 |
| 新亮剑 |
9654 |
| 馆陶县县长闫宁的父亲 |
9127 |
| 公安卖萌 |
8192 |
| 百度一下 你就知道 |
7505 |
另一方面,通过关键词,我们对用户的搜索行为特点进行分析。这里用户的搜索行为特征分为两种:使用几个单词还是一个句子作为关键词;使用文字描述还是域名一部分作为关键词。
3.2.2使用几个单词还是一个句子作为关键词。
用户搜索关键词时,主要有两种方式: 使用几个单词作为关键词,直接使用一个句子作为关键词。表现在数据集中,几个单词作为关键词时,keyword字段中存在空格;一个句子作为关键词时,kayword字段中不存在空格,所以我们以空格为标志判断一条记录的搜索方式,使用语句(12)查询可得两种搜索方式的频度表,如表3.4所示,为了更直观的观察数据特征,绘制条形图,如图3.5所示。通常来说,使用几个单词作为关键词更有利与搜索引擎返回精确的结果,但是通过图表我们发现,绝大多数用户习惯使用一个句子作为搜索关键词,基于这种情况,搜索引擎公司应该注重自己在分词方面的技术能力。
表3.4 多个单词与一个句子搜索方式频度表
| 搜索方式 |
频度 |
| 几个单词 |
327953 |
| 一个句子 |
4672047 |
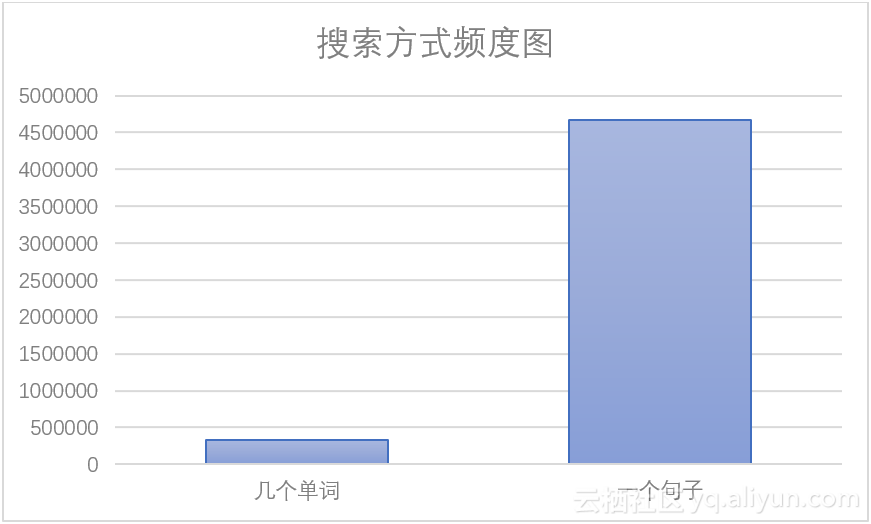
图3.5 搜索方式频度图
3.2.3使用文字描述还是域名一部分作为关键词。
如果关键词中包含“www”,那么我们就认为用户使用域名的一部分作为关键词,否则我们认为用户使用文字描诉作为域名,使用语句(13)可以得到关键词内容类别数据,如表3.5所示,为了更直观的观察数据特征,绘制饼形图,如图3.6所示。从图表中我们可以清楚的看出以以域名部分作为关键词的搜索记录占很小的一部分,大多数用户是使用文字描述的方式来寻找网页的。但是当用户提交含有域名的查询时,大概是因为没有记全网址,想要借助搜索引擎来找到目标网页,因此搜索引擎在处理这部分查询时,一个较为理想的方式是首先把完整的域名返回给用户,这样有较大可能符合用户的查询要求。
表3.5关键词内容类别频度表
| 关键词内容 |
频数 |
| 域名部分 |
27561 |
| 文字描述 |
4972439 |
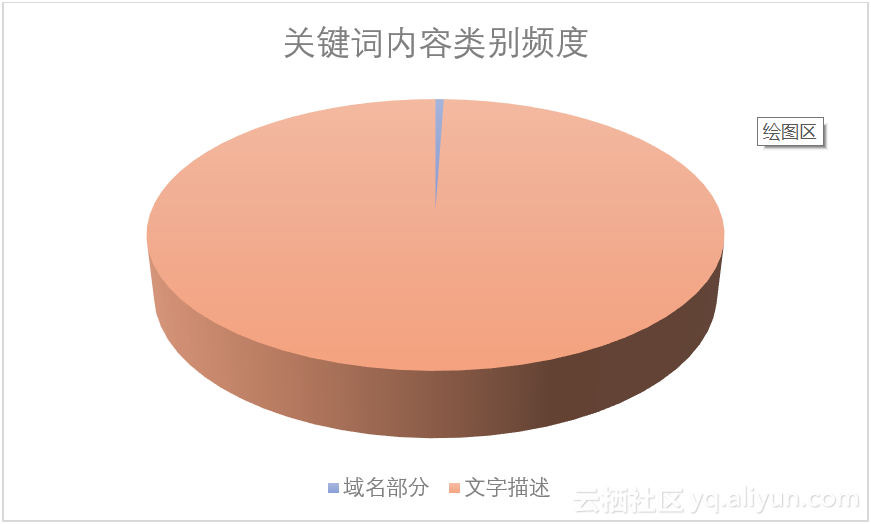
图3.6关键词内容类别频数饼形图
3.3URL分析
URL是用户搜索页面后真正点进去浏览器的页面的域名,在本数据集中共有2466932个URL,平均每个网页被访问2.0268次。对于URL的分析主要从两方面入手:热门搜索分析,URL流量分析。
3.3.1热门搜索分析。
通过语句(14)我们可以得到URL的频数排名结果集,将排名前十的URL及频数如表1所示。从表中我们可以看到百度公司的网站有两个:http://www.baidu.com/、http://www.hao123.com/,且占据排名第一和第三的位置,这与前十个热门关键词中百度公司占据三个的结果相符合,百度公司搜索领域龙头的位置当仁不让;这十个网址中有四个网址:http://www.4399.com/、 http://www.7k7k.com/、http://cf.qq.com/、http://www.xixiwg.com/都是游戏网站,可以看出游戏在用户中比较热门;另外表中还有两个社交相关网站: http://qzone.qq.com/、 http://weibo.com/。将表3.6中数据用饼形图表示可以看出,除http://www.baidu.com/占有较大比重外,其他9个URL基本平分秋色。
表3.6 排名前十的URL及频数表
| URL |
频数 |
| http://www.baidu.com/ |
73737 |
| http://www.4399.com/ |
19015 |
| http://www.hao123.com/ |
14338 |
| http://www.youku.com/ |
14086 |
| http://qzone.qq.com/ |
12920 |
| http://www.7k7k.com/ |
8326 |
| http://weibo.com/ |
7547 |
| http://cf.qq.com/ |
7544 |
| http://www.xixiwg.com/ |
7043 |
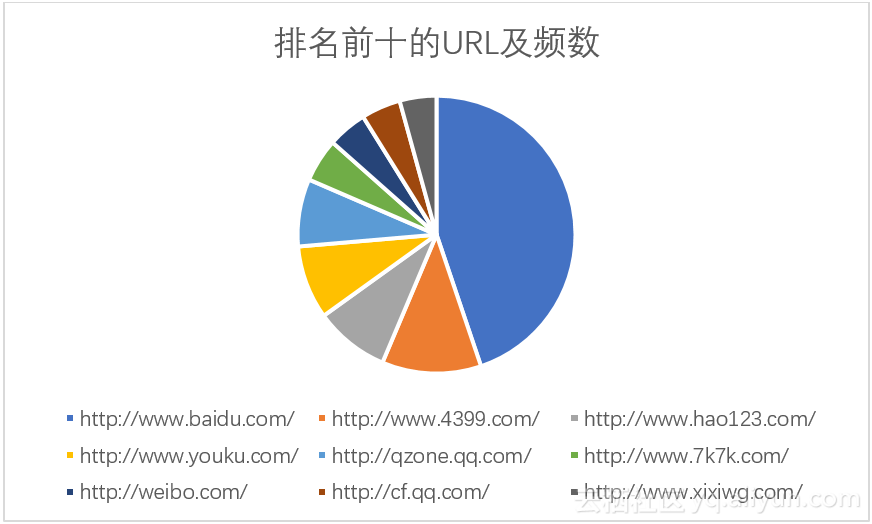
图3.7 排名前十的URL及频数饼形图
3.3.2URL流量分析。
我们通常说的网站流量是指网站的访问量,是用来描述访问一个网站的用户数量以及用户所浏览的网页数量等指标,这里我们使用URL频数的数值衡量域名流量。为了了解2466932个URL中的流量分布情况,我们使用语句(15)查询各个排名段的频数数据,见表3.7按频数排序在1w名以内的URL的总数据量为153463条,占整个数据集的30.7%。使用折线图表示表中数如图3.8所示,我们可以发现折线图中1~10000与10001~20000之间的斜率特别大,这说明排名在1~10000之间的URL的少部分URL占据了大多数的流量。
表3.7 URL排名区间与频数表
| URL排名区间 |
频数 |
| 1~10000 |
1536463 |
| 10001~20000 |
231120 |
| 20001~30000 |
151432 |
| 30001~40000 |
117753 |
| 40001~50000 |
97615 |
| 50001~60000 |
85820 |
| 60001~70000 |
77972 |
图3.8 URL排名区间与频数图
3.4 Rank分析
在该数据集的记录中,记录所对应的网址在搜索页面的排名Rank的平均数为:2.94353565077939,可由语句(16)查询。则每个关键字平均被查询了3.35次,这与每个用户平均搜索3.69次的数据格外相似。
对Rank排名频度进行查询,使用语句(17),这里我们按频度排名取排名前10的Rank,结果如表3.8,通过计算Rank与频度的相关系数为-0.73579,即Rank越小,其频度越大,则我们有理由相信一个网页在搜索结果中的排名可以决定该网页的流量,这大概也就是百度竞价排名备受商业集体网站追捧的原因吧。为了直观的了解结果数据,可以使用图3.9来表示结果,在图中我们可以看到在Rank排名前10名中,排名为1,2,3的网页占据的绝大多数流量,其中排名为1的网页甚至可以拿到接近50%的频度;从图3.10可以看出,排名靠后流量递减,且递减趋势逐渐缓慢,这又一次验证了网页排名顺序的重要性。
表3.8 Rank与频度排名表
| Rank |
频度 |
| 1 |
2071720 |
| 2 |
905769 |
| 3 |
554258 |
| 4 |
375813 |
| 5 |
283848 |
| 6 |
218351 |
| 7 |
179380 |
| 8 |
151384 |
| 10 |
131002 |
| 9 |
128344 |
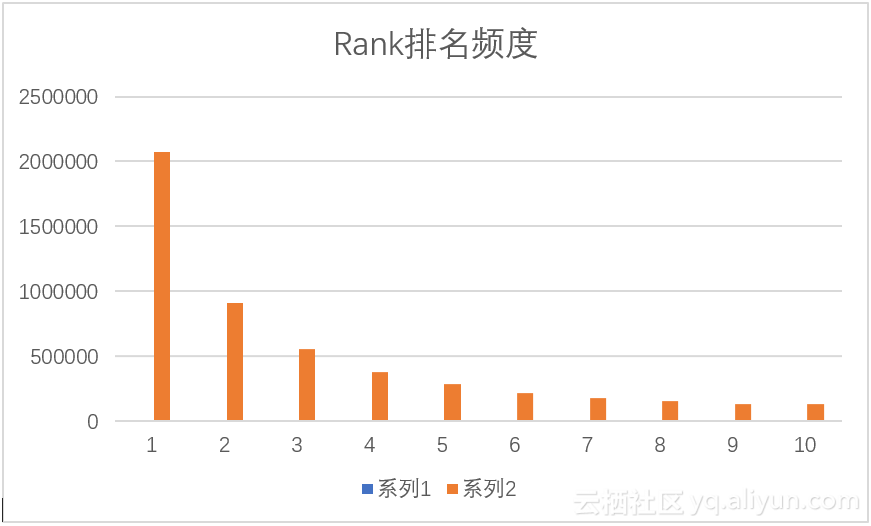
图3.9 Rank排名频度条形图
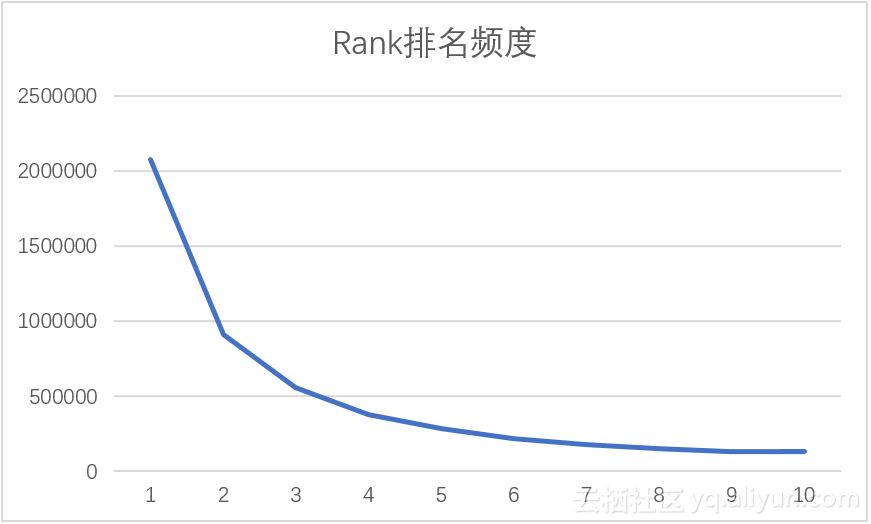
图3.10 Rank排名频度折线图
3.5 Order分析
Order是用户点击的顺序号,可以反应用户找到目标网页的难易程度:当Order的平均值较大时时,用户寻找目的网页需要经过更多的点击;当Order值较小时,用户可以较为容易的找到目标网址。本数据集中Order的平均值为: 1.525254,最大值为10,可以看出搜狗搜索算法返回的页面比较符合用户的需求,由语句(18)可得。此外,我们分析Order的频数,由语句(18)可以到Order频数排名表,如表3.9所示,频数随Order的增大而递减,其相关系数为-0.67531,我们有理由相信频数与Order之间负相关。为了更直观的观察数据特定,我们将表中数据绘制成为饼形图,如图3.11所示。在图1中我们看到频度随Order迅速下降,其中Order为1的记录的数量占据数据集68%以上。
表3.9 Order频数排名表
| Order |
频数 |
| 1 |
3465833 |
| 2 |
912017 |
| 3 |
355093 |
| 4 |
150291 |
| 5 |
65530 |
| 6 |
29253 |
| 7 |
13068 |
| 8 |
5731 |
| 9 |
2372 |
| 10 |
812 |
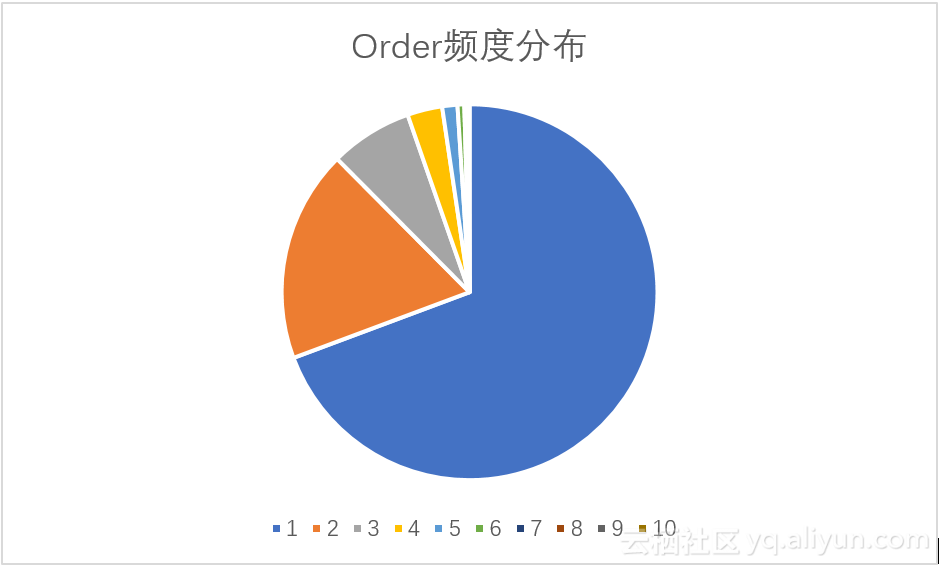
图 3.11 Order频数分布图
3.6访问时间分析
本数据集的访问时间主要分部在2012年12月30日这一天,也有少部分2012年12月31日的数据。我们使用经过时间分段处理的数据进行建表,如语句(19)。这里我们对不同时间段内的记录数进行分析,我们将数据集按照时间间隔1小时进行统计,使用语句(20),数据如条形图3.12所示。由图中我们可以看出,全天主要有三个访问高峰期:9~11时,14~16时,19~21时,这三个时间段正是人们主要的工作娱乐时间;一个访问大低谷时段:0~7时,这段时间正是人们的休息时间;此外,我们注意到11~13时,17~18时与相邻时段相比也出现了数据量下降的情况,这两个时间段正好是人们吃饭的时间。
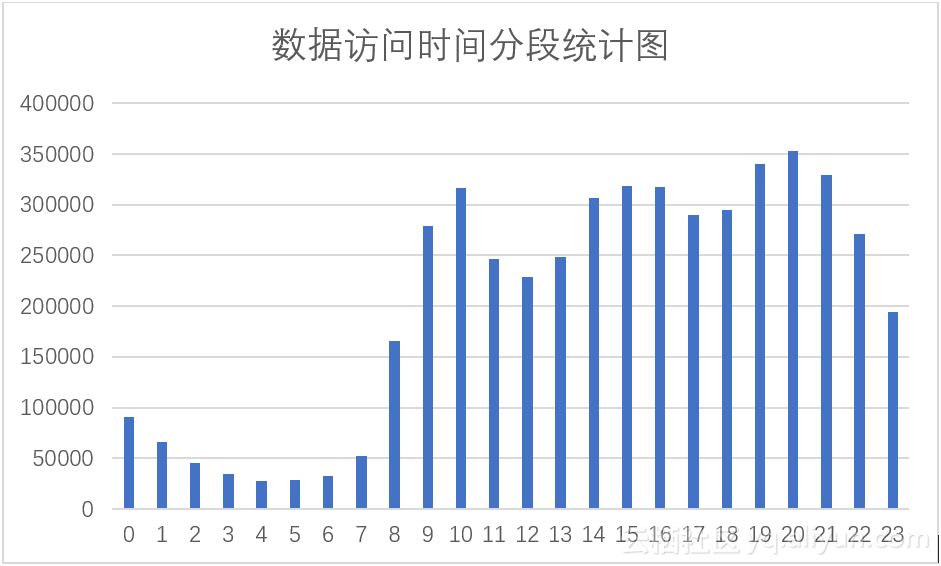
图3.12 数据访问时间分段统计图
四、数据深入特色分析
4.1.某一用户分析
在前面对于用户的分析中,我们发现了一个反常用户,该用户在数据集中频数排名第一,且频数为第二名的5倍。针对这种现象,我决定对其进行分析。使用语句(21)在hive中建立UID为02a8557754445a9b1b22a37b40d6db38的数据的表。该数据集中有11528条属于该用户的数据,其访问的独立网页有8542个,不重复关键词有5381个。
4.1.1该UID背后是否是爬虫程序?
该用户全天24小时平均每7秒就访问一个页面,这样的访问速度绝非一个用户通过点击浏览器就可以完成,所以我初步怀疑这个该UID是一个网络爬虫,它在爬取数据。
由于网络爬虫一般来说都是为了爬取某以特定领域的数据而执行,所以为了验证我的想法,我统计了该UID访问的关键词,并将其排序,使用语句(19)查询,表4.1是统计结果,这里仅展示排名前十数据。从表中我们看出该UID查询的关键词范围相当广泛,且内容较为低俗。
表4.1 特殊UID的关键词频率表
| 关键词 |
频数 |
| 幼交小说 |
41 |
| 我和草原有个约定广场舞 |
37 |
| 伦理快播 |
36 |
| 遮天 |
29 |
| 保险公司的内勤都是靠关系才能进的吗 |
28 |
| 联想u260 二手 |
25 |
| 新亮剑 |
23 |
| 人体艺术 |
21 |
| qq头像 |
20 |
| 百度 |
18 |
此外,我对该UID对同一个关键词的查询次数进行了统计。使用语句(20)查询,可以得到该UID查询一次的关键词、查询两次的关键词、查询三次的关键词、查询三次以上的关键词,统计数据如图4.1所示。在饼形图中查询次数为1的关键词占据大部分,随查询次数增加,关键词数量呈下降趋势,这样的结论跟爬虫程序所体现出的规律性相违背。
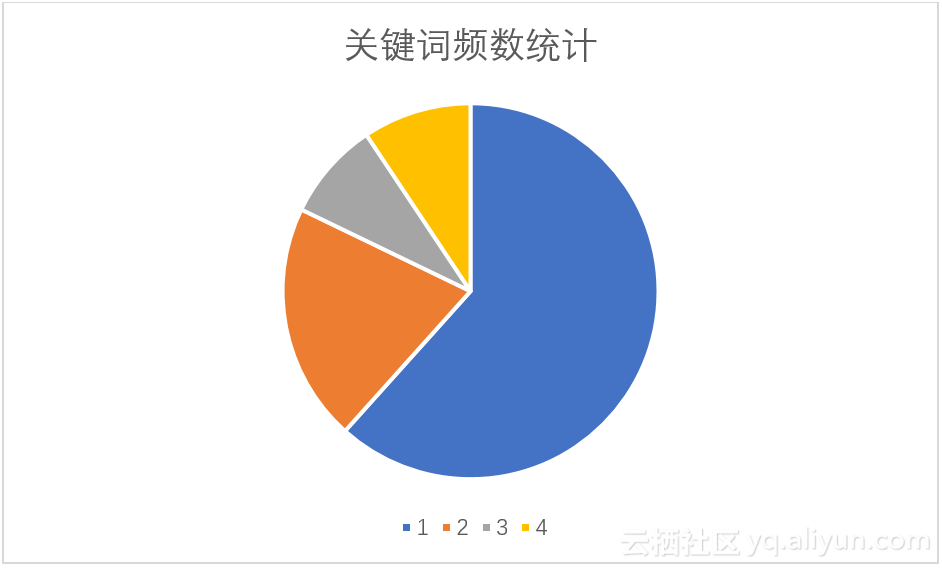
图4.1 关键词频数统计图
基于以上两组数据的分析,我们非常遗憾的可以肯定这不是爬虫程序。
4.1.2该UID背后是浏览器代理程序吗?
虽然该UID背后不是一个爬虫程序,但是其巨大的访问量还是值得怀疑的。我了解到,数据集中的数据,UID 是根据用户使用浏览器访问搜索引擎时的 Cookie 信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID。这样看来,本UID背后也有可能是很多拥有相同Cookie的用户。能够拥有相同的Cookie,可能是因为用户通过一个代理的浏览器程序调用搜狗浏览器的接口。如果猜测正确,那么该UID的数据分析应该与整体数据集呈现出一定的相似性。
为了验证这一点,我对该UID在不同时间段内的数据频数进行了统计,使用语句(21)进行查询,将得到的数据展示在条形图中如图4.2所示,我们发现该图与整体数据的数据访问时间分段统计图图3.12有一定的相似性,两张图在凌晨时分均数据较少,在下午时段均有高峰,通过计算其数据相关性为:0.843714,此相关性较高,则该UID背后。但是我们也注意到,该图与图1也有一些不同之处,该图时间为12时数据为0。
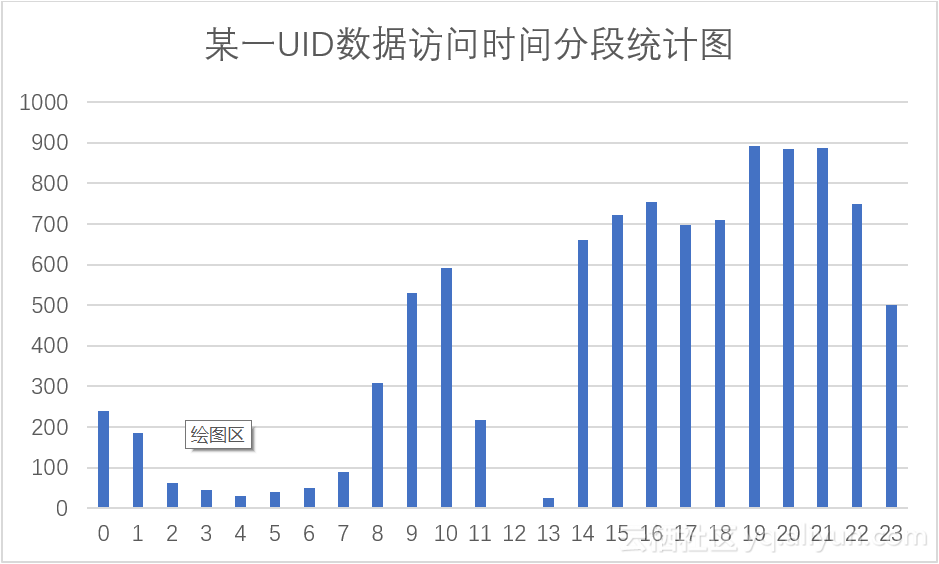
图4.2 该UID数据访问时间分段统计图
为了进一步提高猜测的可靠性,现在我们对12时这个特殊点的数据进行分析。我们发现不仅12时这个点数据比较异常,11时,13时的数据也是格外低。鉴于此时间为午餐时间,我有一个大胆的猜测,该UID背后有可能是一个11:30~2:00午休的单位,但是该UID在凌晨也有数据访问,且晚餐时间并没有显示出与午餐时间相同的数据情况,这点比较存疑。我们到数据中去寻找答案,使用语句(22)进行查询可得11时的数据及13时数据,如图4.3,图4.4所示。在查询出的数据中我发现11点时间段中,11点20分以后一条访问数据都没有;13点时间段中,13点57分之前一条访问数据都没有。这样,我们可以精确的得到,该UID在数据集中没有相关访问数据的时间段为:11:20~13:57分。这种情况我只能想到是服务宕机了!我们将11,12,13这三个时间段除去,然后再计算该UID的数据访问时间分布于整体数据访问时间分布的相关性,可以得到现在两者的相关性达到了0.97785,我们有理由相信,该UID数据是可以近似为一个小规模的数据集数据,这使得该UID背后是一个浏览器代理程序的可能更大。

 Â Â
 Â
图4.3 11时访问数据 图4.4 13时访问数据
综合以上分析,我们有一定的把握可以说该UID的背后是一个浏览器代理程序。
4.2.某一网站分析
这里我们选择http://weibo.com/进行分析,该网站属于新浪微博,使用语句(23)在hive中建表,在该表中共有7547条记录,访问该网站的独立UID有5286个,该网站通过126个关键词被找到。
4.2.1关键字分析
我们使用语句(24)可以查询该网站数据对应的所有关键字,并将其使用树形图表示,如图4.5所示。从图中我们可以看到关键字:新浪微博、微博、weibo占整个网站访问量的绝大多数,用户更喜欢用这三个词来找到微博网站。
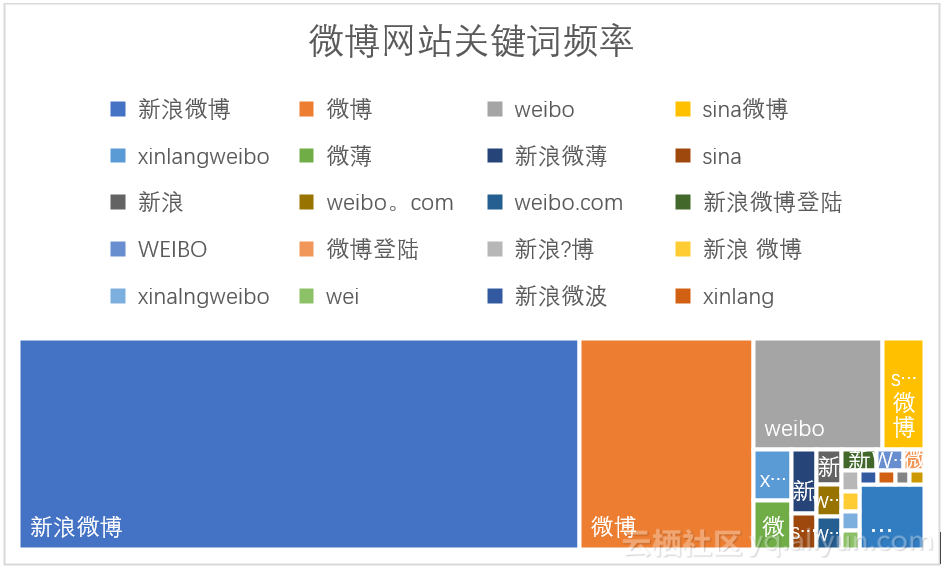
图4.5 微博网站关键词频率图
我们对该网站的Rank进行分析,Rank值越低说明http://weibo.com/网站在浏览器中显示越靠前,越有利于吸引流量,使用语句(25)可以计算该网页的平均Rank值为1.0838323353293413,整个数据集的平均Rank的是该网站平均Rank的3倍。这说明http://weibo.com/网站频数最高的关键词的Rank数很低,我们来验证一下,使用语句(25)可以得到http://weibo.com/网站频率排名前五的关键词的Rank平均值,数据统计见表4.1所示。表中排名前五的关键词的平均Rank值均为1。
表4.1 频率排名前五的关键词的Rank值
| 关键词 |
Rank平均 |
| 新浪微博 |
1 |
| 微博 |
1 |
| |
1 |
| sina微博 |
1 |
| xinlangweibo |
1 |
4.2.2访问量与时间
微博是一个典型的社交网站,通过对微博网站访问量与时间关系的分析,可以见微知著的了解人们社交的时间规律。我们使用语句(26)进行查询可以得到各个时间段内该网站的数据频数,将数据使用图4.6表示,从图中我们凌晨时访问量最低,该图与整体数据访问量与时间图具有一定相似度。但是我们发现12时的数据量大于11时和14时,而整体数据集无此特征,这说明有些用户喜欢在午餐及午餐后刷微博。
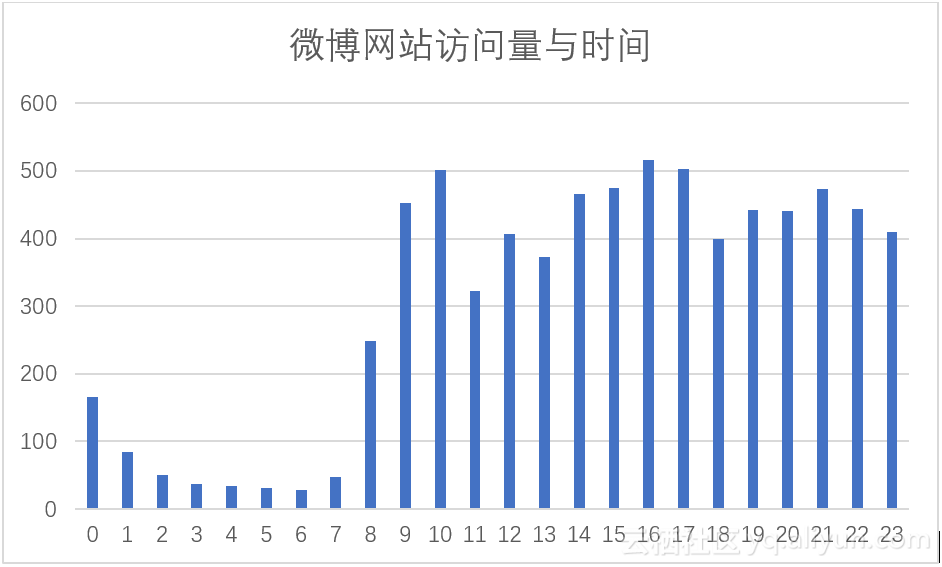
图4.6 微博网站访问量与时

