为保证阅读效果,本文将代码放置于附录中,将图表文件放置于外部文件夹
目录
1.1软件环境
工欲善其事必先利其器,在进行程序开发之前搭建合适的环境十分有必要。这里针对数据流处理的需求,以及自身条件,我对软件环境的搭建如下:(1)kafka集群(2)spark集群(3)hadoop集群(4)zookeeper集群。这四组集群搭建在三台虚拟机上,其中每组集群在每台虚拟机上都有一个节点。
我选择使用Python语言进行开发,相对与Java繁琐的代码以及Scala陌生的语法结构,使用Python能够收获较高的开发效率。同时Python拥有众多易于使用的库,有利于数据可视化及数据库存储,但是,在Spark Streaming方面Python语言开发的案例较少,这是一个不小的挑战。这里,我将程序开发所需的Python库均安装在集群上,其中pyMysql用于数据库存储开发;pyEcharts用于数据可视化;pykafka用于处理kafka集群数据;pySpark用户开发SparkStreaming;kazoo用于处理zookee集群。
同时,在集群内部提交Python程序会使得开发效率降低。这里,我是在window操作系统上用Pycharm远程控制的方式进行编码调试,即通过SSH的方式使Pycharm连到虚拟机上,然后编程时使用虚拟机远程的Python环境,并在虚拟机上建立与Window平台上工程文件夹的映射,实时将虚拟机与Window中的代码同步。
1.2配置环境中遇到的问题
相对来说,上文所说的开发环境较为复杂,在搭建过程中有很多需要注意的地方,这里我给出几处我遇到的问题极其解决方式:
(1)Spark中无法找到Kafka有关jar包,如图1.1所示。这个问题是由于Python没有提供spark-streaming-kafka-0-8:2.2.0造成的,仅需下载该Jar包,并将其放入每个Spark集群节点的“/jar”目录下,并重启集群就可以解决。
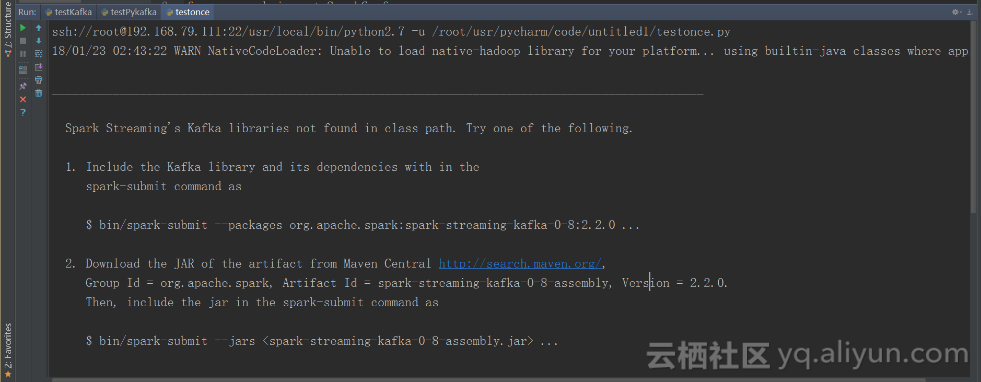
图1.1 spark-streaming-kafka-0-8:2.2.缺失
(2)程序启动抛出making it as stoppted异常。这个异常是因为设置了checkPoint后,非首次运行,程序都会尝试恢复checkPoint中的数据,但是如果两次运行的程序如果有改动,那么从checkpoint中恢复数就会失败。所以,解决这个问题的办法就是在程序有改动时,运行前先清空checkPoint目录。
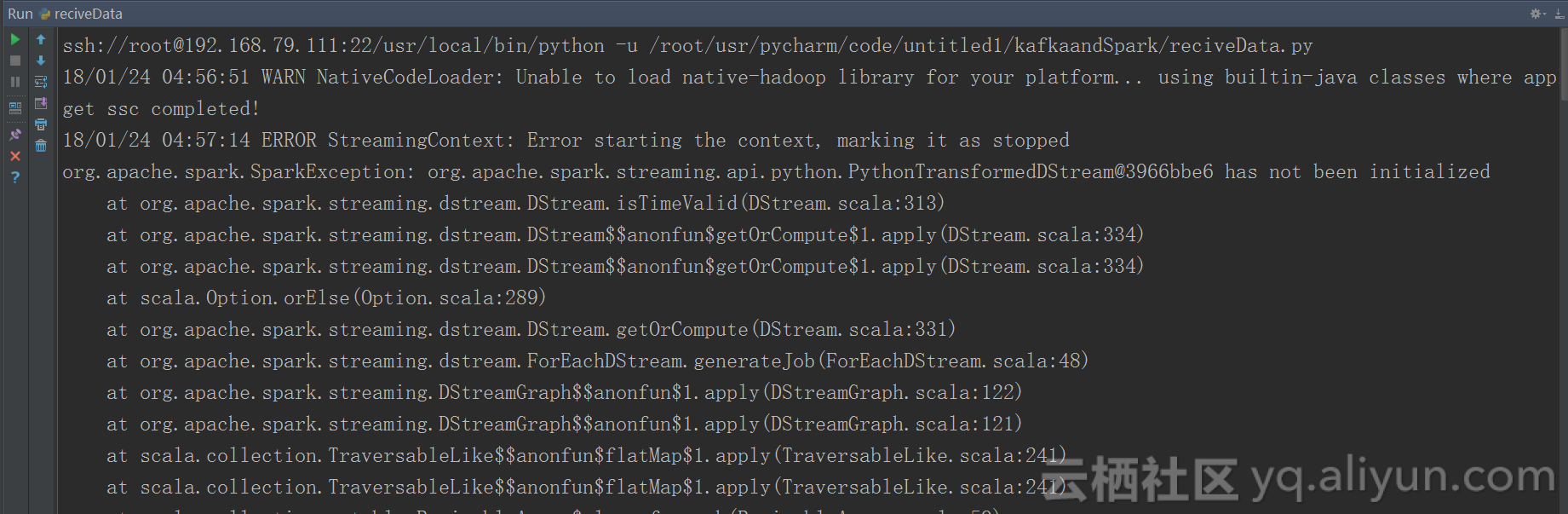
图1.2 making it as stoppted异常
1.3整体架构
本文描述了一个集构建数据流,数据流处理,数据流可视化,数据流存储为一体的程序系统。根据功能划分,程序由以下模块组成:数据发送模块、数据库存储模块、可视化模块、数据流处理辅助模块、数据处理模块五个模块组成。其中,数据发送模块将骑行数据以行为单位发送值kafka集群,数据处理模块从kafka模块获取数据;可视化模块负责将数据绘制成图表、数据库存储模块负责将数据存储到数据库中;数据流处理辅助模块负责对于数据六数据的转化,以及可视化模块、数据存储处理模块与数据处理模块的对接,以上关系可以使用图1.3表示。
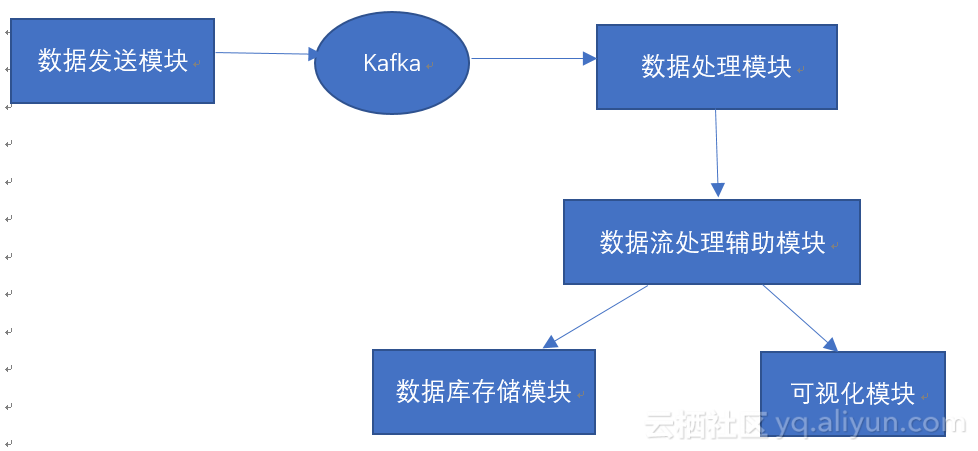
图1.3 系统模块关系图
2.1 数据发送模块
数据发送模块负责将数据逐行发送到Kafka中,在发送数据之前还需要对数据的格式进行一定的处理,如:去掉双引号、去掉首行标签名;同时我们需要对于消息发送的速度进行控制。这里我们使用类producer来实现这一功能,其中fileResource中存放待发送的文件名;prodecerCon代表一个kafka的连接,我们通过这个连接向集群发送信息;函数getMenssage(self,msgNumber)为向集群发送消息的功能函数,其类图如图2.1所示。

图2.1 producer类图
(1)getMenssage(self,msgNumber)函数。该函数接收msgNumber用于控制消息发送的速度。首先,函数打开fileResouce中的第一个文件,从中取出一行,校对改行格式;然后,将改行消息发送给kafka,同时计数,当计数达到msgNumber时,出发一个延时器,该延时器让线程随机休眠0~1s,再次读取文件下一行,当该文件中数据全部被取出后,打开一下一个文件进行读取。
2.2 数据库存储模块
2.2.1数据库表设计
数据库中的表存储流数据处理的结果,这里对于表的结构设计较为简单,各个表之间没有关联,对于表的设计如图2.2所示。
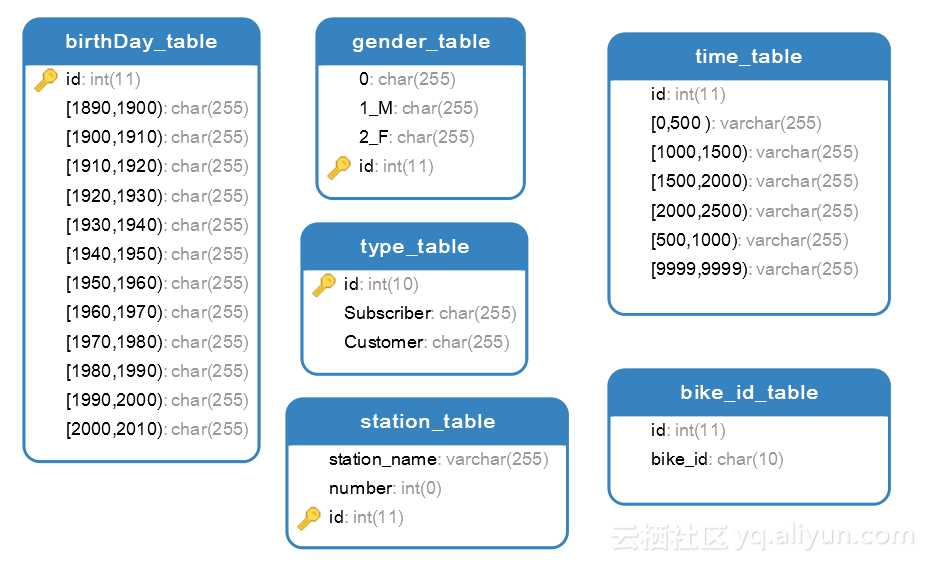
图2.2 数据库表的设计
2.2.2数据库操作代码
数据库存储处理模块负责将流数据处理的结果保存到数据库中,我们选用Mysql数据库。这里config用于保存数据库的配置参数;getMessage(self,msgNumber)函数用于获取一个数据库连接;insertIntoMysql(self,connection,sql,data)函数用于将数据插入到数据库中;selectFromMysql(self,connection,sql,data=None)函数用于从数据库中查询数据。该类的类图如图2.3所示。

图2.3 databaseCon类类图
(1)getMysqlCon(self)函数。该函数使用conf作为连接Mysql数据库的参数,获取并返回一个连接。
(2)selectFromMysql(self,connection,sql,data=None)函数。该函数接收connetion数据库连接,数据库操作语句sql,以及sql语句中的所需的数据data,最终函数将会返回一个json格式的查询结果。这里要注意的是需要将这些对于数据库的操作放置于try-catch语句中,否则可能会因为无法连接数据库而抛出一个异常;在执行完毕Sql语句之后要将数据库的连接关闭。
(3)insertIntoMysql(self,connection,sql,data)函数。该函数接收connetion数据库连接,数据库操作语句sql,以及sql语句中的所需的数据data。该函数实现原理与selectFromMysql(self,connection,sql,data=None)函数相似,这里不做重复阐述。
2.3 可视化模块
可视化模块负责将处理过的数据流数据用图标的形式展示出来。 该类只需要实现绘制不同图表的功能,不需要共享数据,所以这里没有属性。在drawPicture类中,drawBar(self,main_name,sub_name,count,type,data)函数绘制了一个条形图;drawEffectScatter(self,name,count1,data1,data2,count2,data3,data4)绘制一个散点图;drawPie(self,name,type,data)函数绘制一个饼形图;drawWordCloud(self,name,type,data)函数绘制一个词云图。该类的类类图如图2.4所示。

图2.4 drawPicture类图
(1)drawBar(self,main_name,sub_name,count,type,data)函数。该函数接收主标题main_name、副标题sub_name、统计量名称,数据类型,数据值五个参数。在函数内部调用了Pyecharts插件的接口,实例化并配置了一个Bar图,并将其渲染到指定路径下,生成html文件,这里为了保证html文件命名的唯一性,在名称的末尾增添了一个时间戳。
(2)drawEffectScatter(self,name,count1,data1,data2,count2,data3,data4)函数。该函数接收两组数据,并将这两组数据以散点图的形式绘制出来。函数内部逻辑与drawBar(self,main_name,sub_name,count,type,data)函数相似,这里不做赘述。
(3) drawPie(self,name,type,data)函数。该函数接收数据绘制一个饼图。函数内部逻辑与上文类似,这里不做赘述。
(4) drawWordCloud(self,name,type,data)函数。这个函数根据数据值的大小绘制一个词云图。
3.1 数据流处理辅助模块
该模块主要有两部分任务:数据流转换、数据流存储与展示。其中数据流转换部分主要是替代数据处理模块的map过程中需要用到的复杂的lambda表达式;数据流存储与展示部分主要是实现数据处理模块的的foreach过程中逐个对RDD的操作。
3.1.1数据流转换
在数据流转换功能中主要是对与源数据流进行的过滤和创造元组的操作。在对源数据流执行map的过程中,使用到该文件中函数。因为该功能中函数只能有一个参数,倘若使用类结构实现该功能,则代表类本身的self参数永远占据第一个参数的位置,这时会出现非常麻烦的情况,所幸该功能中函数不需要共享数据,则我们仅将功能类似的函数放置在一个文件中,该文件结构如图3.1所示。
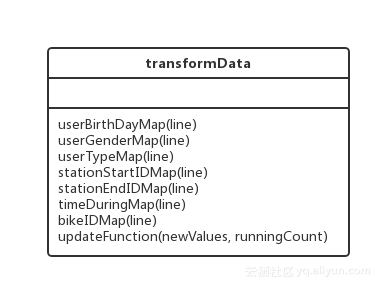
图 3.1 transformData文件结构
(1)userBirthDayMap(line)函数。该函数接收一行信息,并从中提取出用户出生日期信息,将日期按照时间分段后,返回元组(time,1),其中time的分段值如表3.1所示。
表3.1 出生日期时间分组表
| Time |
BirthDay范围 |
| [1890,1900) |
1890~1900 |
| [1900,1910) |
1900~1910 |
| [1910,1920) |
1910~1920 |
| [1920,1930) |
1920~1930 |
| [1930,1940) |
1930~1940 |
| [1940,1950) |
1940~1950 |
| [1950,1960) |
1950~1960 |
| [1960,1970) |
1960~1970 |
| [1970,1980) |
1970~1980 |
| [1980,1990) |
1980~1990 |
| [1990,2000) |
1990~2000 |
| [2000,2010) |
2000~2010 |
| [9999,9999) |
其他 |
(2)userGenderMap(line)函数。该函数接收一行信息,从中取出用户性别信息,并将信息已元组(msg,1)的形式返回。这里要注意的一点是,从数据源获取的数据在Python环境中均为unicode编码,这里需要将其解码为utf-8形式再进行处理。
(3)userTypeMap(line)函数获取用户类型信息,这里用户分为订阅用户和访客用户两种。对于数据的处理上文已经阐述,这里不再重复。
(4)stationStartIDMap(line)函数。函数获取起始站台信息,返回元组(msg,1)。
(5)stationEndIDMap(line)函数。函数获取到达站台信息,返回元组(msg,1)。
(6)timeDuringMap(line)函数。该函数获取骑行时间信息,这里将骑行时间按时间段进行了划分,最终返回元组(time,1),其中time的取值如表3.2所示。
表3.2 骑行时间分组表
| Time |
timeDuring范围 |
| [0,500 ) |
0~500 |
| [500,1000) |
500~1000 |
| [1000,1500) |
1000~1500 |
| [1500,2000) |
1500~2000 |
| [2000,2500) |
2000~2500 |
| [9999,9999) |
其他 |
(7)bikeIDMap(line)函数。该函数获取单车信息,并对单车ID进行统计。
(8)updateFunction(newValues, runningCount)函数。该函数作为updateByKey()函数的参数,累积多次流数据的信息。
3.1.2数据流存储与展示
在该功能部分主要实现将进过初步转化的流数据格式进行转换,从而数据插入数据库、绘制成图标。因为该部分函数要做为foreachRDD函数的参数,则只能有一个参数,由此该功能函数不能封装在类中,仅简单将功能类似的函数放在同一个文件中。其中baseTransformRDD(rdd)函数负责将rdd转换为两个列表,这两个列表中分别存储key和value;其他函数则是为实现插入特定数据库及绘制不同类型的图表。drawAndStoreData文件的结构如图3.2所示。

图 3.2 drawAndStoreData文件结构
(1)baseTransformRDD(rdd)函数。该函数首先使用sort函数将rdd排序,然后使用collect函数收集所有rdd,最后收集结果的key与value值一一对应存在两个列表中。
(2)userTypeDataDeal(rdd)、userGenderDataDeal(rdd)、userBirthDayDataDeal
(rdd)、stationStartIDDataDeal(rdd)、timeDuringDataDeal(rdd)、bikeIDDataDeal
(rdd)函数。这些函数中调用了baseTransformRDD(rdd)函数用来获取key列表与value列表,然后将key列表与value列表作为参数,通过拼接字符串的方式构造sql语句,调用数据库存储模块函数将数据插入数据库;然后调用可视化模块对应绘图函数进行画图。
3.2 数据处理模块
数据处理模块负责从kafka获取数据流,并通过数据流处理辅助模块使用数据存储模块、可视化模块的功能,将数据进行转换后存储到数据库中、绘制成图表进行展示。该模块可以分为两部分:一部分为数据统计公共部分,负责获取数据流,开始数据流处理任务;一部分为定制数据处理部分,主要对于用户出生日期、用户性别、用户类型、出发车站、到达车站、使用时间、单车ID进行了三种统计:当前批次统计、窗口统计、updateByKey的所有数据统计。这些功能均实现在类dealDStream中,如图3.3是该类类图。

图3.3 dealDStream类类图
3.2.1 数据统计公共部分
数据统计公共部分的主要任务是获取一个Dstream数据流并启动该数据流任务,为了实现这里目标,我们需要进行如下流程:
Step1:检查checkPoint目录下是否有记录,如果有记录,从该目录下获取一个SparkStreaming对象,执行Step3;如果没有记录,执行Step2;
Step2:获取一个SparkConf对象,根据SparkConf对象获取一个SparkContext对象,根据SparkContext对象获取一个SparkStreaming对象,并为该SparkStreaming对象设置checkPoint;
Step3:设置kafka数据流参数,并获取一个数据流,返回该数据流;
Step4:在对数据流进行一系列处理后,使用start()函数及awaitTermination()函数开启数据流任务。
以上流程对应于函数实现如下:
(1)functionToCreateContext(self)函数。该函数负责Step2中的工作,通过给属性赋值返回一个SparkStreamingContext对象。
(2)getConfig(self,appName='KafkaDirectWordCount')函数。该函数负责Step1中的工作,返回一个SparkStreamingContext对象。
(3) getDStream(self,start=None)函数。该函数接收一个参数start作为接收kafka集群数据的位置偏移量。通过使用KafkaUtils API获得一个数据流对象,即实现Stepp3中的功能。
(4)startWork(self)函数。该函数用于启动数据流任务,实现Step4中的功能。
3.2.2 用户数据统计
该统计部分主要是对与用户有关的统计量进行的统计,其中包含用户出生日期、用户类型、用户性别的统计。对于每种统计均有当前批次、窗口期间、updateStateByKey的所有时间内。
3.2.2.1用户出生日期统计
用户出生日期统计部分获取了每行数据中关于用户出生日期的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)userBirthDay(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的userBirthDayMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的userBirthDayDataDeal函数。
(2)userBirthDayWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与userBirthDay(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)userBirthDayUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的userBirthDayMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的userBirthDayDataDeal函数。
3.2.2.2 用户性别统计
用户性别统计部分获取了每行数据中关于用户性别的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)userGender(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的userGenderMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的userGenderDataDeal函数。
(2)userGenderWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与userGender(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)userGenderUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的userGenderMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的userGenderDataDeal函数。
3.2.2.3 用户类型统计
用户类型统计部分获取了每行数据中关于用户性别的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)userType(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的userTypeMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的userTypeDataDeal函数。
(2)userTypeWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与userType(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)userTypeUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的userTypeMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的userTypeDataDeal函数。
3.2.3 车站数据统计
车站数据统计部分获取了每行数据中关于车站的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
3.2.3.1 出发车站统计
出发车站统计部分获取了每行数据中关于出发车站的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)stationStartID(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的stationStartIDMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的stationStartIDDataDeal函数。
(2)stationStartIDWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与stationStartID(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)stationStartIDUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的stationStartIDMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的stationStartIDDataDeal函数。
3.2.3.2 到达车站统计
到达车站统计部分获取了每行数据中关于到达车站的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)stationEndID(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的stationEndIDMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的stationEndIDDataDeal函数。
(2)stationEndIDWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与stationEndID(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)stationEndIDUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的stationEndIDMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的stationEndIDDataDeal函数。
3.2.4 使用时间数据统计
使用时间数据统计部分获取了每行数据中关于使用时间数据的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)timeDuring(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的timeDuringMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的timeDuringDataDeal函数。
(2)timeDuringWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与timeDuring(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)timeDuringUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的timeDuringMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的timeDuringDataDeal函数。
3.2.5 单车数据统计
单车数据统计部分获取了每行数据中关于单车数据的信息。每个数据流进入函数内部后都要经过map以及reduce的过程。最后使用foreachRDD函数将其存储到数据库中、可视化为图表。
(1)bikeID(self,dstream)函数。该函数对于无状态的数据流进行处理,接收一个数据流dstream作为参数。在map时调用transformData类中的bikeIDMap函数,执行foreachRDD操作时使用drawAndStoreData文件中的bikeIDDataDeal函数。
(2)bikeIDWithWindow(self,dstream,length=3,step=1)函数。该函数对于有状态的数据流进行处理,接收一个数据流dstream,一个窗口大小length,一个窗口每次移动步长step作为参数。内部实现与timeDuring(self,dstream)函数基本类似,但是增加了一个维持数据流状态的window函数。
(3)bikeIDUpdateState(self,dstream)函数。该函数接收一个数据流dstream作为参数。在map时调用transformData类中的bikeIDMap函数,在updateStateByKey时调用transformData类中的updateFunction函数,执行foreachRDD操作时使用drawAndStoreData文件中的bikeIDDataDeal函数。
在完成程序代码的调试工作后,我运行程序一段时间后得到了一些成果,这里设置每3秒钟的数据作为一次数据下面是对于各种统计量的数据处理结果展示。如图4.1所示是程序运行时的日志截图。
图4.1 程序运行日志截图
4.1 用户数据统计展示
数据库中数据展示如图4.1所示。
 Â Â Â Â Â
    Â
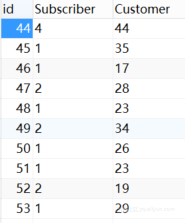
图4.2 用户数据统计数据库展示
(1)用户类型
用户类型统计数据的累积统计量图表如图4.3所示。其中Subscriber用户有7584人/次,Customer用户有510人/次。
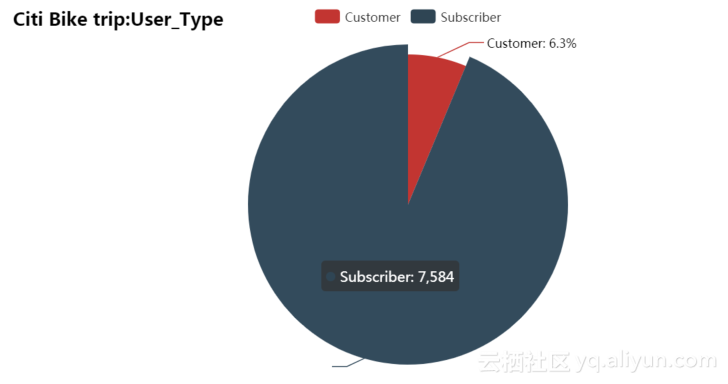
图4.3 用户类型累积数据饼形图
用户类型统计数据的当前统计量图表如图4.4所示。其中Subscriber用户有42人/次,Customer用户有6人/次。
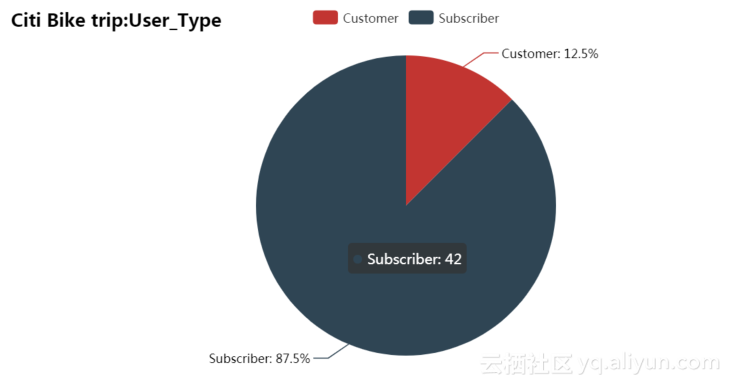
图4.4 用户类型当前数据饼形图
(2)用户类别
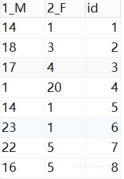
用户性别统计数据的累积统计量图表,其中“0”表示没有填写性别信息,“1”表示男性,“2”表示女性。在下表中未填写性别510人/次,男性5766人/词,女性1818人/次。如图4.5所示。
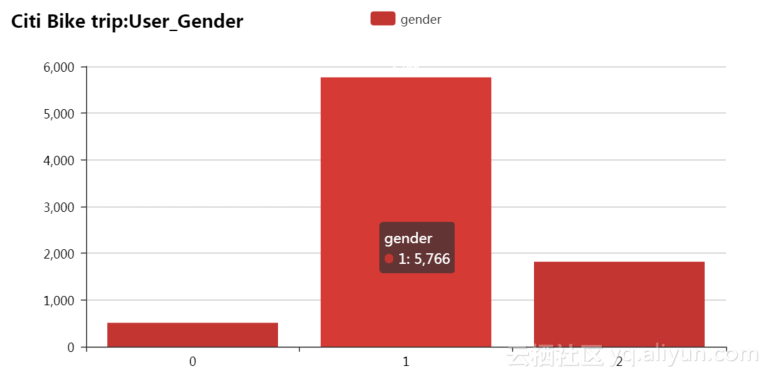
图4.5 用户性别累积条形图
用户性别统计数据的累积统计量图表,其中“0”表示没有填写性别信息,“1”表示男性,“2”表示女性。在下表中未填写性别6人/次,男性34人/词,女性8人/次。如图4.6所示。
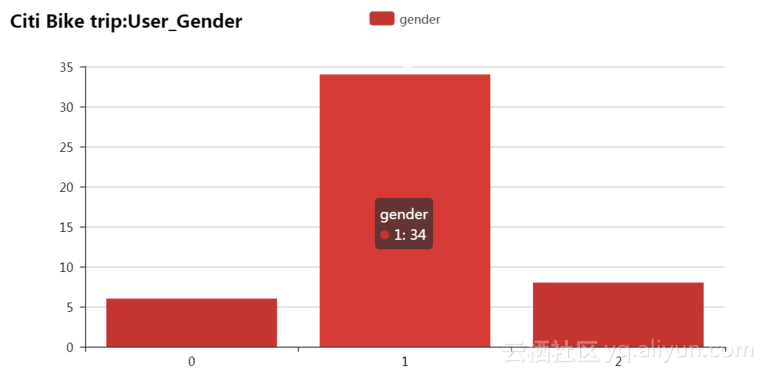
图4.6 用户性别当前数据条形图
(3)用户出生日期
用户出生日期统计数据的累积统计量图表,其中各个年龄段的统计数据如表4.1所示。如图4.7所示。
表4.1 用户年龄数据统计表
| birthDay |
数量 |
| [1900,1910) |
3 |
| [1910,1920) |
1 |
| [1930,1940) |
4 |
| [1940,1950) |
116 |
| [1950,1960) |
677 |
| [1960,1970) |
1349 |
| [1970,1980) |
2076 |
| [1980,1990) |
2884 |
| [1990,2000) |
472 |
| [9999,9999) |
512 |
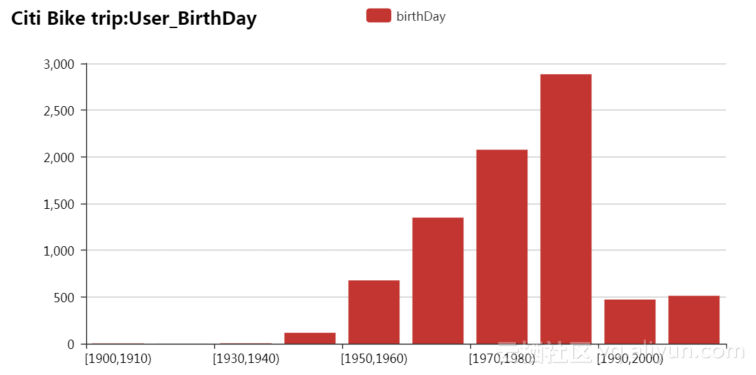
图4.7 用户出生日期累积数据图
用户出生日期统计数据的当前统计量图表,其中各个年龄段的统计数据如表4.2所示。如图4.8所示。
表4.2 用户出生日期当前数据统计表
| birthDay |
数量 |
| [1960,1970) |
6 |
| [1970,1980) |
15 |
| [1980,1990) |
17 |
| [1990,2000) |
4 |
| [9999,9999) |
6 |
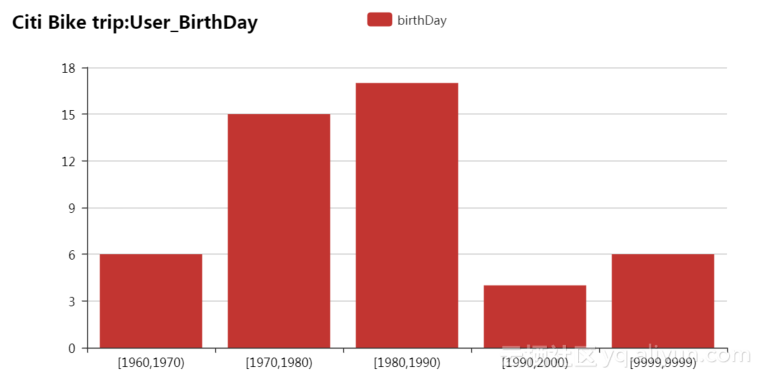
图4.8 用户出生日期当前数据统计图
4.2 车站数据统计
数据库中数据展示如图4.9所示
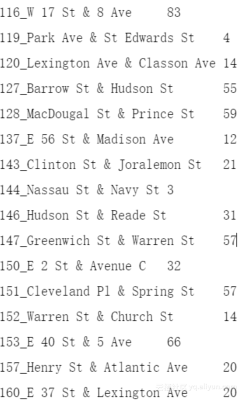
图4.9 车站统计数据数据库展示
(1)出发车站数据
出发车站累积统计数据如图4.10所示。其中,编号为232的车站出发人次最多。
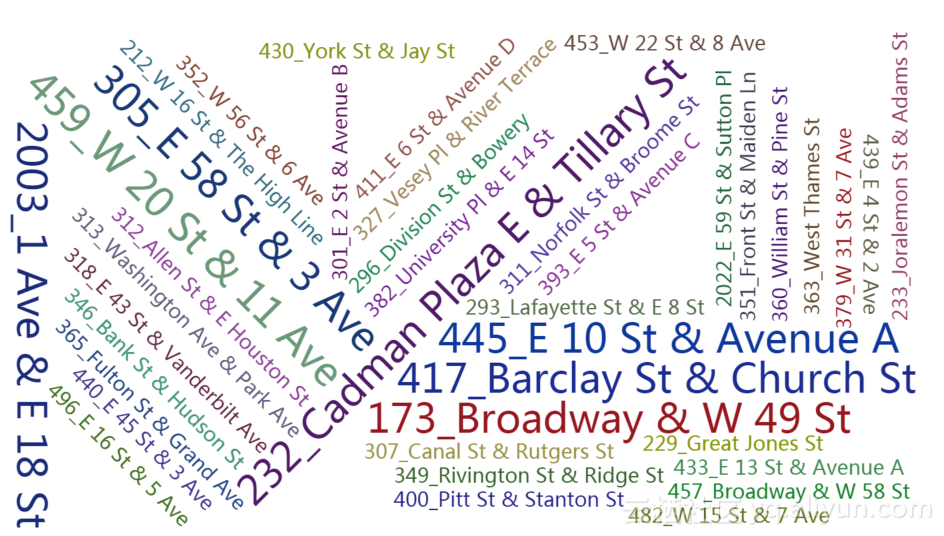
图4.10 出发车站累积数据统计
出发车站当前数据如图4.11所示。

图4.11 出发车站当前数据统计
(2)到达车站数据
到达车站累积统计数据如图4.12所示。其中,编号为232的车站出发人次最多。

图4.12 到达车站累积数据统计
到达车站当前数据如图4.13所示。

图4.13 到达车站当前数据统计
4.3使用时间
数据库中数据展示如图4.14所示

图4.14 使用时间数据数据库展示
使用时间累积数据如图4.15所示,其中数据如表4.3所示。
表4.3 使用时间累积数据表
| 使用时间 |
数量 |
| [0,500 ) |
3083 |
| [1000,1500) |
1157 |
| [1500,2000) |
454 |
| [2000,2500) |
166 |
| [500,1000) |
3062 |
| [9999,9999) |
124 |
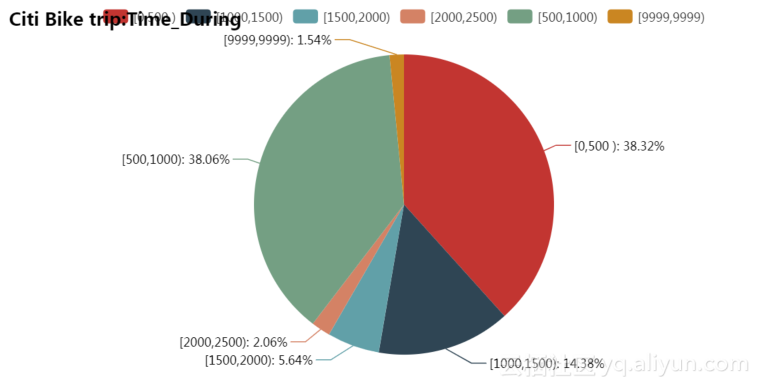
图4.15 使用时间累积数据图
使用时间当前数据如图4.16所示,其中数据如表4.4所示。
表4.4 使用时间当前数据表
| 使用时间 |
数量 |
| [0,500 ) |
40 |
| [1000,1500) |
21 |
| [1500,2000) |
14 |
| [2000,2500) |
2 |
| [500,1000) |
53 |
| [9999,9999) |
5 |
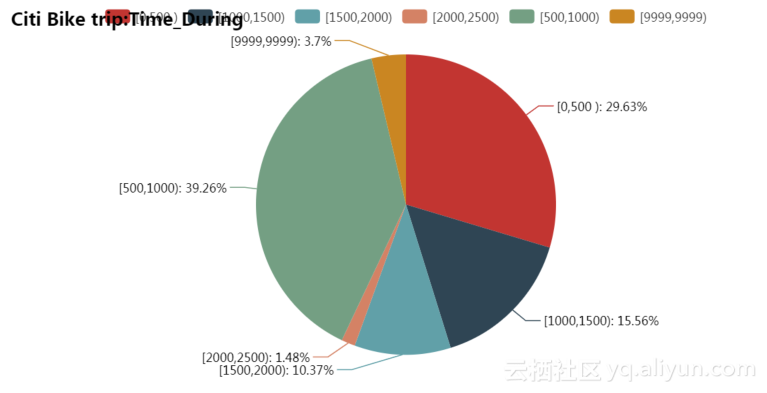
图4.16 使用时间当前数据图
4.4 单车数据统计
数据库中数据展示如图4.17所示.

图4.17 数据库中数据数据库
单车数据累积数据如图4.18所示,其中17897单车被使用次数最多。

图4.18 单车数据累积数据图
单车数据当前数据如图4.19所示,其中17897单车被使用次数最多。
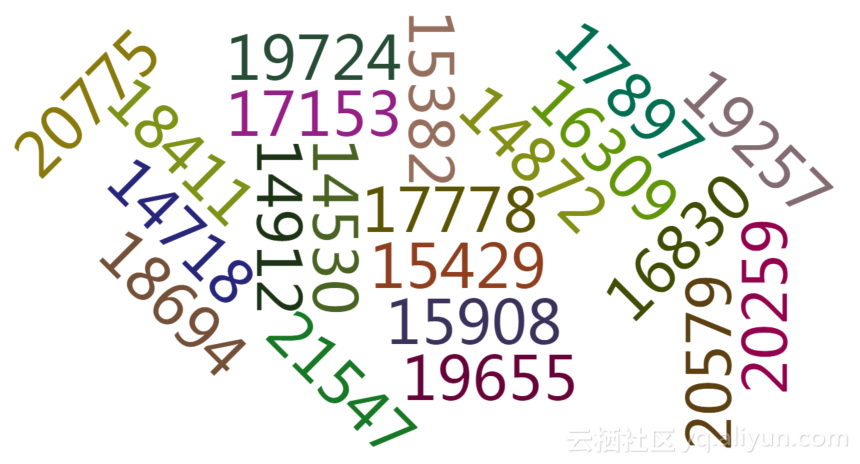
图4.19 单车数据当前数据图
5.1 databaseCon类
# encoding:utf-8
__author__ = 'zheng'
import pymysql.cursors
#*****************************************************************************************************#
#连接数据库部分
class databaseCon:
#设置数据库连接信息
config = {
'host':'192.168.79.111',
'port':3306,
'user':'root',
'password':'123456',
'db':'spark_kafka',
'charset':'utf8mb4',
'cursorclass':pymysql.cursors.DictCursor,
}
#获取数据库连接
def getMysqlCon(self):
connection = pymysql.connect(**self.config)
return connection
#向数据库插入数据
#sql 'INSERT INTO employees (first_name, last_name, hire_date, gender, birth_date) VALUES (%s, %s, %s, %s, %s)'
#data ('Robin', 'Zhyea', tomorrow, 'M', date(1989, 6, 14))
def insertIntoMysql(self,connection,sql,data):
try:
with connection.cursor() as cursor:
# 执行sql语句,插入记录
cursor.execute(sql,data)
# 没有设置默认自动提交,需要主动提交,以保存所执行的语句
connection.commit()
print("insert option complete!")
finally:
connection.close()
#从数据库获取数据
#sql = 'SELECT first_name, last_name, hire_date FROM employees WHERE hire_date BETWEEN %s AND %s'
#data (hire_start, hire_end)
def selectFromMysql(self,connection,sql,data=None):
try:
with connection.cursor() as cursor:
# 执行sql语句,进行查询
cursor.execute(sql,data)
# 获取查询结果
result = cursor.fetchall()
print(result)
# 没有设置默认自动提交,需要主动提交,以保存所执行的语句
connection.commit()
print("select option complete!")
result=str(result).replace("[","").replace("]","").split("}, {")
result1=[]
for one in result:
result1.extend(one.replace("{","").replace("}",""))
print(result1)
return result1
finally:
connection.close()
'''
DStreamInstance=dealDStream()
a=DStreamInstance.database.selectFromMysql(
connection=DStreamInstance.database.getMysqlCon(),
sql= "SELECT * FROM test WHERE id=%s",data=17)
a1=DStreamInstance.database.insertIntoMysql(
connection=DStreamInstance.database.getMysqlCon(),
sql= "INSERT INTO test (id) VALUES (%s)",data=(17))
'''
5.2 drawPicture类
# encoding:utf-8
__author__ = 'zheng'
from pyecharts import Bar
from pyecharts import EffectScatter
import time
from pyecharts import Pie
from pyecharts import WordCloud
class drawPicture:
def __init__(self):
pass
# bar
def drawBar(self,main_name,sub_name,count,type,data):
bar = Bar(main_name,sub_name)
bar.add(count, type, data)
bar.render("/root/usr/pycharm/picture/"+main_name+"_"+str(time.time())+".html")
#散点图
def drawEffectScatter(self,name,count1,data1,data2,count2,data3,data4):
es = EffectScatter(name)
es.add(count1, data1, data2)
es.add(count2, data3, data4)
es.render("/root/usr/pycharm/picture/"+name+"_"+str(time.time())+".html")
#pie
def drawPie(self,name,type,data):
pie = Pie(name)
pie.add("", type, data, is_label_show=True)
pie.render("/root/usr/pycharm/picture/"+name+"_"+str(time.time())+".html")
def drawWordCloud(self,name,type,data):
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", type, data, word_size_range=[20, 100])
wordcloud.render("/root/usr/pycharm/picture/"+name+"_"+str(time.time())+".html")
'''
if __name__ == '__main__':
a=drawPicture()
a.drawBar("test","test","qqq",["wq","we","dsd"],[12,34,56])
a.drawEffectScatter("testES","qw",[10,12,34,22],[21,21,17,14],"er",[21,31,27,16],[12,27,31,11])
a.drawPie("testPie",["11","qw","ds"],[12,17,13])
a.drawWordCloud("testWordCloud",["eqw","dsd","fsf","cxcx","we","dsads"],[12,34,67,23,11,34])
'''
5.3 drawAndStoreData文件
# encoding:utf-8
from kafkaandSpark.draw import drawPicture
from kafkaandSpark.databaseCon import databaseCon
__author__ = 'zheng'
def userTypeDataDeal(rdd):
key_list,value_list=baseTransformRDD(rdd)
if len(value_list)==2:
#插入数据库
database=databaseCon()
database.insertIntoMysql(
connection=database.getMysqlCon(),
sql= "INSERT INTO type_table (customer,subscriber) VALUES (%s,%s)",
data=(str(value_list[0]),str(value_list[1]))
)
#画图
picture=drawPicture()
name="User_Type"
picture.drawPie("Citi Bike trip:"+name,key_list,value_list)
def userGenderDataDeal(rdd):
key_list,value_list=baseTransformRDD(rdd)
if len(value_list)==2:
#插入数据库
database=databaseCon()
database.insertIntoMysql(
connection=database.getMysqlCon(),
sql= "INSERT INTO gender_table (1_M,2_F) VALUES (%s,%s)",
data=(str(value_list[0]),str(value_list[1]))
)
if len(value_list)>0:
#画图
picture=drawPicture()
name="User_Gender"
picture.drawBar("Citi Bike trip:"+name,"","gender",key_list,value_list)
def userBirthDayDataDeal(rdd):
a=rdd.sortByKey().collect()
#将RDD中的数据取出来
key_list=""
ss=""
value_list=""
key_list1=[]
value_list1=[]
for key,value in a:
if len(key_list)==0:
key_list=str(key)
value_list=str(value)
ss="%s"
else:
key_list=key_list+","+key
value_list=value_list+","+str(value)
ss = ss + ",%s"
key_list1.append(key)
value_list1.append(value)
if len(value_list)>0:
#插入数据库
sql="INSERT INTO gender_table ("+ key_list+") VALUES ("+ss+")"
database=databaseCon()
database.insertIntoMysql(
connection=database.getMysqlCon(),
sql= sql,
data=tuple(value_list1)
)
#画图
picture=drawPicture()
name="User_BirthDay"
picture.drawBar("Citi Bike trip:"+name,"","birthDay",key_list1,value_list1)
def stationStartIDDataDeal(rdd):
key_list,value_list=baseTransformRDD(rdd)
if len(value_list)>0:
#画图
picture=drawPicture()
name="Stattion_ID"
# a.drawBar("test","test","qqq",["wq","we","dsd"],[12,34,56])
picture.drawWordCloud("Citi Bike trip:"+name,key_list,value_list)
def timeDuringDataDeal(rdd):
key_list,value_list=baseTransformRDD(rdd)
if len(value_list)>0:
#画图
picture=drawPicture()
name="Time_During"
picture.drawPie("Citi Bike trip:"+name,key_list,value_list)
def bikeIDDataDeal(rdd):
key_list,value_list=baseTransformRDD(rdd)
if len(value_list)>0:
#画图
picture=drawPicture()
name="Bike_ID"
picture.drawWordCloud("Citi Bike trip:"+name,key_list,value_list)
def baseTransformRDD(rdd):
a=rdd.sortByKey().collect()
#将RDD中的数据取出来
key_list=[]
value_list=[]
for key,value in a:
key_list.append(key)
value_list.append(value)
return key_list,value_list
5.4 dealDStream类
# encoding:utf-8
__author__ = 'zheng'
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils, TopicAndPartition
import sys
from kafkaandSpark.transformData import *
from kafkaandSpark.drawAndStoreData import *
import os
# 设置环境变量
os.environ['SPARK_HOME'] = "/root/usr/spark/spark-2.2.0-bin-hadoop2.7"
sys.path.append("/root/usr/spark/spark-2.2.0-bin-hadoop2.7/python")
class dealDStream:
# 成员函数
batchTime=3
checkpointDirectory="/root/usr/pycharm/checkPointDic"
topic="test"
partition=0
ssc = None
sc = None
sconf =None
context=None
brokers="192.168.79.111:9092"
# *******************************************************************************#
#基础函数,适合于所有数据分析
#初始化函数
def __init__(self,topic="test",partition=0,checkpointdirectory="/root/usr/pycharm/checkPointDic",batchTime=3):
self.checkpointDirectory=checkpointdirectory
self.topic=topic
self.partition=partition
self.batchTime=batchTime
#设定初始偏移量
def getfromOffset(self,start=None):
if start==None:
return None
topicPartion = TopicAndPartition(self.topic,self.partition)
fromOffset = {topicPartion: long(start)}
return fromOffset
#获取链接
#注意,这里getOrCreate函数接收的第二个参数是一个函数,且该函数返回一个ssc,
# 如果直接将ssc作为第二个参数传入则会抱一个错误
def functionToCreateContext(self):
self.sconf=SparkConf()
self.sconf.set('spark.cores.max' , 3)
self.sc=SparkContext(appName="test",conf=self.sconf)
self.ssc=StreamingContext(self.sc,self.batchTime)
self.ssc.checkpoint(self.checkpointDirectory)
return self.ssc
def getConfig(self,appName='KafkaDirectWordCount'):
self.context = StreamingContext.getOrCreate(self.checkpointDirectory, self.functionToCreateContext)
print("Get ssc completed!")
#从连接获取DStream
def getDStream(self,start=None):
kafkaStreams = KafkaUtils.createDirectStream\
(self.context,[self.topic],kafkaParams={"metadata.broker.list": self.brokers}
,fromOffsets=self.getfromOffset(start))
kafkaStreams.pprint()
return kafkaStreams
#启动程序
def startWork(self):
self.context.start() # Start the computation
self.context.awaitTermination() # Wait for the computation to terminate
#********************************************************************************#
#对流数据的分析统计部分
#*********************************************************************************
#关于用户的数据的统计
#无状态部分
def userBirthDay(self,dstream):
sourceStream=dstream
result=sourceStream.map(userBirthDayMap).reduceByKey(lambda x, y: x + y)
# lambda line:(line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")[-2],1)
result.foreachRDD(userBirthDayDataDeal)
result.pprint()
def userGender(self,dstream):
sourceStream=dstream
result=sourceStream.map(userGenderMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(userGenderDataDeal)
result.pprint()
def userType(self,dstream):
sourceStream=dstream
result=sourceStream.map(userTypeMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(userTypeDataDeal)
result.pprint()
#有状态部分
def userBirthDayWithWindow(self,dstream,length=3,step=1):
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(userBirthDayMap).reduceByKey(lambda x, y: x + y)
result.foreachRDD(userBirthDayDataDeal)
#lambda line:(line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")[-2],1)
result.pprint()
def userGenderWithWindow(self,dstream,length=3,step=1):
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(userGenderMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(userGenderDataDeal)
result.pprint()
def userTypeWithWindow(self,dstream,length=3,step=1):
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(userTypeMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(userTypeDataDeal)
result.pprint()
#累计部分
def userBirthDayUpdateState(self,dstream):
sourceStream=dstream
result=sourceStream.map(userBirthDayMap).updateStateByKey(updateFunction)
# lambda line:(line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")[-2],1)
result.foreachRDD(userBirthDayDataDeal)
result.pprint()
def userGenderUpdateState(self,dstream):
sourceStream=dstream
result=sourceStream.map(userGenderMap).updateStateByKey(updateFunction)
result.foreachRDD(userGenderDataDeal)
result.pprint()
def userTypeUpdateState(self,dstream):
sourceStream=dstream
result=sourceStream.map(userTypeMap).updateStateByKey(updateFunction)
result.foreachRDD(userTypeDataDeal)
result.pprint()
#**********************************************************************
#关于station的统计
#无状态部分
def stationStartID(self,dstream):#3 4
sourceStream=dstream
result=sourceStream.map(stationStartIDMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(stationStartIDDataDeal)
result.pprint()
def stationEndID(self,dstream):#7 8
sourceStream=dstream
result=sourceStream.map(stationEndIDMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(stationStartIDDataDeal)
result.pprint()
#有状态部分
def stationStartIDWithWindow(self,dstream,length=3,step=1):#3 4
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(stationStartIDMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(stationStartIDDataDeal)
result.pprint()
def stationEndIDWithWindow(self,dstream,length=3,step=1):#7 8
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(stationEndIDMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(stationStartIDDataDeal)
result.pprint()
#累计部分
def stationStartIDUpdateState(self,dstream):#3 4
sourceStream=dstream
result=sourceStream.map(stationStartIDMap).updateStateByKey(updateFunction)
result.foreachRDD(stationStartIDDataDeal)
result.pprint()
def stationEndIDUpdateState(self,dstream):#7 8
sourceStream=dstream
result=sourceStream.map(stationEndIDMap).updateStateByKey(updateFunction)
result.foreachRDD(stationStartIDDataDeal)
result.pprint()
#*************************************************************************************
#关于时间的统计
#无状态部分
def timeDuring(self,dstream):#7 8
sourceStream=dstream
result=sourceStream.map(timeDuringMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(timeDuringDataDeal)
result.pprint()
#有状态部分
def timeDuringWithWindow(self,dstream,length=3,step=1):#7 8
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(timeDuringMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(timeDuringDataDeal)
result.pprint()
#累计部分
def timeDuringUpdateState(self,dstream):#7 8
sourceStream=dstream
result=sourceStream.map(timeDuringMap).updateStateByKey(updateFunction)
result.foreachRDD(timeDuringDataDeal)
result.pprint()
#****************************************************************************************
#关于单车的统计
#无状态部分
def bikeID(self,dstream):#7 8
sourceStream=dstream
result=sourceStream.map(bikeIDMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(bikeIDDataDeal)
result.pprint()
#有状态部分
def bikeIDWithWindow(self,dstream,length=3,step=1):#7 8
sourceStream1=dstream
sourceStream=sourceStream1.window(length*self.batchTime,step*self.batchTime)
result=sourceStream.map(bikeIDMap).reduceByKey(lambda x,y:x+y)
result.foreachRDD(bikeIDDataDeal)
result.pprint()
#累计部分
def bikeIDUpdateState(self,dstream):#7 8
sourceStream=dstream
result=sourceStream.map(bikeIDMap).updateStateByKey(updateFunction)
result.foreachRDD(bikeIDDataDeal)
result.pprint()
# 程序入口
if __name__ == '__main__':
DStreamInstance=dealDStream(batchTime=3)
DStreamInstance.getConfig()
dstream =DStreamInstance.getDStream(start=None)
#user
DStreamInstance.userBirthDay(dstream)
DStreamInstance.userGender(dstream)
DStreamInstance.userType(dstream)
DStreamInstance.userBirthDayWithWindow(dstream)
DStreamInstance.userGenderWithWindow(dstream)
DStreamInstance.userTypeWithWindow(dstream)
DStreamInstance.userBirthDayUpdateState(dstream)
DStreamInstance.userGenderUpdateState(dstream)
DStreamInstance.userTypeUpdateState(dstream)
#station
DStreamInstance.stationEndID(dstream)
DStreamInstance.stationStartID(dstream)
DStreamInstance.stationEndIDWithWindow(dstream)
DStreamInstance.stationStartIDWithWindow(dstream)
#时间
DStreamInstance.timeDuring(dstream)
DStreamInstance.timeDuringWithWindow(dstream)
DStreamInstance.timeDuringUpdateState(dstream)
DStreamInstance.stationEndIDUpdateState(dstream)
DStreamInstance.stationStartIDUpdateState(dstream)
#单车
DStreamInstance.bikeID(dstream)
DStreamInstance.bikeIDWithWindow(dstream)
DStreamInstance.bikeIDUpdateState(dstream)
DStreamInstance.startWork()
5.5 producer类
# encoding:utf-8
__author__ = 'zheng'
from kafka import KafkaProducer
import random,time
class producer:
#数据源
fileResource=[
"2014-07 - Citi Bike trip data.csv",
"2014-08 - Citi Bike trip data.csv",
"201409-citibike-tripdata.csv",
"201410-citibike-tripdata.csv",
"201411-citibike-tripdata.csv",
"201412-citibike-tripdata.csv"
]
#kafka连接
producerCon = KafkaProducer(bootstrap_servers='192.168.79.111:9092')
#初始化函数
def __init__(self):
pass
#从数据源读取数据发送到kafka msgNumber用于调节发送速率
def getMessage(self,msgNumber):
for sourceFileOne in self.fileResource:
f = open("/root/usr/pycharm/data/"+sourceFileOne)
print(sourceFileOne+"is sending!")
randomFlag=0
for line in f.readlines():
randomFlag+=1
if line.find("tripduration")==-1 or line.find(",")!=-1:
msg=line.replace("\n","").replace("\"","")
self.producerCon.send('test', msg)
if randomFlag==msgNumber:
print(str(msgNumber)+" messages are sended!")
time.sleep(random.uniform(0, 1) )
randomFlag=0
return 0
if __name__ == '__main__':
test=producer()
test.getMessage(3)
5.6 transformData文件
# encoding:utf-8
__author__ = 'zheng'
def userBirthDayMap(line): #1899 1998 [1890 2010]
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")
if len(line)!=0 and len(line)>4 and line[-2]!="\N" :
result=int(line[-2])
if result>=1890 and result<1900:
return ("[1890,1900)",1)
if result>=1900 and result<1910:
return ("[1900,1910)",1)
if result>=1910 and result<1920:
return ("[1910,1920)",1)
if result>=1920 and result<1930:
return ("[1920,1930)",1)
if result>=1930 and result<1940:
return ("[1930,1940)",1)
if result>=1940 and result<1950:
return ("[1940,1950)",1)
if result>=1950 and result<1960:
return ("[1950,1960)",1)
if result>=1960 and result<1970:
return ("[1960,1970)",1)
if result>=1970 and result<1980:
return ("[1970,1980)",1)
if result>=1980 and result<1990:
return ("[1980,1990)",1)
if result>=1990 and result<2000:
return ("[1990,2000)",1)
if result>=2000 and result<2010:
return ("[2000,2010)",1)
return("[9999,9999)",1)
def userGenderMap(line):
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").replace("\r","").split(",")
if len(line)!=0 and len(line)>4 :
result=line[-1]
return (str(result),1)
return("None",1)
def userTypeMap(line):
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")
if len(line)!=0 and len(line)>4 :
result=line[-3]
return (str(result),1)
return("None",1)
def stationStartIDMap(line): #3 4
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")
if len(line)!=0 and len(line)>4 :
result=str(line[3])+"_"+str(line[4])
return (str(result),1)
return("None",1)
def stationEndIDMap(line): #7 8
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")
if len(line)!=0 and len(line)>4 :
result=str(line[7])+"_"+str(line[8])
return (str(result),1)
return("None",1)
def timeDuringMap(line): #[0,2500] 0 500 1000 1500 2000 2500
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")
if len(line)!=0 :
result=int(line[0])
if result>=0 and result<500:
return( "[0,500 )" ,1)
if result>=500 and result<1000:
return ("[500,1000)",1)
if result>=1000 and result<1500:
return ("[1000,1500)",1)
if result>=1500 and result<2000:
return ("[1500,2000)",1)
if result>2000 and result<2500:
return ("[2000,2500)",1)
return("[9999,9999)",1)
def bikeIDMap(line):
if line!=None and len(line)>1:
line=line[1].encode('unicode-escape').decode('string_escape').replace("\"","").split(",")
if len(line)!=0 and len(line)>6:
result=line[-4]
return (str(result),1)
return("None",1)
def updateFunction(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount)