以前,从照片里抠出人像去掉背景,是要到处求PS大神帮忙的。大神时间有限,抠图这种消耗大量时间又不炫技的事,简直遭人嫌弃。
现在好了,你自己可以成为有求必应的AI大神,天天帮妹纸抠图。
TowardsDataScience博客最近发布了一篇详细的教程,教你用深度学习移除照片背景。量子位搬运过来翻译了一下:

我们要移除怎样的背景呢?这是一个重要的问题,因为一个模型在目标和角度等方面表现得越具体,前后景的分离质量也越好。
最初,我们想构建一个通用的背景移除器,能自动识别所有类型图像的前景和背景。但是看到第一个训练模型的效果后,我们决定把应用目标调整到一组特定图像中。
因此,我们专注于处理自拍照和人像。

△ 为(差不多是人类吧)自拍移除背景
自拍照是一种前景突出且集中的图像,保证目标(脸+上身)和背景之间有良好分离,而且它以一个相当恒定的角度来拍摄同一个目标(或人),其中前景可包含一个或多个“人物”。
考虑到这些假设,我们着手于研究相关背景、实施可行方案以及训练数小时的模型,以创建出一种能一键到位的背景移除工具。
我们的时间主要花在了训练模型上,但是也没有低估正确部署的重要性。良好的分割模型仍不能与分类模型(如SqueezeNet)一样紧凑,我们还主动检查了服务器和浏览器的部署选项。
如果你想进一步了解有关产品部署过程中的更多细节,服务器端见文末相关链接1,客户端见链接2。
下面将会详细介绍相关模型的选择及训练过程。
语义分割
在衡量我们的任务与哪类深度学习和计算机视觉的研究相近时,很快得出最佳选择应该是语义分割任务。
其他研究方向,如深度检测分离方法,也具有一定的借鉴意义,但似乎并不是很切合本项目。
语义分割、图像分类与目标检测是目前三大最为热门的计算机视觉研究领域。分割实际上也是一种分类任务,将每个像素划分到某一类中。
与图像分类或目标检测有所不同,分割模型真正展现了一些计算机对图像的“理解力”,不仅提出了“这张图中有一只猫”,而且在像素级上指出了猫的位置和特性。
那分割任务的实现原理是什么?为了更好地理解它,我们查阅了这个领域的一些早期研究工作。
最早的想法是采用一些已有的分类网络,如VGG和Alexnet。VGG网络于2014年提出,是一种用于图像分类的先进模型,由于其简单直观的结构,目前十分有用。在检查VGG低网络层时,我们注意到分类目标周围的激活值很高。高网络层有着更高的激活值,但是由于经过重复的池化操作,其本质变得粗糙。
基于这些理解,我们猜测,对分类模型进行一些调整后,也可用于目标定位或分割。
早期的语义分割研究是和分类算法一起出现的。文末链接3的文章中,展示了一些利用VGG网络得到的粗糙分割结果。

△ 输入图像
高网络层的激活情况:
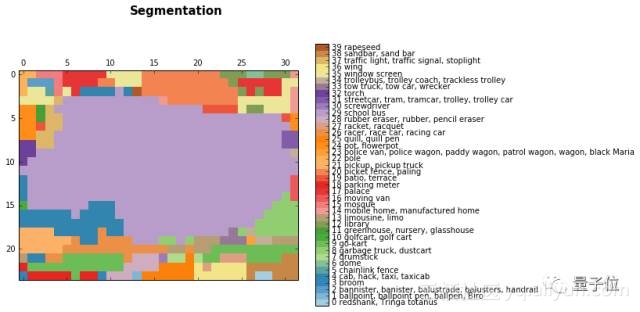
△ 公交车图像的分割效果,浅紫色(29)为公交车类别
进行双线性上采样后:
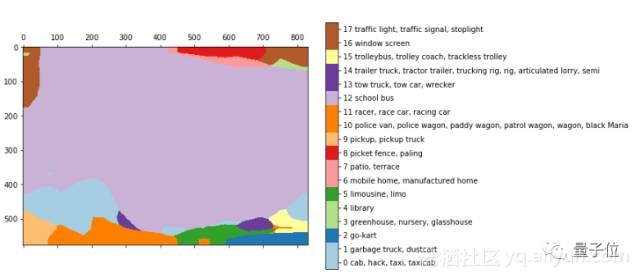
△ 更为平滑的激活情况
得到这些结果,只需将全连接层转换回(或保持)其原始形式,保持其空间特征,进而获得一个全卷积网络。
在上面例子中,将一个分辨率为768×1024的图像输入到VGG,获得一个大小为24×32×1000的网络层。其中多次池化后的图像大小为24×32,网络类别数为1000,据此可导出上面的分割效果图。
为了使预测效果更平滑,研究人员使用了双线性上采样层。
在FCN论文(链接4)中,研究人员改进了上述思路。沿着网络方向,把一些层连接在一起,这提供了更丰富的解释。根据上采样率把它们分别命名为FCN-32、FCN-16和FCN-8。
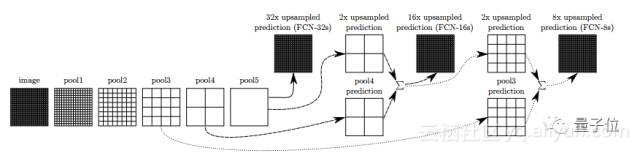
△ FCN网络层间连接示意图
在网络层之间添加一些跳跃连接(skip connection),允许编码器从原始图像中预测出更精细的信息。后续的训练可能会大幅提高效果。
这种连接方式并不像所估计的那么糟糕,也证实了深度学习方法在语义分割领域确实具有发展空间。

△ FCN分割效果(图来自原论文)
FCN网络提出了分割的概念,之后研究人员为此任务尝试了不同的结构。但是,其主要思路保持相似,即借鉴已有结构、加入上采样和添加跳跃连接,这些方法仍在新模型中表现突出。
关于语义分割的发展综述可以移步量子位编译过的“语义分割中的深度学习方法全解:从FCN、SegNet到各版本DeepLab”和“卷积神经网络在图像分割中的进化史:从R-CNN到Mask R-CNN”,可以看出大多数网络都使用了编码器-解码器结构。
回到本项目
进行一些调研后,我们选定了三种可使用的模型,分别是FCN、U-net和Tiramisu(不要往甜品提拉米苏上想……它是极深的编码器-解码器结构,详情见文末链接5)。我们也考虑了mask-RCNN网络,但其网络实现似乎超出了本项目的范围。
FCN的效果似乎没有预想的那么好,所以我们不考虑这个模型。我们还测试了另外两个提到的模型,发现Tiramisu网络在CamVid数据集上的分割效果较优,而且U-net也展现了其紧凑性和实时应用的优势。
在网络实现上,U-net网络可利用keras库直接实现,Tiramisu网络也是可实现的。开始时,我们使用了Jeremy Howard在旧金山大学深度学习课程中最后一节中给出的Tiramisu网络代码实现(链接6)。
掌握这两个网络后,我们开始利用一些数据集来训练模型。在我们首次尝试Tiramisu网络后,我们发现该模型有很大的应用潜力,因为它能捕捉图像中的锐利边缘。另一方面,U-net的效果不佳,分割图不忍直视。

△ Tiramisu和U-net分割效果比较
确定数据集
在设定好模型后,我们开始寻找合适的数据集。与分类和检测数据集不同,分割数据并不常见,而且不可能通过人工标注来实现。常见的分割数据集有COCO数据集(包括大约8万张图像,有90个类别)、VOC pascal数据集(包括1.1万张图像,有20个类别)以及较新的ADE20K数据集。
COCO:http://mscoco.org/
VOC pascal:http://host.robots.ox.ac.uk/pascal/VOC/
ADE20K:http://groups.csail.mit.edu/vision/datasets/ADE20K/
我们选用COCO数据集,因为该数据集中包含更多的“人”像,这是本项目的目标类别。
根据实际任务,我们仔细考虑了是只使用极其相关的图像类别,还是使用更加通用的数据集。
一方面,使用一个具有更多图像和类别的通用数据集会使模型具有更好的泛化能力;另一方面,一晚上的训练时间就能遍历15万张图片。如果将整个COCO数据集输入到模型,每个图像平均会被输入两次,因此最好进行适当修剪。此外,这样做可得到一个使任务目标更集中的模型。
还需要提到,Tiramisu网络最初是在CamVid数据集上训练的,但是CamVid数据集存在一些缺点,最主要是其图像非常单调,所有图像都是从汽车上拍的路面图。这就很容易理解,用这样的数据集来训练模型,即使图像中包含人物,对此任务也没有任何好处,所以简单实验后,我们决定寻找更合适的数据集。

△ CamVid数据集的一些图像
COCO数据集提供了可直接调用的API接口,据此我们可以准确地知道每张图像中的物体类别(根据预设定的90个类别)。
经过几次实验后,我们决定稀释此数据集:
首先我们挑出带有人物的所有样本,得到4万张图像;然后再删去图中有多个人物的样本,留下只有1人或2人的图像,这是训练模型的合适数据集;最后只留下人物形象占据20%~70%面积的图像样本,删去人物形象过小的图像或是一些奇怪的畸形样本。
最终的数据集包含1.1万张图像,在这个阶段样本量已经足够。

△ 左边为优良图像;中间包含太多人物;右边的人物形象过小。
Tiramisu模型
上面已经提到,Jeremy Howard的课程中详细地介绍了Tiramisu模型。它的全名为“100层Tiramisu模型”,听起来像是一个庞大的模型,实际上只有900万个参数,十分紧凑。相比之下,VGG-16网络有多达1.3亿个参数。
DenseNet是一种新提出的图像分类模型,其所有网络层都是互连的。Tiramisu模型基于DenseNet发展起来的,而且与U-net网络类似,向上采样层添加了跳跃连接。
你应该还记得,这种结构与FCN论文中的提出思路是一样的,即使用分类结构和上采样层,并添加跳跃连接来微调网络。
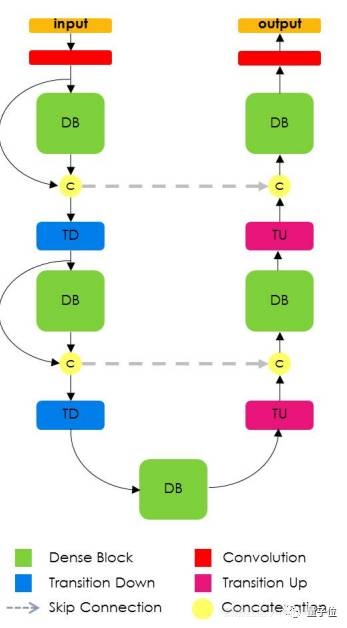
△ 经典的Tiramisu结构
DenseNet模型可以看作是Resnet模型的一种自然演化版本,它不只是“记住”了下一网络层之前的每个网络层,而是记住了整个模型中的所有网络层。这些连接称作快捷连接(highway connections),它导致了滤波器数量的逐层膨胀,前后数量差定义为“增长率”。
Tiramisu模型的增长率为16,因此每层都增加16个新的滤波器,直到获得具有1072个滤波器的网络层。你可能会想,100层Tiramisu模型应该具有1600个滤波器,可是实际中利用上采样层去掉了一些滤波器。
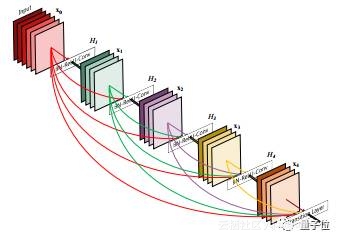
△ Densenet模型示意图,低层滤波器堆叠后贯穿整个模型。
模型训练
我们使用原论文中的默认参数来训练本模型,分别是标准的交叉熵损失和RMSProp优化策略(学习率为0.001和小衰减值)。
在1.1万张图像中,70%分为训练集,20%分为验证集,10%分为测试集。
以下所有图像均来源于上面设定的测试集中。
为了使本项目训练方案与原论文保持一致,我们将epoch设为500张图像,这样也能在每次结果改进后定期保存模型,因为原论文中使用的CamVid数据集包含少于1000张图像,而我们拥有更大的训练数据集。
此外,我们只训练了两个类别,分别是背景和人物,而原论文中共有12个类别。我们先尝试训练COCO数据集中的一些类别,但是发现对最终的训练效果没有太大的提升。
数据问题
数据集中的一些缺陷样本影响了评估分值:
1.动物。模型有时会分割出动物图像,这导致了IoU(intersect over union)值降低。把动物添加到分割任务中,不管是同一个类别或作为新类别,都可能提高模型性能。
2.身体部位。我们通过编程过滤得到本项目数据集,因此无法判断人物图像包含有整个人像,还是只出现某些部位,如手或者脚。这些身体部位图像不属于本项目范围,但在数据集中仍然存在。

△ 一张用手拿着食物逗猫的照片,属于缺陷样本。
3.手持物体。数据集中的许多图像都是有关运动的,经常会出现棒球棒、网球拍和滑雪板等装备。在分割此类物体时,训练模型会弄混。和第一种缺陷相同,将它们归入同一类或是作为新类别,都将有助于提高模型性能。

△ 手持运动器材的人物图像
4.粗糙的真实标注。COCO数据集以多边形进行标注,而不是精确到像素级。这种精度有时满足要求,但有些图像的真实标注非常粗糙,可能会阻碍模型的精细化学习。

△ 真实标注很粗糙的图像示例
结果
我们对模型结果很满意,但是还不够完美:模型在测试集上的IoU值达到84.6,目前最高可达85。
要稳定到这个值很困难,因为对不同数据集和分割类别,性能略有波动。有些类别本身较容易划分,如房屋和道路,大多数模型能轻松达到IoU值为90的效果。
更具挑战性的类别为树木和人类,大多数模型分割这两个类别时,一般只能达到IoU值约为60的效果。
为了估计困难程度,本项目构建的网络只专注于单一类别的特定类型图像。
我们希望这个模型能投入到实际应用中,目前的性能仍不满足上线部署的要求。但是我们认为此时应该先停下来讨论所得结果,因为大约有一半图像取得了良好的分割效果。
下面是一些良好的示例,体现了模型的分割性能:



△ 左边为原图像,中间为真实标注,右边为测试分割效果
调试与记录
在训练神经网络时,有个重要内容叫做调试。在刚开始工作时,很想直接拿到数据和神经网络,就开始训练,看看会得到什么样的输出效果。然而,我们发现,跟踪每次变化非常重要,需要自主制定工具来检查每个步骤中的输出结果。
下面是一些常见的问题,以及应对方法。
1. 早期问题。模型可能还没开始训练,这可能是存在一些本质原因,或是预处理过程出现错误,如忘记标准化某个数据块。总之,简单的可视化输出能让你更快找出问题,这方面的更多内容可参考“神经网络中37个常见问题”(链接7)。
2. 调试网络本身。在确保没有出现关键问题后,网络将会根据预定义的损失函数和指标开始训练。在分割过程中,主要评估指标为IoU值(intersect over union)。经过几次尝试后,我们决定使用IoU值作为模型的主要指标,而不是先前的交叉熵损失。另一个有用的操作为在每个epoch输出当前模型的预测效果,链接8给出了调试机器学习模型的几个建议。请注意,IoU值不是keras中标准的损失函数,但是很容易找到一些开源代码。我们使用了shgidi的代码(链接9)来绘制出每个epoch的损失值和模型预测效果。
3. 机器学习版本控制。在训练模型时,要确定很多参数,其中有些很难理解。我们也还没找到合适的方法,只能贴出我们的详细参数单,并利用keras回调功能自动保存最佳模型(见下文)。
4. 调试工具。在完成上述工作后,我们可以检查下每步结果,但是不能无间断地检查。因此,最重要的是要将上述步骤结合在一起,并创建一个Jupyter手册,这能让我们无间断地加载每个模型和每张图像,并快速地检查所有结果。通过这样,我们可以很容易地分析出模型间的差异、未知误区以及其他问题。
通过参数调整和额外训练,逐步提高了模型性能。

△ 从左到右,模型性能有很大提升。
为了保存目前在验证集上具有最佳IoU值的模型,我们利用了keras库中的callbacks函数。
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]除了对可能的代码错误进行调试外,我们还注意到,模型失误是“可预测的”,如把身体的一部分“切掉”、人物主体被“侵蚀”、身体部位不必要的延伸、较弱的光线、图像质量较差以及一些其他细节。
在添加不同数据集中的特定图像后,已经解决了这里面的一些问题,但是待解决的剩余问题仍然是一个很大的挑战。为了提升后续模型的分割效果,我们将针对一些“困难”(效果不佳)的图像使用图像增强操作。
在上面,我们已经提到这个问题,即模型对部分数据集的处理失误。下面给出一些具体的模型失误例子。
1. 衣服。很深或很浅的衣服有时会被理解为背景;
2. “侵蚀”。即使是优良结果,人物主体也会出现“侵蚀”。

△ 主体出现“侵蚀”的例子
3. 光线。图像中能经常见到弱光线和模糊的样本,但是COCO数据中没有这种情况。因此,除了要处理模型中这些常见问题外,我们还不能解决更高难度的图像集。这可通过获取更多数据和额外加入数据增强,来改进模型效果。同时,最好不要在弱光环境下使用这个应用程序。

△ 弱光条件下的图像分割效
未来展望
更深入的训练
在训练数据上训练300个epoch后,得到了这个产品模型。在此期间,该模型开始出现过拟合效应。我们在临近产品发布时才得到这些结果,因此还没有结合数据增强的基本操作。
将图像大小调整为224X224后,我们开始训练该模型。接下来,会使用更多的数据和更高分辨率的图像来训练模型,以期提高效果,其中COCO数据集中的原始图像大小约为600X1000。
CRF和其他增强方法
在某些阶段,我们发现模型在处理人物边缘时存在噪声。CRF方法(条件随机场)可以用来改进这一方面。
博文(链接9)中结合CNN网络和CRF方法实现了一些案例。可是,这种方法不适用于本项目,也许当结果更粗糙的时候会有所提升。
修边
即使在目前结果中,分割效果仍不完美。对头发、精致的衣服、树枝和其他精细物体的分割效果仍然有提升空间,实际上是因为实际分割中不包含这些细节。分
割如此细微图像的任务称为修边(Matting),这是一个不平常的挑战。下面是修边研究的最新成果,在今年年初发表在NVIDIA会议上。
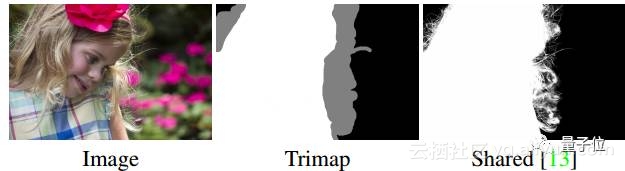
△ 修边示例,输入也包括中间的trimap图。
修边任务与图像处理的其他相关任务不同,因为其输入不仅包括原图像,还包括一个trimap图(给出图像边缘的粗略划分,包括前景、背景和待求未知区域)。这样,就将修边任务成了一种“半监督”问题。
我们使用模型得到的分割图作为输入的trimap图,尝试实现修边操作,但是未达到显著效果。
另一个问题,是缺乏合适的训练数据集。
总结
正如开头提到的,我们的目标是建立一个有意义的深度学习产品。参考链接1和链接2中的教程,部署任务变得更容易和更快捷。另一方面,训练出一个合适模型相当复杂,特别是想要尽快得到最佳模型时,需要更仔细的规划、调试和记录结果。
要平衡好研究和尝试新事物之间,以及单调训练和改进之间的关系,是不容易的。由于使用深度学习方法,我们总会感觉,只需简单改动,就能得到理想的最佳模型,或许一次搜索或某篇论文就会指引我们找到它。但在实际中,真实的改进效果往往是从先前模型中不断“挤出”新思路。如上所述,我们仍觉得,根据已有工作还可发展出很多新想法。
总而言之,我们在这个工作中获得了很多乐趣,这对几个月前的我们像科幻小说一样。非常希望能和大家一起讨论或解答相关问题
相关链接
1. 服务器端产品部署:
https://medium.com/@burgalon/deploying-your-keras-model-35648f9dc5fb
2. 客户端产品部署:
https://becominghuman.ai/deploying-your-keras-model-using-keras-js-2e5a29589ad8
3.利用VGG网络实现图像分割:
https://warmspringwinds.github.io/tensorflow/tf-slim/2016/11/22/upsampling-and-image-segmentation-with-tensorflow-and-tf-slim/
4.FCN网络原论文:
https://arxiv.org/pdf/1411.4038.pdf
5. Tiramisu网络论文:
https://arxiv.org/pdf/1611.09326.pdf
6. Tiramisu网络的代码实现:
http://files.fast.ai/part2/lesson14/
7. 神经网络中37个常见问题:
https://blog.slavv.com/37-reasons-why-your-neural-network-is-not-working-4020854bd607
8. 如何调试神经网络:
https://hackernoon.com/how-to-debug-neural-networks-manual-dc2a200f10f2
9. 结合CNN网络和CRF方法的图像分割:
https://warmspringwinds.github.io/tensorflow/tf-slim/2016/12/18/image-segmentation-with-tensorflow-using-cnns-and-conditional-random-fields/
10. 在你自己做出背景移除器之前,可以试试作者们的demo:
https://greenscreen-ai.boorgle.com/
最后,量子位想说,本教程适合学习,如果你只是想通过抠图讨女朋友欢心,Prisma团队后来推出的新应用Sticky是个不错的选择
— 完 —