|
1
2
3
4
5
6
7
|
序列化的概念很简单。内存里面有一个数据结构,你希望将它保存下来,重用,或者发送给其他人。你会怎么做?嗯, 这取决于你想要怎么保存,怎么重用,发送给谁。很多游戏允许你在退出的时候保存进度,然后你再次启动的时候回到上次退出的地方。(实际上, 很多非游戏程序也会这么干。) 在这个情况下, 一个捕获了当前进度的数据结构需要在你退出的时候保存到磁盘上,接着在你重新启动的时候从磁盘上加载进来。
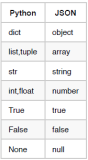
什么东西能用pickle模块存储?
–所有Python支持的 原生类型 : 布尔, 整数, 浮点数, 复数, 字符串, bytes(字节串)对象, 字节数组, 以及 None.
–由任何原生类型组成的列表,元组,字典
–由任何原生类型组成的列表,元组,字典和集合组成的列表,元组,字典和集合(可以一直嵌套下去,直至Python支持的最大递归层数).
–函数,类,和类的实例(带警告)。
|
|
1
2
3
4
5
6
7
8
9
10
11
|
#!/usr/bin/env python
import
pickle
account_info = {
'8906143632'
:[
'alex3714'
,
15000
,
15000
],
'8908223631'
:[
'rachel'
,
9000
,
9000
]
}
f=file(
'account.pkl'
,
'wb'
)
pickle.dump(account_info,f)
f.close()
|
|
1
2
3
4
5
6
7
8
9
|
#!/usr/bin/env python
import
pickle
pkl_file = file(
'account.pkl'
,
'rb'
)
account_list = pickle.load(pkl_file)
pkl_file.close()
print account_list
|
|
1
2
3
|
xpleaf@xpleaf-machine:/mnt/hgfs/Python/day3$ python pickle_w.py
xpleaf@xpleaf-machine:/mnt/hgfs/Python/day3$ python pickle_r.py
{
'8908223631'
: [
'rachel'
,
9000
,
9000
],
'8906143632'
: [
'alex3714'
,
15000
,
15000
]}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
xpleaf@xpleaf-machine:/mnt/hgfs/Python/day3$ cat account.pkl
(dp0
S
'8908223631'
p1
(lp2
S
'rachel'
p3
aI9000
aI9000
asS
'8906143632'
p4
(lp5
S
'alex3714'
p6
aI15000
aI15000
as
.
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/usr/bin/env python
import
pickle
account_info = {
'8906143632'
:[
'alex3714'
,
15000
,
15000
],
'8908223631'
:[
'rachel'
,
9000
,
9000
]
}
f=file(
'account.pkl'
,
'wb'
)
pickle.dump(account_info,f) #第一次状态保存
account_info[
'8908223631'
][
0
] =
'xpleaf'
#修改字典中的某项内容
pickle.dump(account_info,f) #第二次状态保存
f.close()
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
xpleaf@xpleaf-machine:/mnt/hgfs/Python/day3$ python pickle_w.py
xpleaf@xpleaf-machine:/mnt/hgfs/Python/day3$ cat account.pkl
(dp0
S
'8908223631'
p1
(lp2
S
'rachel'
p3
aI9000
aI9000
asS
'8906143632'
p4
(lp5
S
'alex3714'
p6
aI15000
aI15000
as
.(dp0
S
'8908223631'
p1
(lp2
S
'xpleaf'
#对比只保存一次状态的情况,这里多了修改的内容
'xpleaf'
p3
aI9000
aI9000
asS
'8906143632'
p4
(lp5
S
'alex3714'
p6
aI15000
aI15000
as
.
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
>>>
import
pickle
>>> f = file(
'account.pkl'
)
>>> acc1 = pickle.load(f) #反序列化读取第一次状态的内容
>>> acc2 = pickle.load(f) #反序列化读取第二次状态的内容
>>> acc3 = pickle.load(f) #无第三次状态内容,读取失败
Traceback (most recent call last):
File
"<stdin>"
, line
1
,
in
<module>
File
"/usr/lib/python2.7/pickle.py"
, line
1378
,
in
load
return
Unpickler(file).load()
File
"/usr/lib/python2.7/pickle.py"
, line
858
,
in
load
dispatch[key](self)
File
"/usr/lib/python2.7/pickle.py"
, line
880
,
in
load_eof
raise EOFError
EOFError
>>> acc1
{
'8908223631'
: [
'rachel'
,
9000
,
9000
],
'8906143632'
: [
'alex3714'
,
15000
,
15000
]}
>>> acc2
{
'8908223631'
: [
'xpleaf'
,
9000
,
9000
],
'8906143632'
: [
'alex3714'
,
15000
,
15000
]}
|
|
1
2
3
4
5
6
7
|
>>> acc1
{
'8908223631'
: [
'rachel'
,
9000
,
9000
],
'8906143632'
: [
'alex3714'
,
15000
,
15000
]}
>>> pickle.dumps(acc1)
"(dp0\nS'8908223631'\np1\n(lp2\nS'rachel'\np3\naI9000\naI9000\nasS'8906143632'\np4\n(lp5\nS'alex3714'\np6\naI15000\naI15000\nas."
>>> c = pickle.dumps(acc1)
>>> pickle.loads(c)
{
'8908223631'
: [
'rachel'
,
9000
,
9000
],
'8906143632'
: [
'alex3714'
,
15000
,
15000
]}
|