本次直播视频精彩回顾,戳这里!
直播涉及到的PPT,戳这里!
演讲嘉宾简介:
郑涔(花名:明俨) 阿里云技术专家,2011年加入阿里,曾参与TFS、Tengine研发,目前主要参与阿里云MongoDB云数据库服务研发,主要关注分布式存储、数据库等领域。
本篇文章来自于阿里云技术专家郑涔(明俨)在2018年《Redis、MongoDB、HBase大咖直播大讲堂》技术直播峰会中的分享,该分享整体由四个部分构成:
1、MongoDB备份恢复
2、阿里云MongoDB备份恢复
3、阿里云MongoDB Sharding备份恢复
4、阿里云MongoDB物理热备份恢复
初来乍到——MongoDB备份恢复
MongoDB备份恢复在备份方法上总体来说分为两部分:逻辑备份和物理备份。
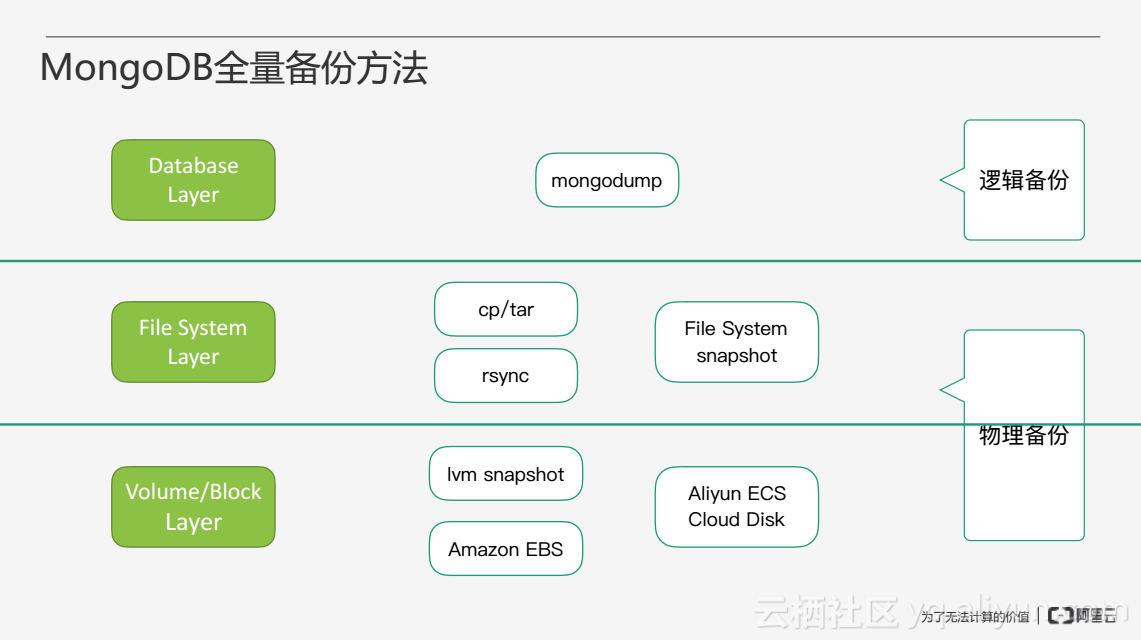
逻辑备份就是通过mongodump和mongorestore这两个工具在数据库层将MongoDB的数据进行导出和导入。物理备份作用于更接近底层一些,例如作用在文件系统上,通过cp和tar等文件系统工具,将MongoDB的物理文件拷贝走进行备份。物理备份还有一种方式是通过逻辑卷这一层或者块设备这一层更为底层的部分进行备份,例如配置一个逻辑卷采用lvm snapshot的方法去做快照,或者利用像阿里云的ECS云服务器上的云盘的快照功能,从而实现物理备份。
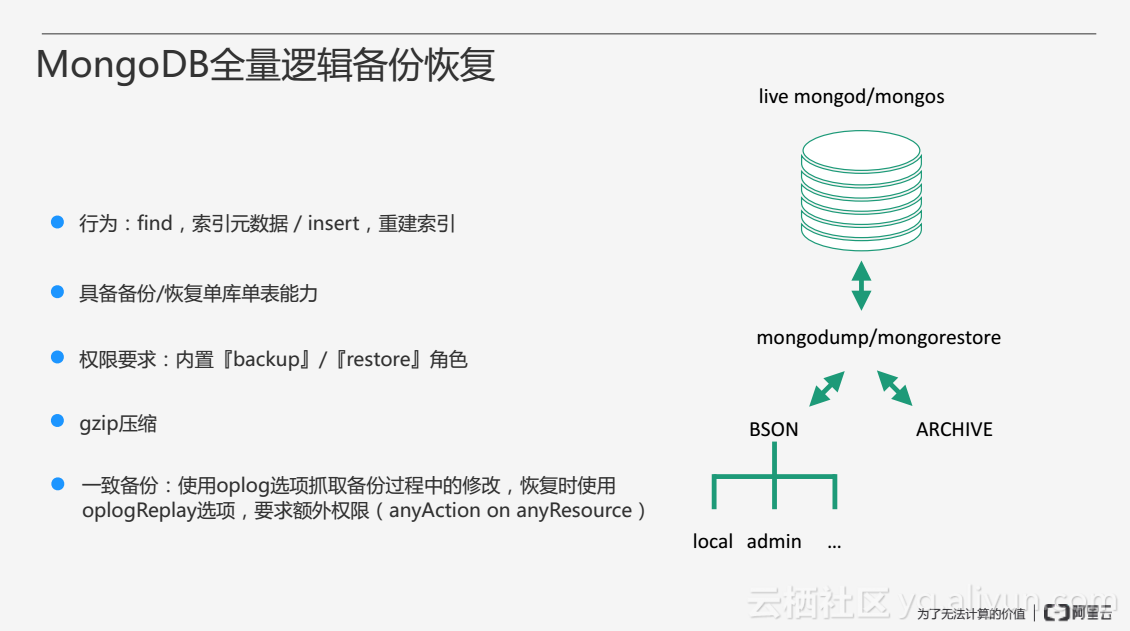
MongoDB全量逻辑备份恢复是通过mongodump和mongorestore这两个工具来实现的,这两个工具不仅可以作用在正在运行的mongod进程上,也可以作用在Sharding的mongos进程上,把整个数据库的数据进行导入导出。全量逻辑备份恢复可以输出为两种格式:第一种为BSON格式,以这种方式导出之后可以看到本地磁盘上会有很多目录,每一个数据库都会有各自的BSON格式的数据;第二种为归档的格式,即把所有数据库的数据输出成一个文件,可以方便地实现流式备份和恢复。
全量逻辑备份的基本机制是通过数据库层的一些接口来实现的,在dump的过程中通过数据库find的方法,将数据库中的数据全部查询出来,如果是索引,导出的只是一些元数据,例如索引建在哪个字段上、什么类型的索引、索引有哪些选项这些元数据,并没有把索引的数据本身导出来,在恢复时通过insert方法重新将数据插回到数据库当中。在恢复的过程中需要重建索引,如果索引的数据量非常大,重建索引的过程将花费很长的时间,这是全量逻辑备份比较大的问题。
全量逻辑备份恢复的一大优点,即备份和恢复单库单表的能力,方便于某些场景的应用,例如紧急状态下需要恢复某一数据库的某一个表,此时不需要下载整个全量的数据备份,只需单独把想要恢复的表进行恢复即可。
全量逻辑备份通过数据库接口访问数据库,如果数据库配置了认证,需要账号和密码进行访问时会有一些权限的要求,可以通过MongoDB内置的backup和restore两个角色进行备份和恢复。
此外,全量逻辑备份可以指定进行gzip压缩,从而减少数据备份的大小,节省存储成本。
在MongoDB全量逻辑备份过程中数据库可以接受外部正常的读写,使用oplog选项可以抓取备份过程中的修改,从而获取一致的备份,确保数据备份的过程中,对数据的修改也会进行备份。在恢复时需要使用oplogReplay选项,这要求一个anyAction on anyResource的较高的额外权限,这点需要注意。
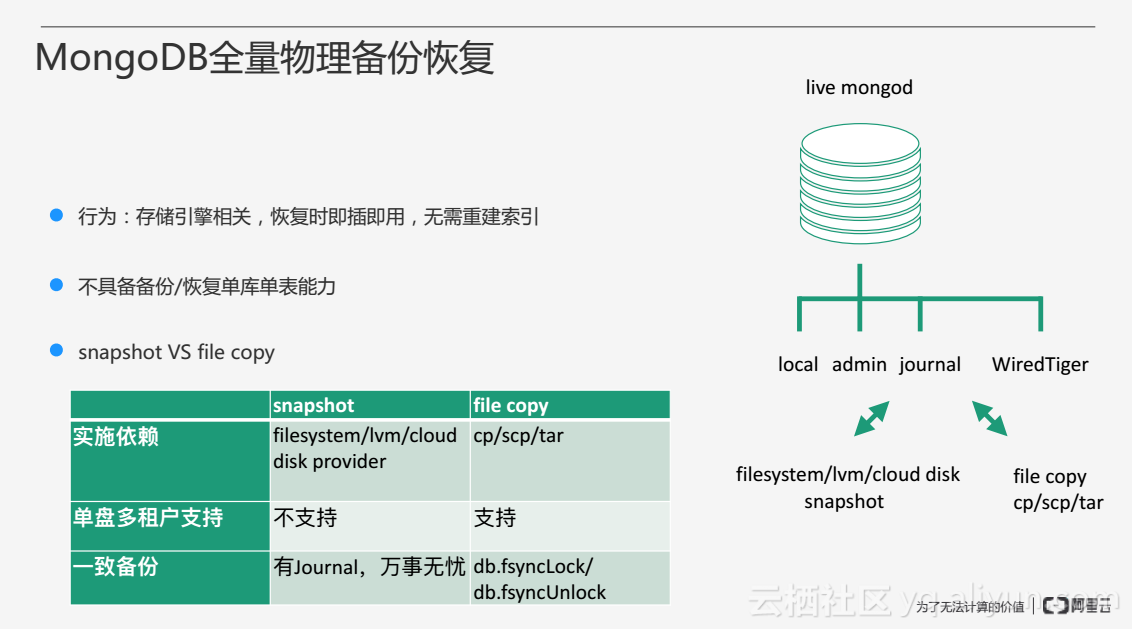
MongoDB全量物理备份恢复通过某些手段将物理文件拷贝走进行备份,由于MongoDB可以支持多个存储引擎,物理文件与存储引擎的存储布局相关,所以物理备份恢复无法做到跨存储引擎的备份恢复,例如使用WiredTiger的存储引擎备份的数据只能恢复成WiredTiger,不能恢复成其他的存储引擎。另外物理备份有一个很大的好处是,由于备份时将所有的数据进行备份,在恢复的过程中不需要重建索引,只需要将备份数据下载下来,启动进程即可使用,相对全量逻辑备份更为高效。
然而全量物理备份的不足之处在于,它不具备备份和恢复单库单表的能力,文件之间相互关联,无法将某一个数据库的单独文件提取恢复出来。
全量物理备份方法通常可以分为两大类:第一类是通过一些系统组件的snapshot快照功能来实现备份,对系统组件有些依赖,在单盘多租户的情况下,无法做到对单块盘上每一个MongoDB实例单独进行备份,另外获取一致备份则依赖于开启MongoDB的Journal功能,Journal可以实现宕机恢复,从而可以轻松做到一致备份;第二类是使用文件拷贝这种简单的方式通过文件系统进行物理备份,由于可以做到目录级的拷贝,因此支持单盘多租户的数据拷贝,但是有个很大的问题是要获取一致的备份需要在文件拷贝开始之前执行db.fsyncLock()的命令,即对MongoDB加一个全局写锁,在整个备份的过程中数据库无法提供服务,等物理文件拷贝完毕后再执行db.fsynUnclock()解锁。
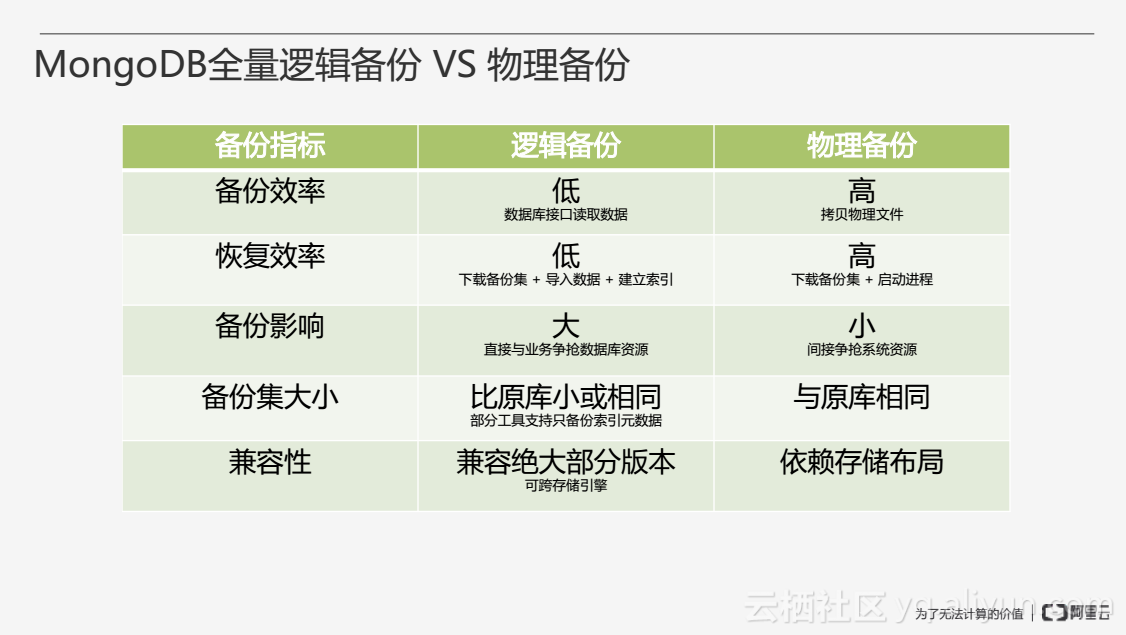
总体上来看,在备份效率上,逻辑备份不如物理备份。逻辑备份通过数据库接口读取数据,当逻辑备份数据量很小、条目很多时,效率会很低,物理备份时物理文件一般会经过文件压缩,拷贝的数据相对来说比较少,同时较充分地使用系统资源,效率会较高。在恢复效率上,逻辑备份也低于物理备份。逻辑备份需要导入数据和重建索引,而物理备份直接启动进程即可。在备份影响上,备份影响主要指在备份的过程中是否对一些正常的业务访问产生影响,由于逻辑备份通过数据库接口读取数据,它将直接与业务争抢数据库资源,而物理备份间接争抢系统的资源,相对来说备份影响比较小。在备份集的大小上,由于逻辑备份没有备份索引数据,一般比原数据库小或相同,而物理备份与原数据库是一模一样的。在兼容性上,逻辑备份优于物理备份,物理备份与存储引擎相关,无法做到跨存储引擎或跨版本的备份恢复,而逻辑备份则支持跨存储引擎以及跨版本。同时,物理备份的成功率比逻辑备份高很多,在某些场景逻辑备份无法进行恢复。
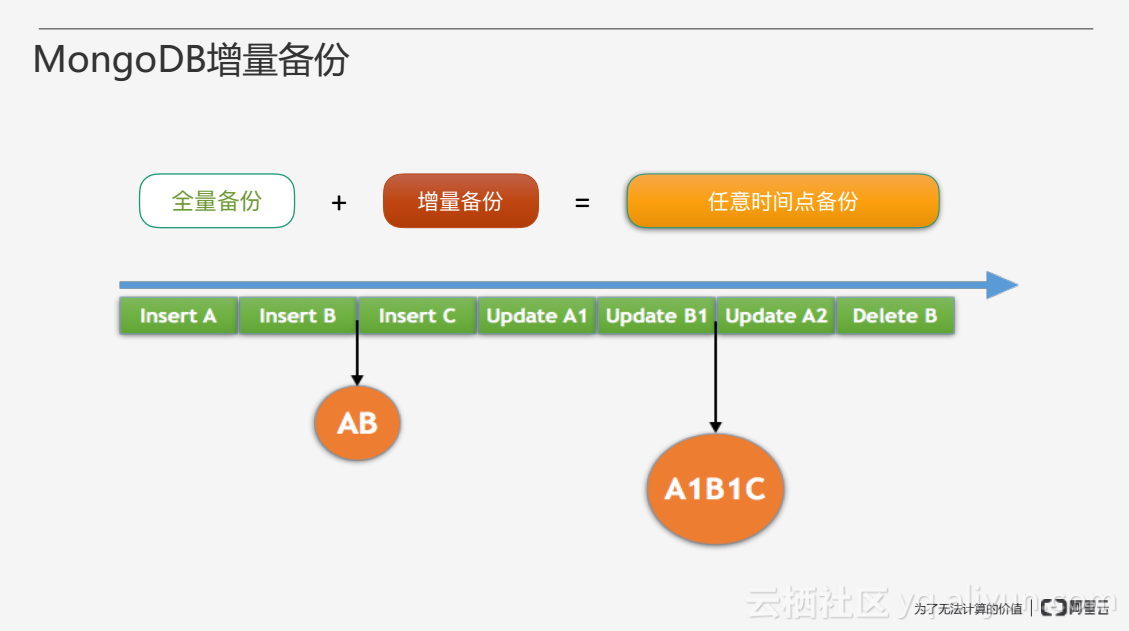
MongoDB增量备份原理比较简单,在MongoDB副本集有oplog进行主备同步,增量备份就是采集oplog并进行存储。全量备份加增量备份就可以实现任意时间点的备份。
厚德载物——阿里云MongoDB备份恢复
阿里云MongoDB备份恢复主要分为四大块:备份、恢复、备份存储和备份有效性验证。
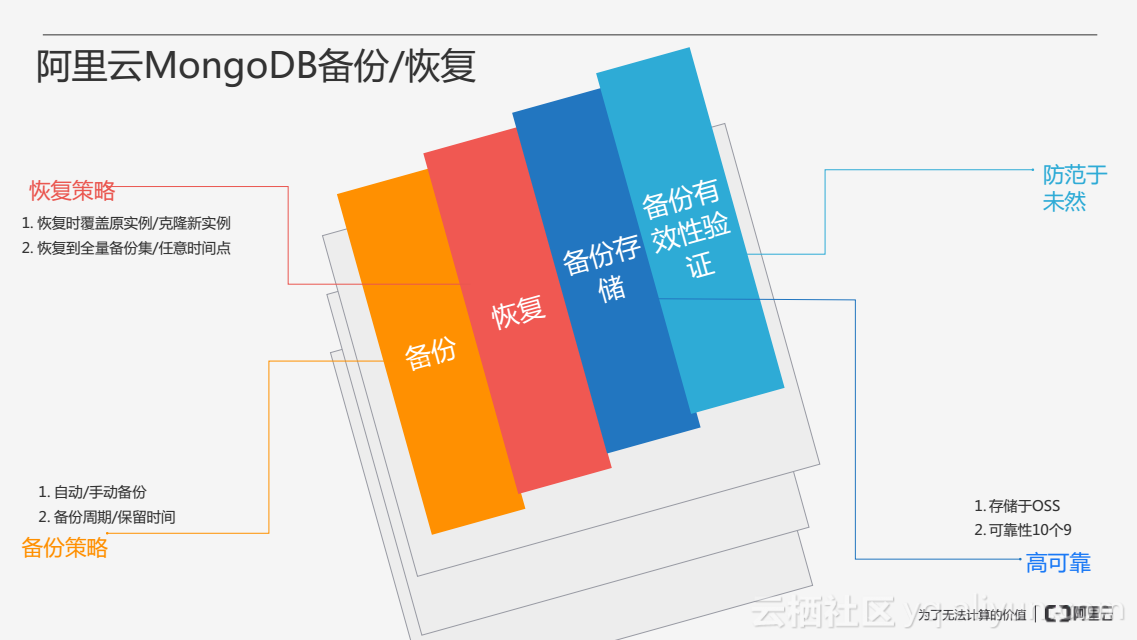
阿里云MongoDB可以定制备份策略,为用户的MongoDB做自动备份,用户也可以在控制台进行手动备份,同时用户可以指定备份周期和保留时间。恢复策略中用户可以选择恢复时覆盖原来的实例或者克隆一个新的实例,也可以指定恢复的粒度,选择恢复到全量的备份集或者恢复到指定的时间点。备份存储中,阿里云MongoDB将数据存储在阿里云OSS上,具有10个9的可靠性。备份有效性验证则是定期对MongoDB实例的备份做一些有效性的验证,避免恢复备份时发现备份出现问题,确保备份可以进行恢复。
以下为阿里云MongoDB控制台的两个主要界面:
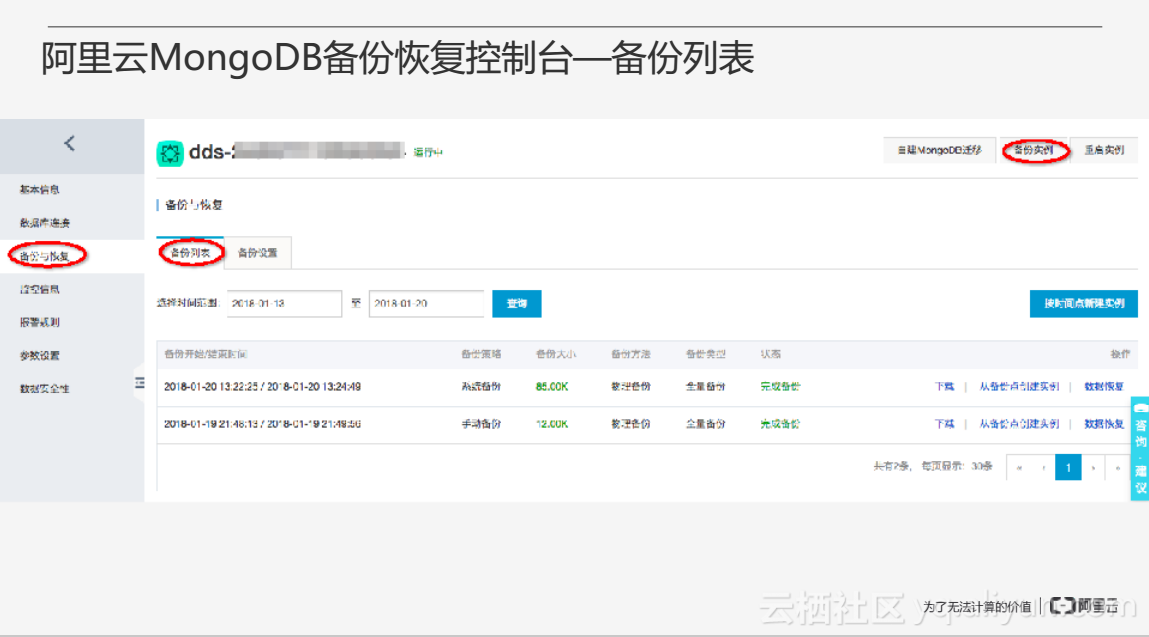
上图为备份列表界面,可以看到备份的一些情况,包括备份的完成时间、是否为自动备份、手动备份等。用户可以点击右上角的备份实例进行手动备份,可以下载备份、根据备份创建实例或者指定一个时间点新建实例、克隆实例。
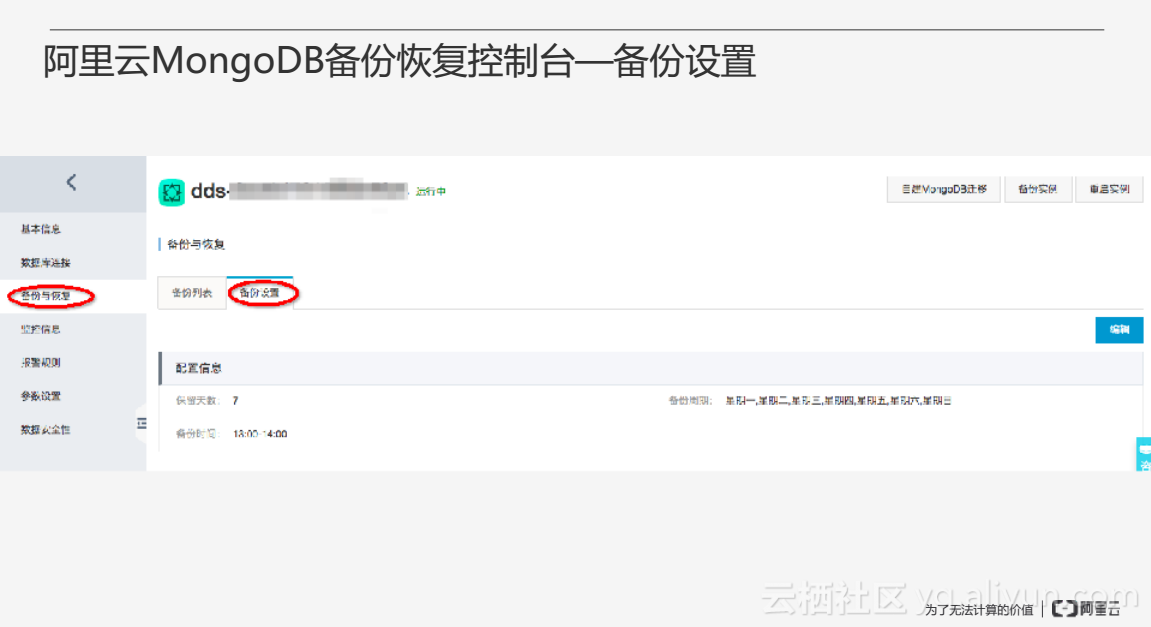
上图为备份设置界面,用户可以制定一些备份策略,包括备份的保留天数、备份的周期等。
精益求精——阿里云MongoDB Sharding备份恢复
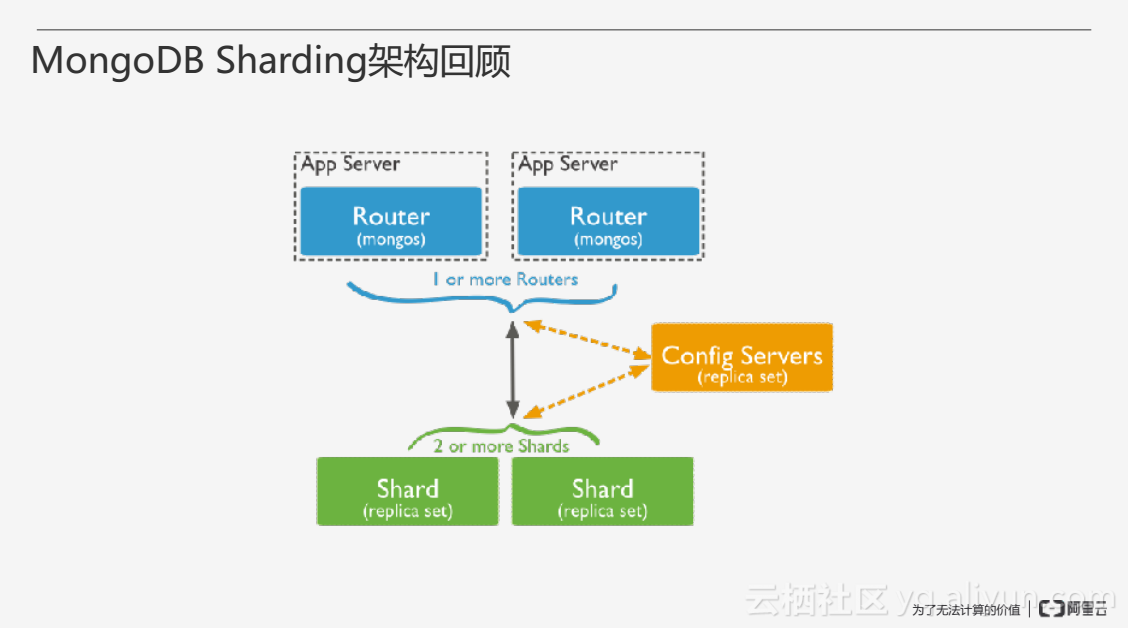
先来回顾一下MongoDB Sharding的架构,MongoDB Sharding架构主要由三大组件构成:蓝色部分为路由节点mongos,它是无状态的、没有存储数据的,不需要进行备份;绿色部分为Shard集群,用于存储用户分片的数据,通过副本集的方式实现高可用,需要进行数据备份;黄色部分为Config Servers,主要存放集群当中的元数据,同样需要进行备份。
MongoDB Sharding备份到底有哪些问题,面对这些问题,阿里云是如何进行有效解决的呢?
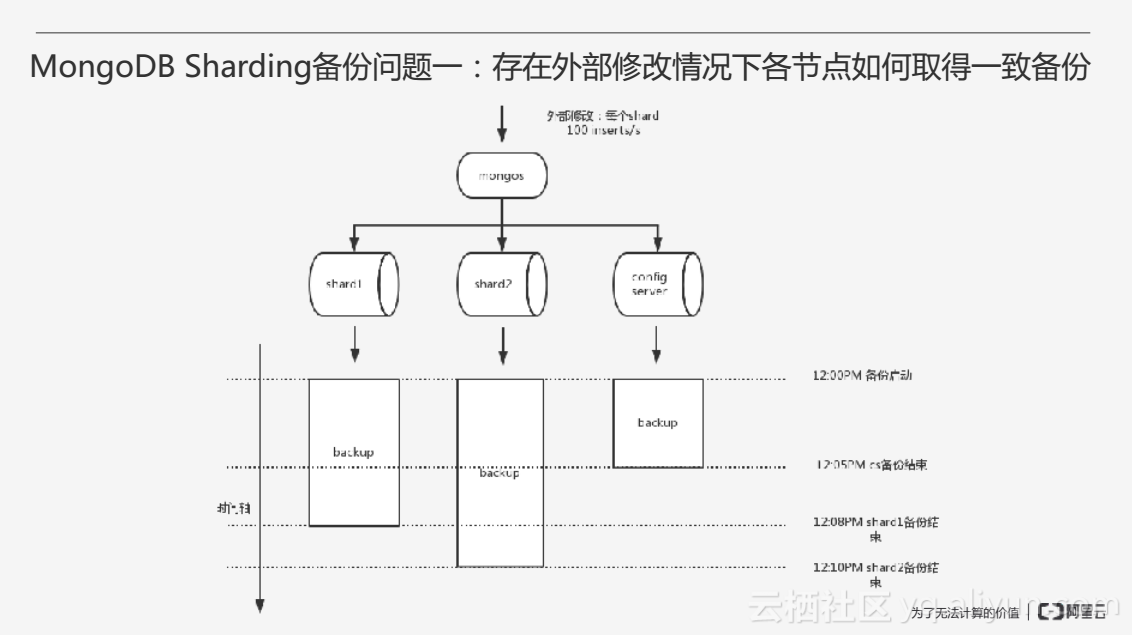
第一个问题是关于集群多个节点在有外部修改情况下如何取得一致备份。在一个集群当中有多个节点,由于每一个节点的容量是不同的,导致节点备份的耗时不同,假设每个节点同时启动备份,由于每个节点备份结束的时间不同,当备份过程中仍然有应用写入时,有些节点的备份会多包含一些新写入的数据,因此整个Sharding备份结束的时间点很难进行确定。
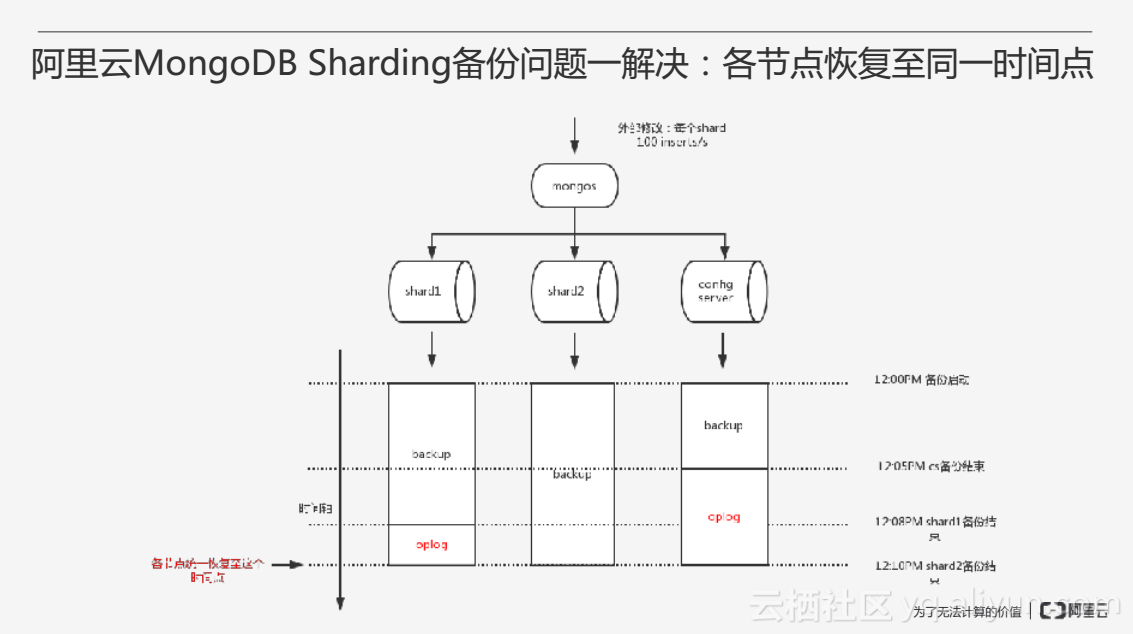
针对这个问题,阿里云采用全量备份加增量备份的方式来做到将各节点的备份对齐至同一时间点。整个Sharding的备份时间点取决于备份结束最晚的节点,对备份结束比较早的节点,多抓取一些oplog,备份结束比较晚的节点则少抓取一些oplog,从而保证各节点的备份加oplog能够对应到同一个时间点。
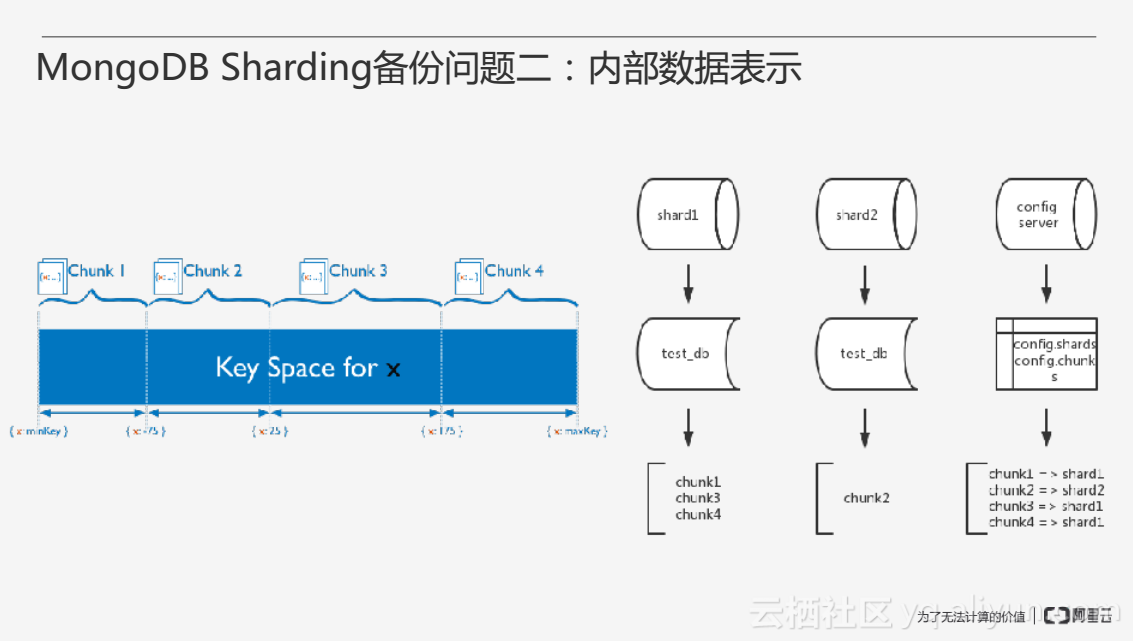
第二个备份问题是关于内部数据的修改,在集群内部通常会有数据的迁移,上图展示了MongoDB Sharding内部数据的一些表示,在做Sharding时通常需要指定一个Shard Key,即分片的片键,如果选择使用Range分片,那么接下来的数据将会按照Shard Key的大小范围进行分布,如果选择使用哈希分片,则会按照Shard Key哈希之后的结果进行分布。Chunk是按照Shard Key进行分布后一部分值的范围所对应的集合,例如上图左侧分为4个chunk,分别对应Shard Key的不同取值范围。Chunk作为一个基础的单元在不同的Shard之间进行分布,config server中存放的一个最重要的元数据之一就是Chunk在Shard之间的分布。
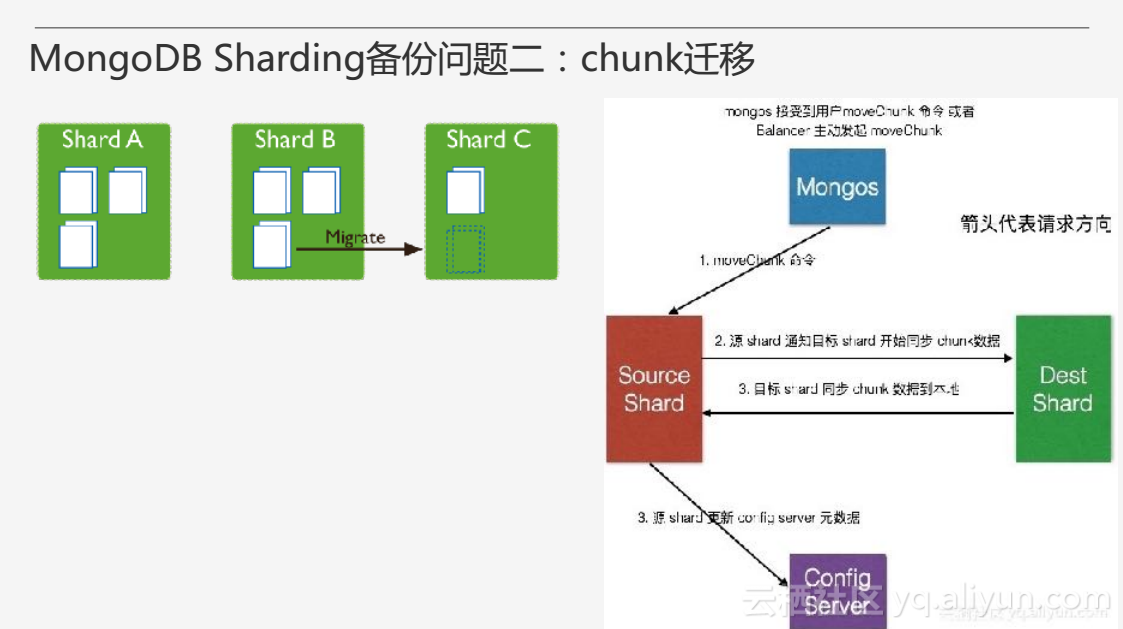
由于对集群进行扩容等需要,增加或删除Shard都需要MongoDB Sharding对数据进行迁移,另外当集群内数据分布不均时,MongoDB也会自发地进行数据迁移,数据迁移的基本单元也是chunk。上图右侧即为一个chunk迁移的基本过程。
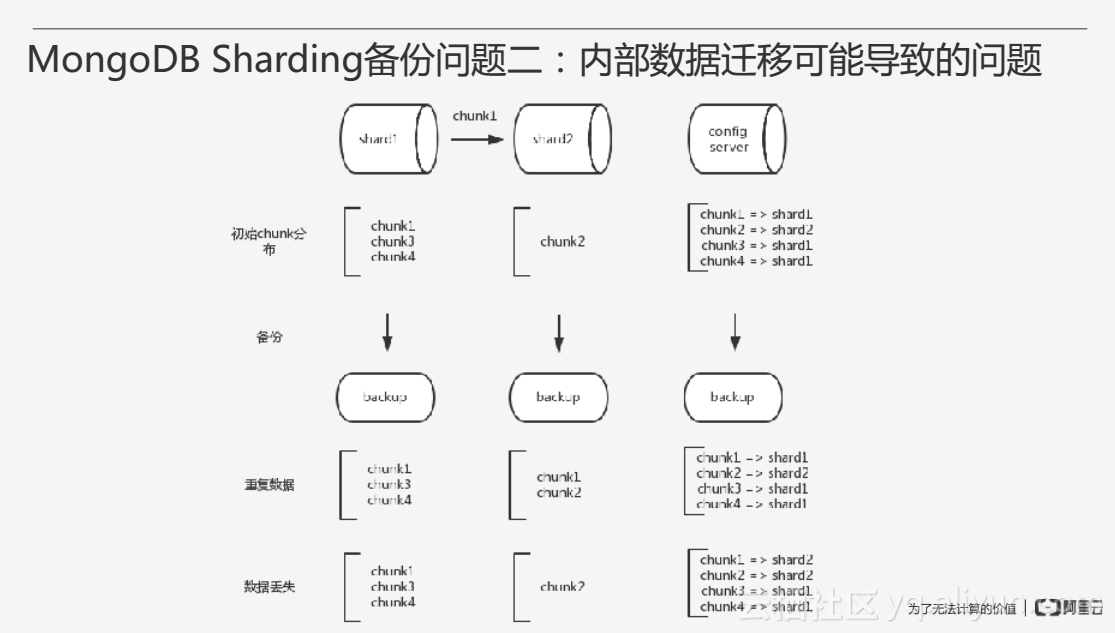
我们看下MongoDB Sharding备份存在的第二个问题。如上图所示,两个Shard上的chunk不均衡,假设chunk1需要从Shard1迁移到Shard2上,迁移过程中我们进行了Sharding备份。如果当所有的节点备份结束时,chunk1的迁移可能还没有结束,这时config server上还是原来的数据分布,此时Shard1仍存在三个chunk,而Shard2存储了部分chunk1,由于数据恢复后chunk的路由是以config server为基准的,所以会认为chunk1存在于Shard1上,因此此时Shard2由于恢复出了多余的chunk1的数据产生数据重复。另外一种情况,所有节点备份结束时config server已经更新了路由信息,确认chunk1已经在Shard2上,但是由于各个节点上的时间并不严格一致,这时候有可能在Shard2中的chunk1数据还没有完全拷贝完毕,这时数据恢复时会发现有一部分的chunk1的数据丢失。综上所述,Sharding备份时遇上chunk迁移有可能导致数据的重复或丢失的问题。
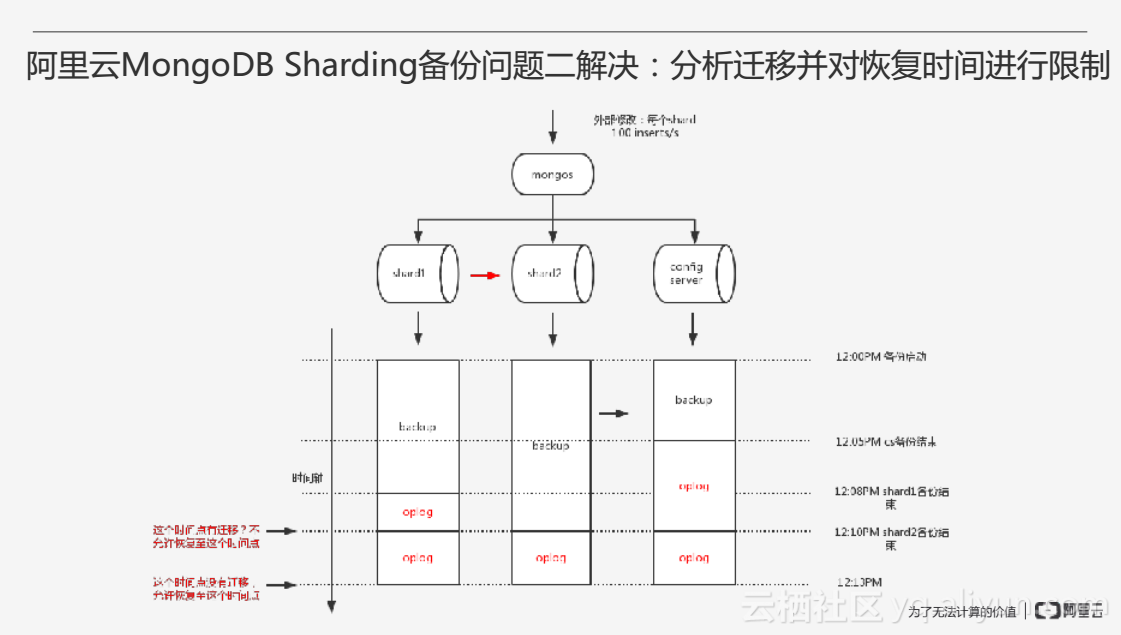
针对问题二,阿里云会对Sharding内部的chunk迁移进行分析,然后对恢复的时间点进行限制,避开有数据迁移的时间段,只有当这个时间点没有数据迁移时才允许恢复至这个时间点。
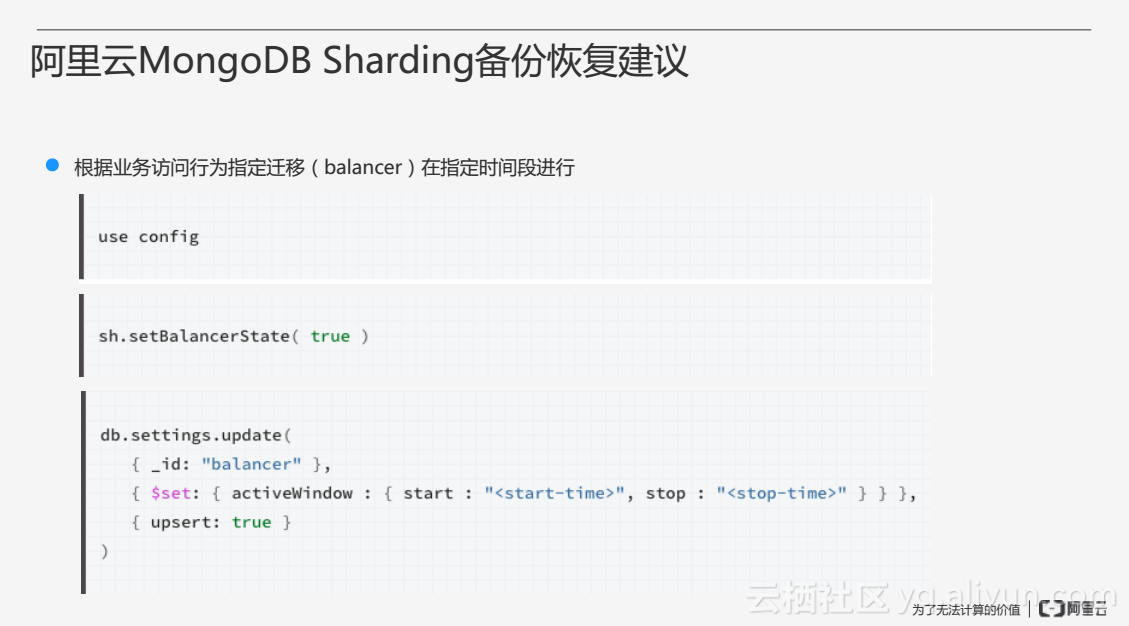
因此,为了更好的配合这个方案,用户在使用MongDB Sharding时最好配置一个迁移的时间段,即用户可以根据业务访问行为指定迁移在哪段时间进行,从而保证其它时间段都可以进行备份恢复。可以通过上图中的三段代码配置迁移的时间点。
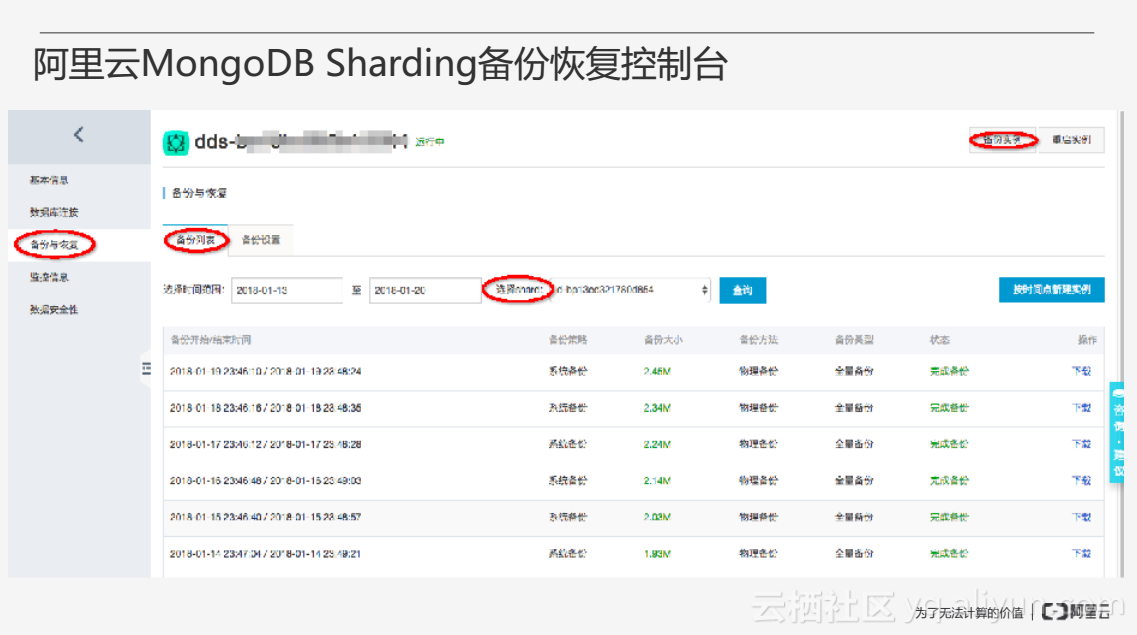
上图为阿里云MongoDB Sharding备份恢复的控制台,与副本集的备份列表界面相比多了选择Shard的功能,可以选择某一个Shard查看备份情况。
虚怀若谷——阿里云MongoDB物理热备份恢复
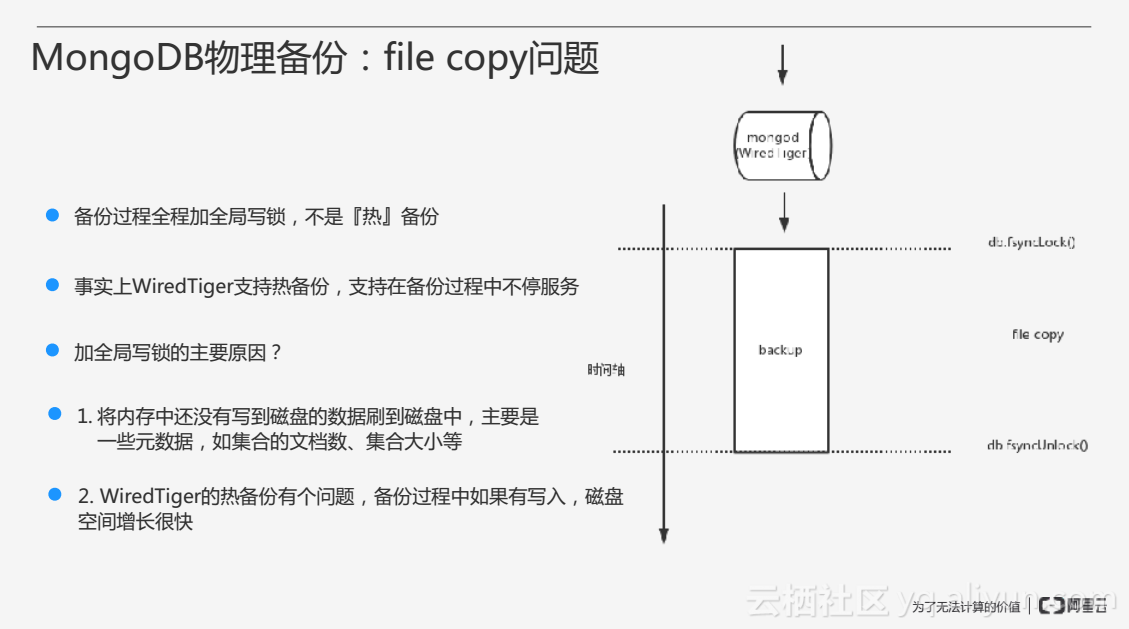
上文提到,通过文件拷贝做物理备份时,备份过程全程加全局写锁,不是热备份,在这段期间MongoDB是无法正常访问的。事实上WiredTiger存储引擎支持热备份,支持在备份过程中不停服务,为什么还要在MongoDB上加全局写锁呢?其一MongoDB会在内存当中维护一些数据,需要通过fsyncLock把一些元数据刷到磁盘当中;其二WiredTiger的热备份有个问题,如果在备份的过程当中有写入,磁盘的空间增长得比较快。
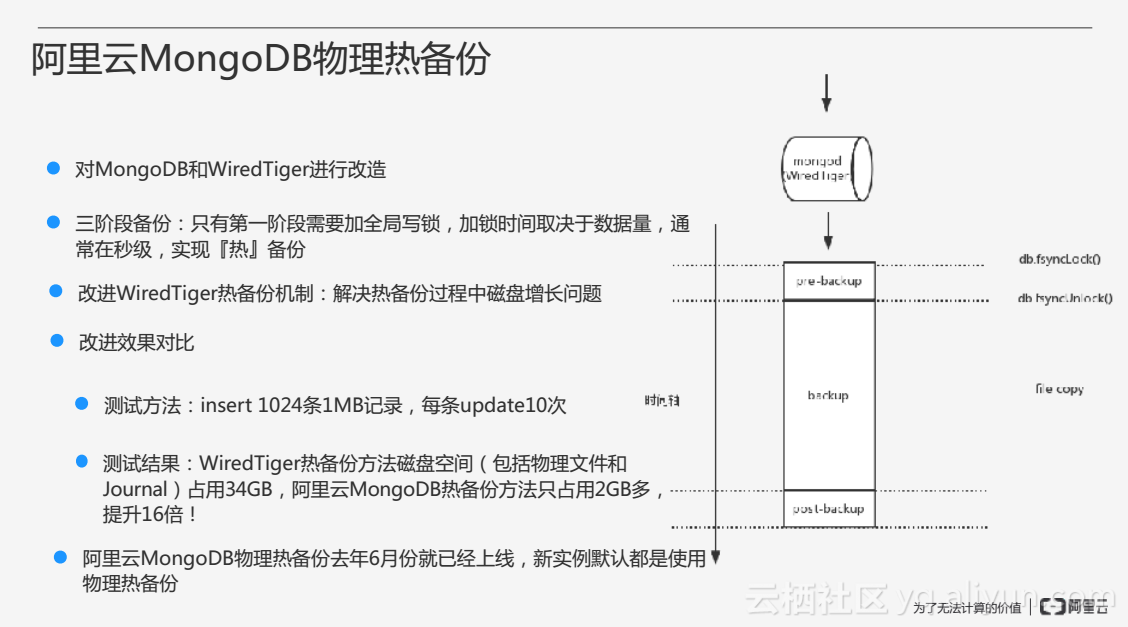
阿里云针对以上问题对MongoDB和WiredTiger进行了改造,抽象出了三个阶段的备份过程,在备份之前加入了预备份(pre-backup)步骤,在备份之后加入了后备份(post-backup)步骤,只需要在预备份阶段加全局写锁即可。同时阿里云改进了WiredTiger的热备份机制,解决了热备份过程中磁盘增长太快的问题。阿里云MongoDB物理热备份的方法在去年6月份就已经上线,目前的新实例也默认使用物理热备份方式。
