目录
一、作业一:星型模型及缓慢变化维
1.1 问题一:基本星型模型
对于问题一中建立星型模型所满足的要求:(1)公司每个员工每月的薪资分别是多少?(2)哪些部门每个月开出的薪资比较高?(3)哪种职称的每月得到的薪资比较高?我们对需求语义进行分析可知:事实表中的度量有:工资,时间;维度有:员工信息、部门信息、职称信息。
通过以上分析,我们通过数据库设计工具进行制图,在星形模型中,无论是事实表还是维度表都需要一个SK,这个SK通常为int类型;并将原本表中的主键变为NK;此外,事实表与维度表通过外键关联。我们设计的星形模型如图1.1所示。
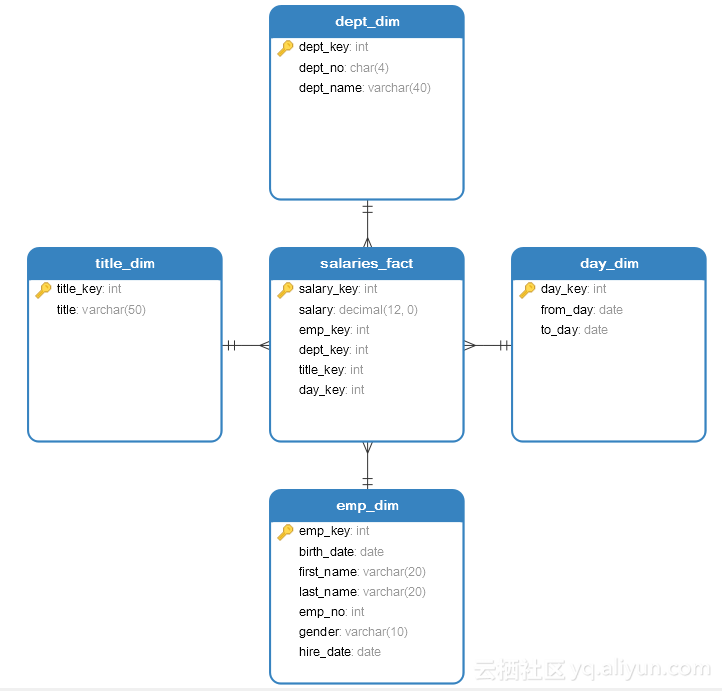
图1.1 问题一星形模型
其中salaries_fact是事实表,title_dim、emp_dim、dept_dim、day_dim是维度表,表title_dim的字段定义如表1.1所示,表emp_dim的字段定义如表1.2所示,表dept_dim的字段定义如表1.3所示,表day_dim的字段定义如表1.4所示,表salaries_fact的字段定义如表1.4所示。
表1.1 title_dim表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| title_key |
int |
11 |
是 |
| title |
varchar |
50 |
否 |
表1.2 emp_dim表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| emp_key |
int |
11 |
是 |
| birth_day |
date |
|
否 |
| first_name |
varchar |
20 |
否 |
| last_name |
varchar |
20 |
否 |
| emp_no |
int |
11 |
否 |
| gender |
varchar |
10 |
否 |
| hire_date |
date |
|
否 |
表1.3 dept_dim表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| dept_key |
int |
11 |
是 |
| dept_no |
varchar |
4 |
否 |
| dept_name |
varchar |
40 |
否 |
表1.4 day_dim表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| day_key |
int |
11 |
是 |
| from_day |
date |
|
否 |
| to_day |
date |
|
否 |
表1.5 salaries_fact表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| salary_key |
int |
11 |
是 |
| salary |
int |
11 |
否 |
| emp_key |
int |
11 |
否 |
| dept_key |
int |
11 |
否 |
| fitle_key |
int |
11 |
否 |
| day_key |
int |
11 |
否 |
1.2 问题二:增加缓慢变化维的星型模型
对于问题二中所增加的需求:(1)我们需要根据以前部门的名称统计名称改变以前的薪水情况;(2)同时,需要根据现在部门的名称统计整个部门历史的薪水情况。我们可以在问题一所建立的星形模型上进行修改得到,将department_dimension表中的dept_name做成一个混合类型的缓慢变化维类型即可。
通过以上分析,我们将dept_name属性变为两个属性dept_name_current和dept_name-history。其中,dept_name_current属性存储当前部门名称,dept_name-history存储历史部门名称。如图1.2所示。
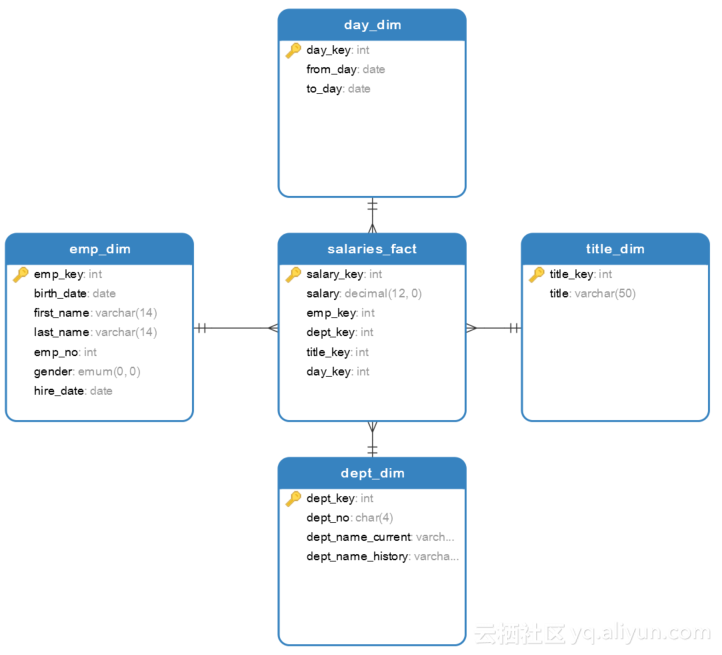
图1.2 问题二星形模型
相对于图1.1,图1.2中仅dept_dim表进行了修改,修改后的dept_dim表字段定义如表1.6所示。
表1.6 增加缓慢变化维的dept_dim表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| dept_key |
int |
11 |
是 |
| dept_no |
varchar |
4 |
否 |
| dept_name_current |
varchar |
40 |
否 |
| dept_name_history |
varchar |
40 |
否 |
二、作业二:导出表和多值维度问题
2.1 问题一:导出表
对于问题一中提出的要求:如果想要了解每位员工的年薪情况,但是又觉得在OLAP中查询的速度比较慢,应该怎样解决这一问题?我们可以使用导出表的形式来提升查询速度,其中聚集表的粒度为年薪。在第一次作业的基础上我们设计事实表:salaries_fact表;维度表:title_dim、emp_dim、dept_dim、year_dim。通过以上分析我们使用数据库设计工具进行设计,如图2.1所示。
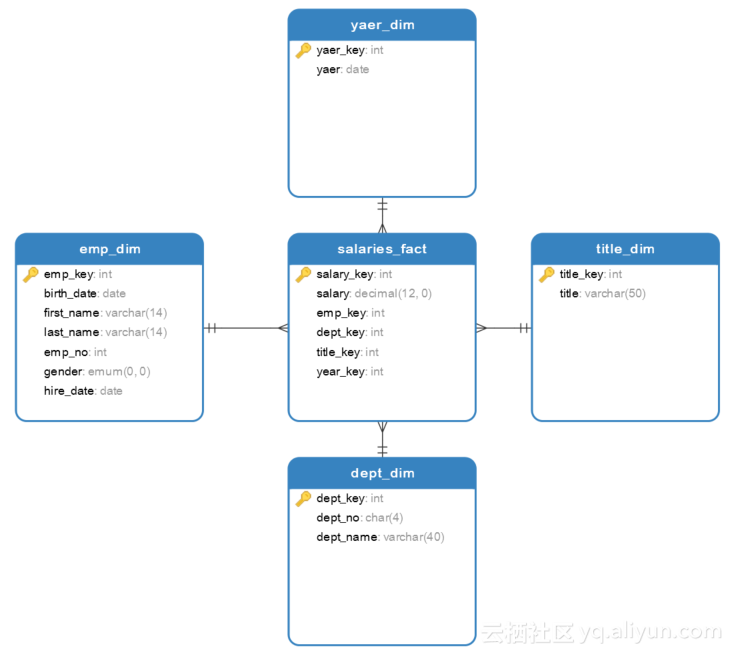
图2.1 问题一导出表
相对于图1.1,图2.1中新增了表year_dim,修改了表salaries_fact。其中表year_dim的字段定义如表2.1所示,表salaries_fact的字段定义如表2.2所示。
表2.1 year_dim表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| year_key |
int |
11 |
是 |
| year |
date |
|
否 |
表2.2 salaries_fact表字段定义
| 名 |
类型 |
长度 |
是否为主键 |
| salary_key |
int |
11 |
是 |
| salary |
int |
11 |
否 |
| emp_key |
int |
11 |
否 |
| dept_key |
int |
11 |
否 |
| fitle_key |
int |
11 |
否 |
| year_key |
int |
11 |
否 |
2.2 问题二:多值维度问题
对于问题二中提出的要求:如果公司管理层需要了解每位员工在公司的各部门中的变动情况,即员工什么时候来到公司,在哪些岗位工作了多长时间,现在在什么岗位工作。应该建立什么样的模型来满足要求?关键点在与解决一个多值维度问题。这里,我们使用桥接表+主表的方式解决。
这里我们设计事实表emp_fact,在查询时该表的信息通过桥接表msgGroup_dim提供。msgGroup_dim表与msgGroupMenberShip_dim表相连接。msgGroupMenberShip_dim表拥有msg_title_dim、msg_department_dim、msg_date_dim表的外键。如图2.2所示。
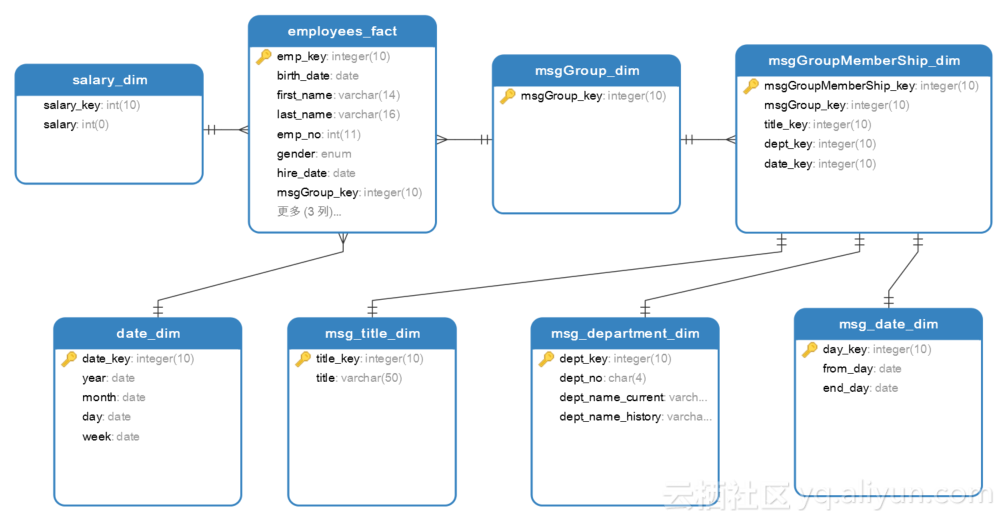
图2.2 多值维度问题解决
其中employees_fact是事实表,其表结构如表2.3所示,salary_dim,date_dim, msgGroup_dim,msgGroupMemberShip_dim,msg_title_dim,msg_department_dim,msg_date_dim是维度表。salary_dim表字段结构如图2.4所示,date_dim表字段结构如图2.5所示,msgGroup_dim表字段结构如图2.6所示,msgGroupMemberShip_dim表字段结构如图2.7所示,msg_title_dim表字段结构如图2.8所示,msg_department_dim表字段结构如图2.9所示,msg_date_dim表字段结构如图2.10所示。
表2.3 employees_fact字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| emp_key |
int |
11 |
是 |
| birth_date |
date |
|
否 |
| first_name |
varchar |
14 |
否 |
| last_name |
varchar |
14 |
否 |
| emp_no |
int |
11 |
否 |
| gender |
enum |
|
否 |
| hire_date |
date |
|
否 |
| msgGroup_key |
int |
11 |
否 |
| date_key |
int |
11 |
否 |
| salary_key |
int |
11 |
否 |
表2.4 salary_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| salary_key |
int |
11 |
是 |
| salary |
int |
10 |
否 |
表2.5 date_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| date_key |
int |
11 |
是 |
| year |
date |
|
否 |
| month |
date |
|
否 |
| day |
date |
|
否 |
| week |
date |
|
否 |
表2.6 msgGroup_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| msgGroup_key |
int |
11 |
是 |
表2.7 msgGroupMemberShip_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| msgGroupMemberShip _key |
int |
11 |
是 |
| msgGroup_key |
int |
11 |
否 |
| msg_title_key |
int |
11 |
否 |
| msg_dept_key |
int |
11 |
否 |
| msg_date_key |
int |
11 |
否 |
表2.8 msg_title_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| title_key |
int |
11 |
是 |
| title |
varchar |
50 |
否 |
表2.9 msg_department_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| dept_key |
int |
11 |
是 |
| dept_no |
varchar |
11 |
否 |
| dept_name_current |
varchar |
50 |
否 |
| dept_name_history |
varchar |
50 |
否 |
表2.10 msg_date_dim字段结构表
| 名 |
类型 |
长度 |
是否为主键 |
| date_key |
int |
11 |
是 |
| from_day |
date |
11 |
否 |
| end_day |
date |
50 |
否 |
三、作业三:维度表的抽取
针对作业任务中提出的需求: 将样例数据库中的数据经过ETL过程装载到数据仓库中,主要是完成维度表格的装载,我们可以使用SQL Server的Integration Service项目进行数据的抽取与转换。根据前两次作业中对于数据仓库的设计,我们这里需要抽取的维度表有 day_dim、dept_dim、employees_dim、titles_dim四个。这里,我们在数据源部分使用SQL语句进行抽取,在数据目标部分使用表或视图的映射。下面我们依次对他们进行抽取。
3.1 一些准备工作
首先,我们将以上模型使用SQL语句在SqlServer数据库中建表,使用的SQL语句如下:
CREATE TABLE [day_dim] (
[day_key] int NOT NULL IDENTITY(1,1),[from_day] date NULL,[to_day] date NULL,
PRIMARY KEY ([day_key]) )
GO
CREATE TABLE [emp_dim] (
[emp_key] int NOT NULL IDENTITY(1,1),
[birth_date] date NULL,[first_name] varchar(20) NULL,[last_name] varchar(20) NULL,
[emp_no] int NULL,[gender] varchar(10) NULL,[hire_date] date NULL,
PRIMARY KEY ([emp_key]) )
GO
CREATE TABLE [title_dim] (
[title_key] int NOT NULL IDENTITY(1,1),[title] varchar(50) NULL,
PRIMARY KEY ([title_key]) )
GO
CREATE TABLE [dept_dim] (
[dept_key] int NOT NULL IDENTITY(1,1),
[dept_no] char(4) NULL,[dept_name] varchar(40) NULL,PRIMARY KEY ([dept_key]) )
GO
CREATE TABLE [salaries_fact] (
[salary_key] int NOT NULL IDENTITY(1,1),
[salary] decimal(12) NULL,[emp_key] int NULL,[dept_key] int NULL,
[title_key] int NULL,[day_key] int NULL,PRIMARY KEY ([salary_key]) )
GO
ALTER TABLE [salaries_fact] ADD CONSTRAINT [day_s] FOREIGN KEY ([day_key]) REFERENCES [day_dim] ([day_key])
GO
ALTER TABLE [salaries_fact] ADD CONSTRAINT [emp_s] FOREIGN KEY ([emp_key]) REFERENCES [emp_dim] ([emp_key])
GO
ALTER TABLE [salaries_fact] ADD CONSTRAINT [title_s] FOREIGN KEY ([title_key]) REFERENCES [title_dim] ([title_key])
GO
ALTER TABLE [salaries_fact] ADD CONSTRAINT [demp] FOREIGN KEY ([dept_key]) REFERENCES [dept_dim] ([dept_key])
GO
这里我们不详细解释创建Integration Service项目的过程,仅给出几点需要注意的问题:
(1)样例数据库为Mysql数据库,SQL Server不支持将其作为数据源,我们可以使用数据库可视化工具Navicat将样例数据库中数据传输到SQL Server的employees数据库中,并以SQL Server的employees数据库作为源数据库。
(2)我们需要将前两次作业设计的模式生成SQL Server数据库作为数据仓库,这里我们的数据仓库名字为“21751106郑明月”。
3.2 抽取title_dim表
titles_dim表中包含titles_key、title两个字段,我们可以直接从示例数据库employees的titles表中抽取。这里要注意的是再抽取过程中需要将将title字段去重,我们设置titles_key字段为主键自增。
Step1:新建一个数据流任务,如图3.1所示

图3.1 创建数据流任务
Step2:设计该数据流中的OLEDB源,数据转换,OLEDB目标。将两张表的字段进行对应。如图3.2所示。
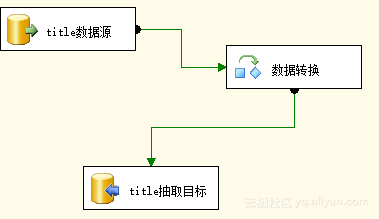
图3.2 设计数据流
抽取数据源使用的SQL语句为:
SELECT distinct title
FROM employees.titles
这里需要注意的是,如果直接将OLEDB源转为OLEDB目标,可会会有一个因为转码而造成的错误。如图3.3所示。

图3.3 一个错误
针对这个错误,我们设计一个中间转码的流程,如图3.4所示。
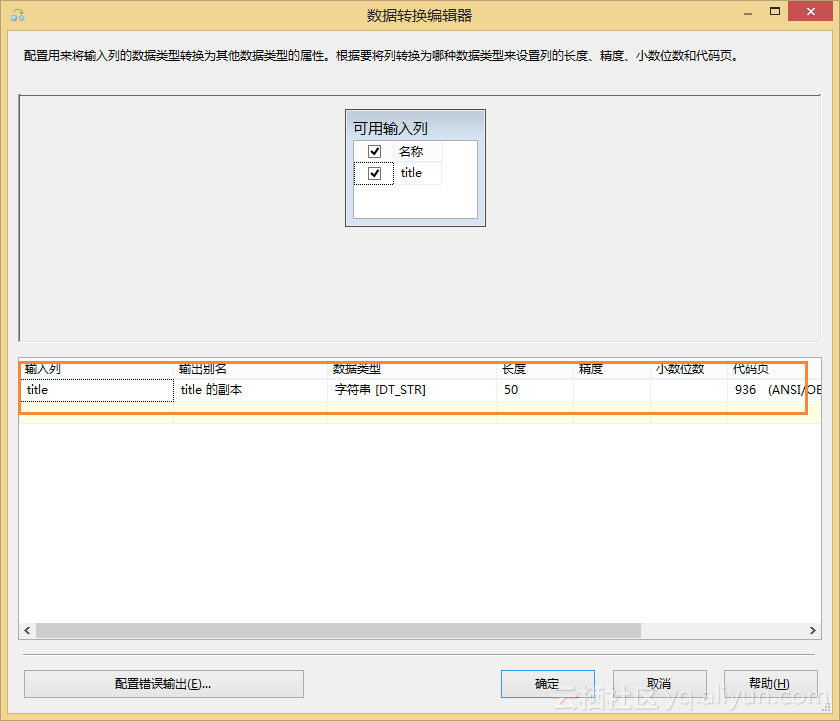
图3.4 错误的解决
Step3:执行包,经过执行包后,我们看到绿色显示即为成功。如图3.5所示。
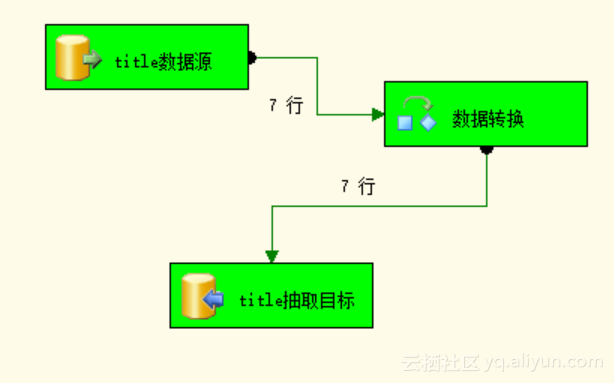
图3.5 执行成功
抽取成功后数据仓库中titles_dim表中有7行数据,如下图3.6所示。
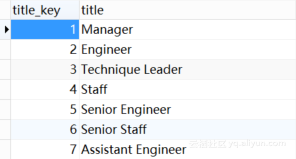
图3.6 title_dim 表
3.3 抽取dept_dim表
dept_dim表中包含dept_key、dept_no、dept_name三个字段,我们可以直接从示例数据库employees的department表中抽取。我们设置dept_key字段为主键自增。
Step1: 新建一个数据流任务,图3.7所示。

图3.7 新建一个数据流任务
Step2:设计该数据流中的OLEDB源,数据转换,OLEDB目标。将两张表的字段进行对应。如图3.8所示。
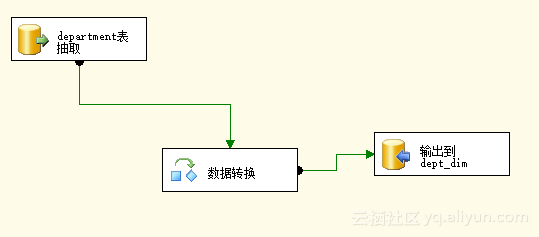
图3.8 设计数据流
抽取数据源使用的SQL语句为:
SELECT dept_no, dept_name
FROM employees.departments
Step3:执行包,经过执行包后,我们看到绿色显示即为成功。如图3.9所示。
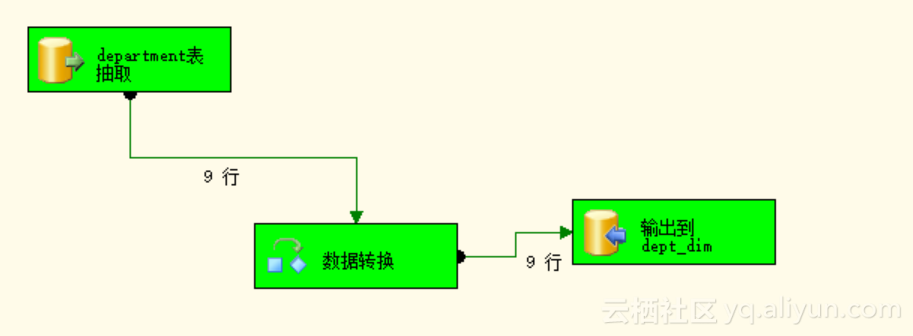
图3.9 执行成功
抽取成功后数据仓库中dept_dim表中有9行数据,如下图3.10
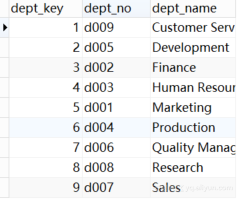
图3.10 dept_dim表
3.4 抽取emp_dim表
employees_dim表中包含employees_key、birth_date、first_name、last_name、emp_no、gender、hire_date七个字段,我们可以直接从示例数据库employees的employees表中抽取。我们设置employees_key字段为主键自增。
Step1: 新建一个数据流任务,如图3.11。

图3.11 新建一个数据流任务
Step2:设计该数据流中的OLEDB源,数据转换,OLEDB目标。将两张表的字段进行对应。如图3.12。
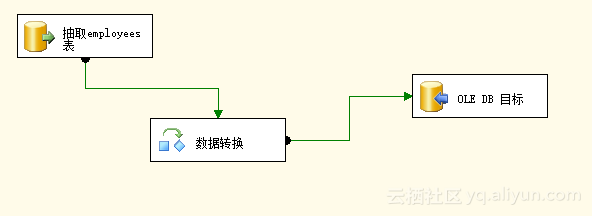
图3.12 设计数据流
抽取数据源使用的SQL语句为:
SELECT DISTINCT emp_no, birth_date, first_name, last_name, gender, hire_date
FROM employees.employees
Step3:执行包,经过执行包后,我们看到绿色显示即为成功。如图3.13。
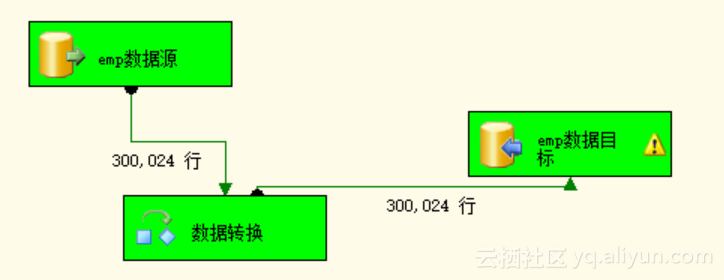
图3.13 执行成功
抽取成功后数据仓库中dept_dim表中有300024行数据,如图3.14:
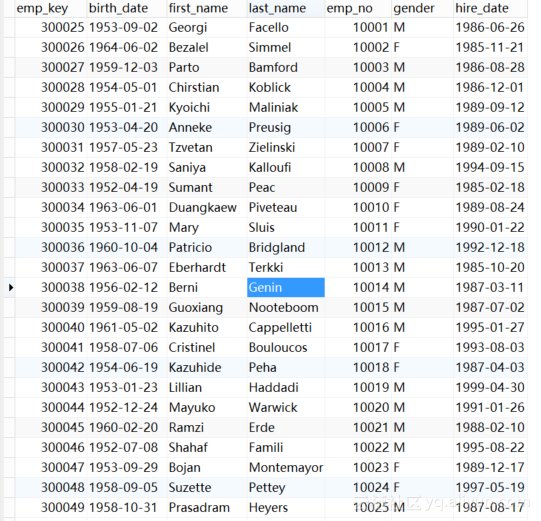
图3.14 dept_dim表
3.5 抽取day_dim表
day_dim表中包含day_key、from_day、end_day三个字段,我们可以直接从示例数据库employees的employees表中抽取。我们设置employees_key字段为主键自增。
Step1: 新建一个数据流任务,如图3.15。
图3.15 新建一个数据流任务
Step2:设计该数据流中的OLEDB源,OLEDB目标。将两张表的字段进行对应。如图3.16。
图3.16 设计数据流
抽取数据源使用的SQL语句为:
SELECT DISTINCT to_date, from_date
FROM employees.salaries
Step3:执行包,经过执行包后,我们看到绿色显示即为成功。如图3.17。
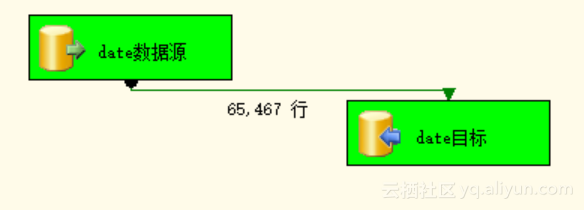
图3.17 执行成功
抽取成功后数据仓库中day_dim表中有331603行数据,如下图3.18:
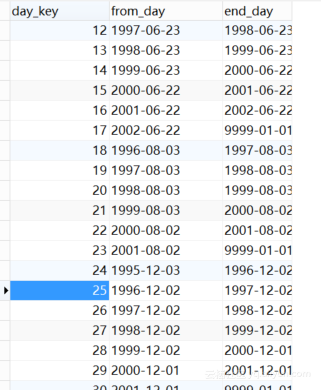
图3.18 day_dim表
四、作业四:事实表的抽取
事实表的抽取与维度表的抽取有相同的步骤,但是事实表抽取相对比较麻烦,这里我将事实表的抽取分为三个步骤。步骤一中,创建了中间表:将dept_emp与dept_manager表合并抽取到表produce_one、将salaries表与title表左连接抽取到表produce_two;步骤二中,将表produce_two与表produce_one左连接,抽取到包含所有信息的合并表produce_three;将表produce_three数据仓库中其他表左连接,抽取得到最终的事实表salaries_fact。下面详细讲解这一过程。
Step1:创建中间表
使用如下SQL语句抽取表produce_one:
SELECT
dept_emp.dept_no,dept_emp.emp_no,
dept_emp.from_date,dept_emp.to_date,
departments.dept_name
FROM
departments,dept_emp
WHERE
dept_emp.dept_no = departments.dept_no
使用如下SQL语句抽取表produce_two:
SELECT
salaries.emp_no,salaries.salary,
salaries.from_date AS salary_from_date,
salaries.to_date AS salary_to_date,
titles.from_date AS title_from_date,
titles.to_date AS title_to_date
FROM
salaries
LEFT JOIN titles ON salaries.emp_no = titles.emp_no
WHERE
salaries.from_date >= titles.from_date
AND salaries.to_date <= titles.to_date
Step2:抽取合并表
使用如下SQL语句抽取表produce_three:
SELECT
produce_two.emp_no,produce_two.salary,
produce_two.salary_from_date,produce_two.salary_to_date,
produce_two.title,produce_one.dept_no
FROM
employees. produce_two
LEFT OUTER JOIN employees.produce_one ON produce_two.emp_no =
produce_one.emp_no
WHERE
produce_two.salary_from_date >= produce_one.from_date
AND produce_two.salary_to_date <= produce_one.to_date
抽取成功后,该表中数据如图4.1所示。
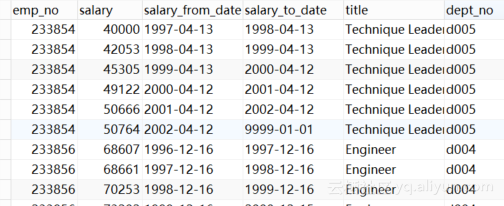
图4.1 表produce_three 数据
Step3:抽取事实表
得到produce_three表后,我们可以使用emp_no字段得到emp_dim表中的代理键emp_key;使用salary_from_date及salary_to_date字段得到day_dim表中的代理键day_key;使用title字段得到titles_dim表中的代理键title_key字段;使用dept_no字段得到dept_dim表中的dept_key字段。
设计事实表抽取数据流程如图4.2所示。
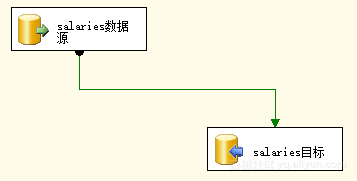
图4.2 事实表抽取数据流程
其中,抽取数据源部分使用的SQL语句如下:
SELECT
produce_one.salary,
emp_dim.emp_key,dept_dim.dept_key,
title_dim.title_key,day_dim.day_key
FROM
produce_one
LEFT JOIN title_dim ON produce_one.title = title_dim.title
LEFT JOIN day_dim ON produce_one.salary_from_date = day_dim.from_day
AND produce_one.salary_to_date = day_dim.to_day
LEFT JOIN dept_dim ON produce_one.dept_no = dept_dim.dept_no
LEFT JOIN emp_dim ON produce_one.emp_no = emp_dim.emp_no
以上数据流图执行成功后得到salaries_fact表,抽取成功结果图如图4.3所示。
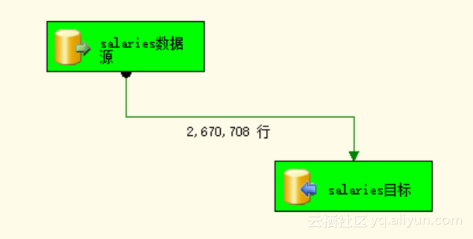
图4.3 抽取成功
salaries_fact表中数据如图4.4所示。
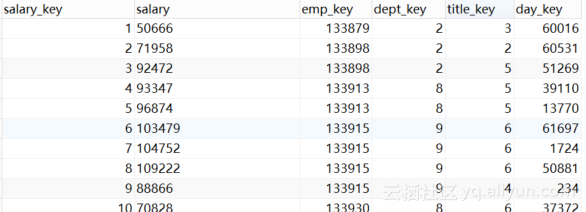
表4.4 salaries_fact表中数据
五、作业五:数据分析
本次作业要求使用SqlServer对数据仓库进行可视化,需要实现的需求有:(1)分析每个员工每个月的薪水情况;(2)分析每个部门的薪水情况;(3)分析不同职称的薪水情况。
想要实现对上文数据仓库中数据的分析,我们需要借助SqlServer提供的两个项目AnalysisService项目以及报表项目。首先我们在AnalysisService项目中构建多维数据集,然后使用报表项目对其进行可视化。下面我们分两步完成需求。
5.1构建多维数据集
构建多维数据集这一部分我们使用一个AnalysisService项目完成。这里省略创建项目以及创建数据源、数据源视图的步骤,着重阐述多维数据集的构造。如图5.1所示为创建数据源后的成果图。
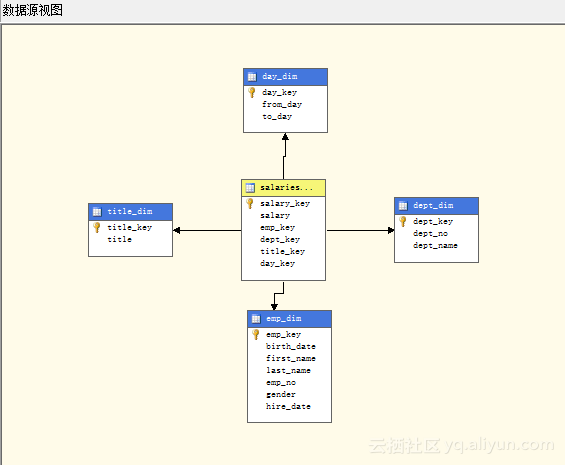
图5.1 创建数据源
Step1:创建多维数据集
我们以salaries_fact表为度量创建一个多维数据集,创建过程中主要流程如图5.2所示。
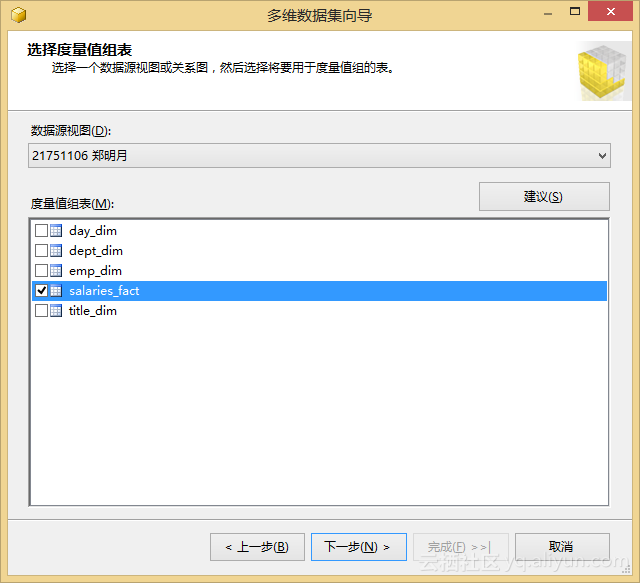
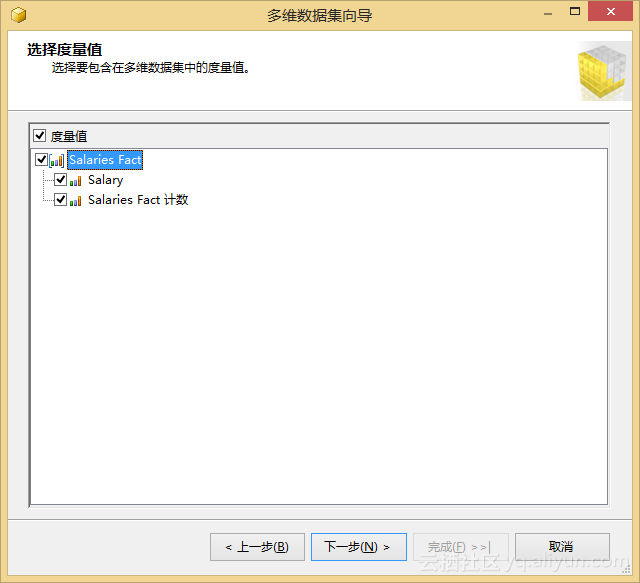
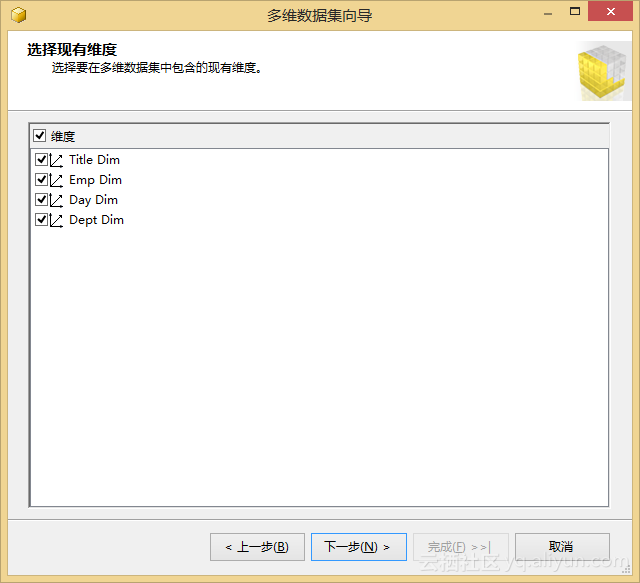
图5.2 创建一个多维数据集
Step2:完善维度
创建一个多维数据集之后,我们对度量的相关维度进行完善,为每个维度增加
字段,完善之后维度字段如图5.3所示。
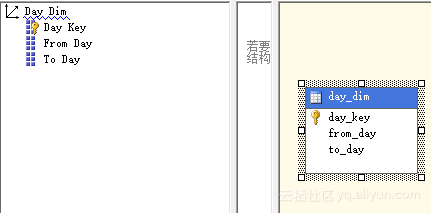

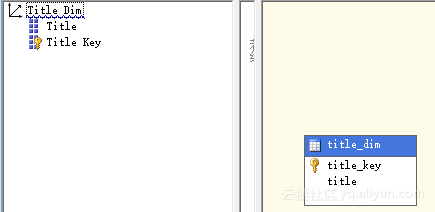
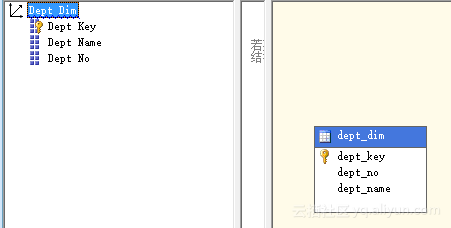
图5.3 完善维度
Step3:部署
我们通过在项目上右键,然后点击部署的方式部署多维数据集,部署结果如图5.4所示。
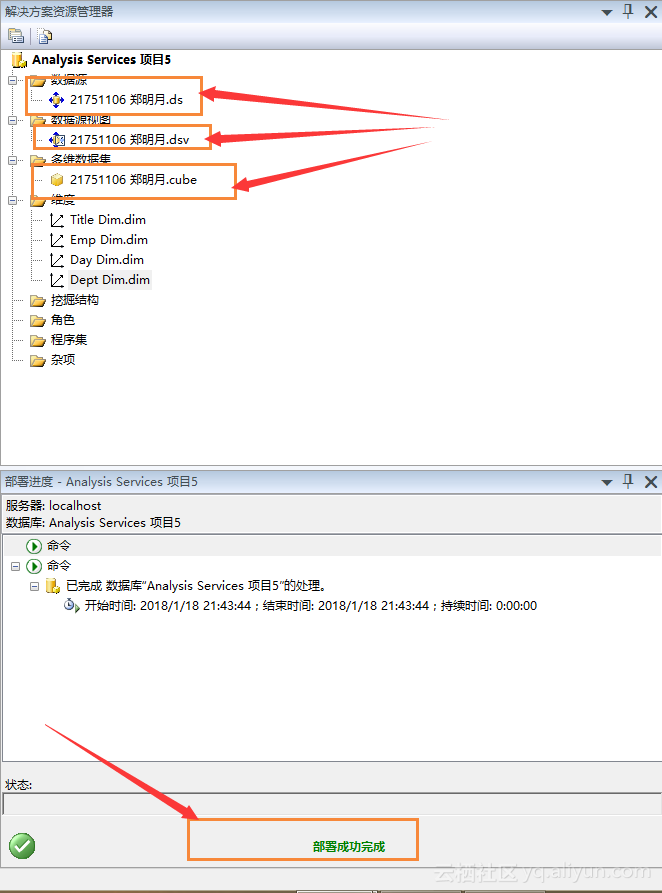
图5.4 部署完成
此时我们可以在SqlServer的浏览器中进行浏览,如图5.5所示。
图5.5 浏览器中浏览
5.2数据可视化
我们使用SqlServer提供的报表项目完成数据可视化。这里我将不会详细描述具体创建步骤,仅提出几点注意事项:
(1)创建共享数据源属性时,选择Analysis Service一项,连接到我们上文部署的多维数据集项目上,如图5.6所示;
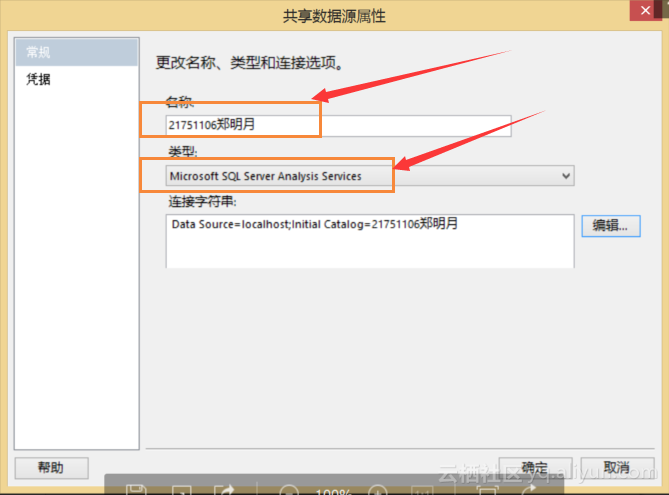
图5.6 创建共享数据源
(2)创建报表的查询设计器时务必要勾选参数这一项,否则该报表不能使用多个数值作为条件,如图5.7所示。
图5.7 勾选参数
5.2.1部门与工资之间的关系
Step1: 创建数据集
这里,我们选择Dept_Name、Salary、Salaries_Fact_计数、average_salary四个字段进行计算,如图5.8所示。其中average_salary为一个计算字段,其计算方式如公式(5.1)所示。
average_salary= Salary/ Salaries_Fact_计数 公式(5.1)
图5.8 创建数据集
Step2: 设计表格、绘制图表
我们设计表格、设计图表如下图5.9所示。
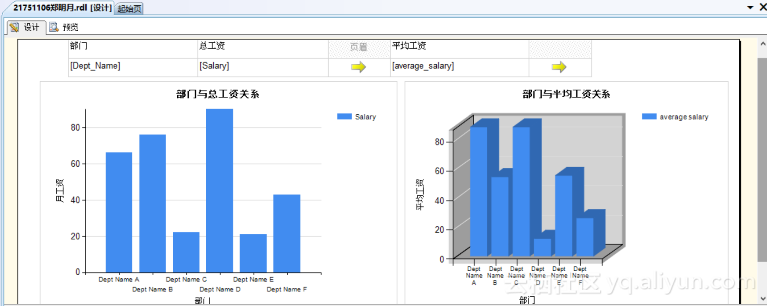
图5.9 设计表格图表
Step3: 图表的分析
根据Step2中的设计,可以得到表5.1及图5.10、图5.11。从图表中我们可以看出,部门:Development、Production、Sales的总工资较高;部门:Finance、Marking、Sales的人/月平均工资较高。
表5.1 部门与工资
| 部门 |
总工资 |
平均工资 |
||
| Customer Service |
9802982141 |
|
57461.45768 |
|
| Development |
42194302803 |
|
59225.80966 |
|
| Finance |
10120686629 |
|
70676.17305 |
|
| Human Resources |
8070960565 |
|
54971.80606 |
|
| Marketing |
11102046223 |
|
71764.54078 |
|
| Production |
35307268848 |
|
59541.78931 |
|
| Quality Management |
8862262053 |
|
57119.86989 |
|
| Research |
9580107115 |
|
59868.18595 |
|
| Sales |
35029560045 |
|
80564.39493 |
|
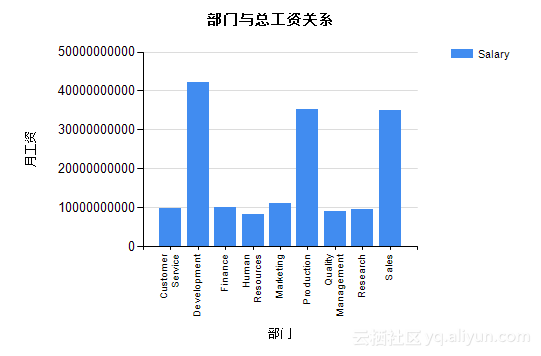
图5.10 部门与总工资关系
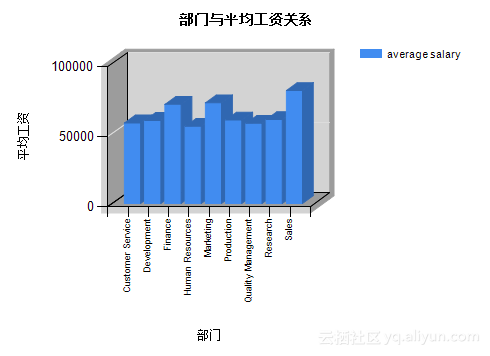
图5.11部门与平均工资关系
5.2.2 职称与工资关系
Step1: 创建数据集
创建数据集如图5.12所示。
图5.12 创建数据集
Step2: 设计表格、绘制图表
设计表格、绘制图表如图5.13所示
图5.13 设计表格、绘制图表
Step3: 图表的分析
根据Step2中的设计,可以得到表5.2及图5.13、图5.14。从图表中我们可以看出,职称:Assistant、Manger的总工资较低;职称:Manager、SeniorStaff的人/月平均工资较高。
表5.2 职称工资表
| 职称 |
总工资 |
平均工资 |
| Assistant Engineer |
4823711052 |
54121.1634054394 |
| Engineer |
36026662812 |
54877.4515676481 |
| Manager |
19696302 |
66994.2244897959 |
| Senior Engineer |
38254259493 |
64761.0026307815 |
| Senior Staff |
41803627986 |
75040.8883244357 |
| Staff |
40738678933 |
64118.2416064391 |
| Technique Leader |
8403539844 |
59326.9219756015 |
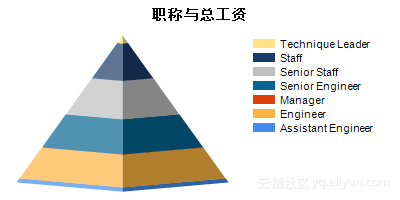
图5.13 职称与总工资
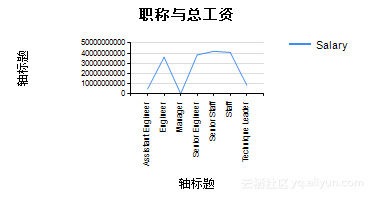
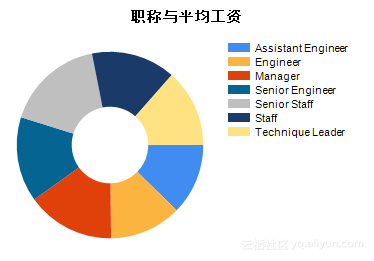
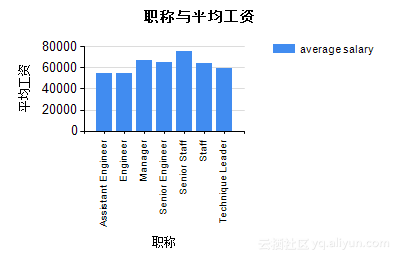
图5.14 职称与平均工资
5.2.3 性别与工资
Step1: 创建数据集
创建数据集如图5.15所示。
图5.15 创建数据集
Step2: 设计表格、绘制图表
设计表格、绘制图表如图5.16所示。
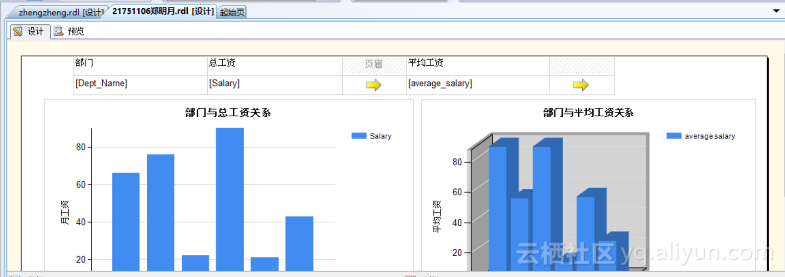
图5.16 设计表格、绘制图表
Step3: 图表的分析
根据Step2中的设计,可以得到表5.3及图5.17、图5.18。从图表中我们可以看出,职称:Assistant、Manger的总工资较低;职称:Manager、SeniorStaff的人/月平均工资较高。
表5.3 性别与工资
| 性别 |
总工资 |
平均工资 |
领取工资人数 |
| F |
67999416575 |
63640.8459578825 |
1068487 |
| M |
102070759847 |
63705.7933000504 |
1602221 |
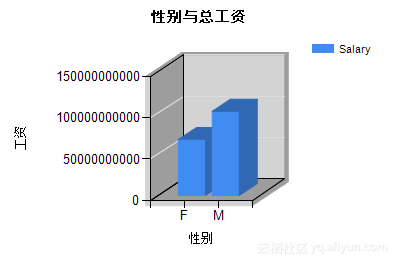
图5.17 性别与总工资
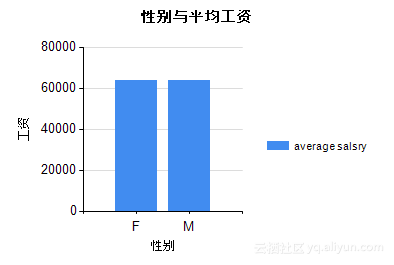
图5.18 性别与平均工资
5.2.4 职称、性别与工资
Step1: 创建数据集
创建数据集如图5.19所示。
图5.19 创建数据集
Step2: 设计表格、绘制图表
设计表格、绘制图表如图5.20所示。
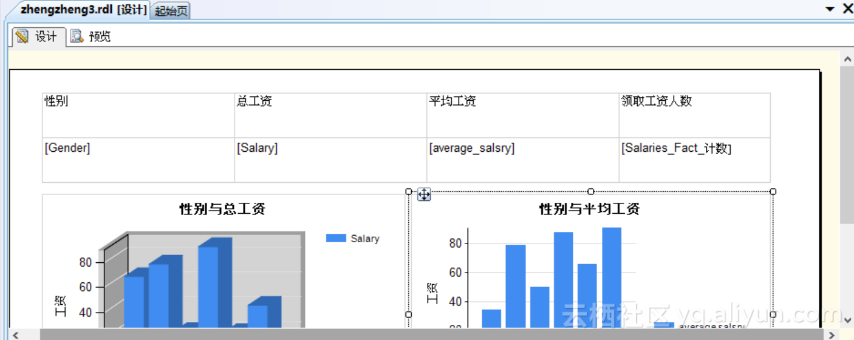
图5.20 设计表格、绘制图表
Step3: 图表的分析
根据Step2中的设计,可以得到表5.4、表5.5及图5.21、图5.22。
表5.4 职称性别与总工资
| Title |
F |
M |
| Assistant Engineer |
1882429902 |
2941281150 |
| Engineer |
14409240726 |
21617422086 |
| Manager |
8866422 |
10829880 |
| Senior Engineer |
15369973027 |
22884286466 |
| Senior Staff |
16705584008 |
25098043978 |
| Staff |
16232753513 |
24505925420 |
| Technique Leader |
3390568977 |
5012970867 |
表5.5职称性别与平均工资
| Title |
F |
M |
| Assistant Engineer |
53940.9107112155 |
54237.1593214088 |
| Engineer |
54817.7934238008 |
54917.2892875652 |
| Manager |
61572.375 |
72199.2 |
| Senior Engineer |
64700.1478676697 |
64801.9393501764 |
| Senior Staff |
75021.5963390921 |
75053.7348213672 |
| Staff |
64123.3167541645 |
64114.880264979 |
| Technique Leader |
59270.5004282842 |
59365.1441445709 |
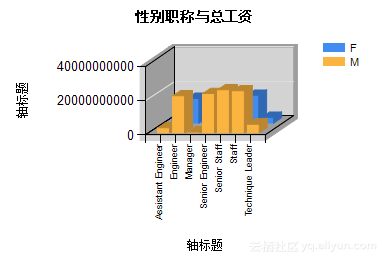
图5.21 性别职称与总工资
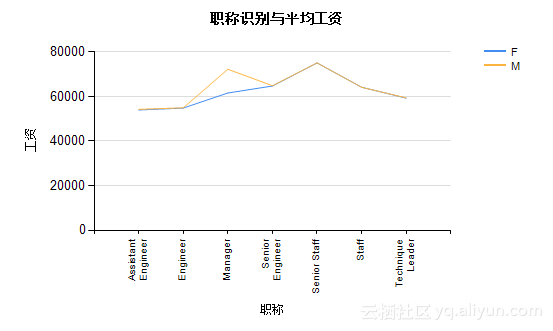
图5.22 性别职称与平均工资

