标签
PostgreSQL , EDB , ppas , epas , 分区表优化 , PG_PATHMAN
背景
PostgreSQL 在 10的版本,内置了分区表的语法,简化了以前需要写 RULE或TG+继承表功能 来实现分区表的模式。
《PostgreSQL 10.0 preview 功能增强 - 内置分区表》
但是内置分区表的性能还有改进的空间,对比了pg_pathman,性能差异是较大的,主要在plan代码这块。所以对于社区版本的用户,建议使用pg_pathman这个插件来使用分区表的功能。
《PostgreSQL 10 内置分区 vs pg_pathman perf profiling》
作为PostgreSQL的商用发行版本的PPAS,这块有非常大的性能改进。
PPAS分区表性能优化参数
edb_enable_pruning
Parameter Type: Boolean
Default Value: true
Range: {true | false}
Minimum Scope of Effect: Per session
When Value Changes Take Effect: Immediate
Required Authorization to Activate: Session user
When set to TRUE, edb_enable_pruning allows the query planner to early-prune partitioned tables.
Early-pruning means that the query planner can “prune” (i.e., ignore) partitions that would
not be searched in a query before generating query plans.
This helps improve performance time as it eliminates the generation of query plans of
partitions that would not be searched.
Conversely, late-pruning means that the query planner prunes partitions after
generating query plans for each partition.
(The constraint_exclusion configuration parameter controls late-pruning.)
The ability to early-prune depends upon the nature of the query in the WHERE clause.
Early-pruning can be utilized in only simple queries with constraints of the type
WHERE column = literal (e.g., WHERE deptno = 10).
Early-pruning is not used for more complex queries such as
WHERE column = expression (e.g., WHERE deptno = 10 + 5).
edb_enable_pruning这个参数的功能是在生成执行计划之前,过滤掉不需要访问的对象,从而减少执行计划的开销。
注意,目前只适用于 "常量值" 的过滤。即使是immutable函数也不支持。
支持优化
WHERE deptno = 10
不支持优化
WHERE deptno = 10 + 5
对于不能过滤的分区,最后会在生成执行计划后,使用constraint_exclusion参数来过滤不需要访问的分区。
功能测试
创建分区表
postgres=# create table t (id int, info text) partition by range (id);
CREATE TABLE
postgres=# create table t0 PARTITION OF t for values from (0) to (100);
CREATE TABLE
postgres=# create table t1 PARTITION OF t for values from (100) to (200);
CREATE TABLE
开启edb_enable_pruning参数,关闭constraint_exclusion参数
postgres=# show edb_enable_pruning ;
edb_enable_pruning
--------------------
on
(1 row)
postgres=# set constraint_exclusion =off;
SET
简单SQL,可以看到edb_enable_pruning起作用了,过滤了不需要访问的分区。
postgres=# explain select * from t where id=1;
QUERY PLAN
----------------------------------------------------------
Append (cost=0.00..25.88 rows=6 width=36)
-> Seq Scan on t0 (cost=0.00..25.88 rows=6 width=36)
Filter: (id = 1)
(3 rows)
但是对于非常量,无法优化,没有起到过滤效果。
postgres=# explain select * from t where id=1+1;
QUERY PLAN
----------------------------------------------------------
Append (cost=0.00..51.75 rows=12 width=36)
-> Seq Scan on t0 (cost=0.00..25.88 rows=6 width=36)
Filter: (id = 2)
-> Seq Scan on t1 (cost=0.00..25.88 rows=6 width=36)
Filter: (id = 2)
(5 rows)
打开 constraint_exclusion 参数,它会对复杂SQL进行过滤(仅限于immutable、stable的函数和操作符。)
postgres=# set constraint_exclusion =on;
SET
postgres=# explain select * from t where id=1+1;
QUERY PLAN
----------------------------------------------------------
Append (cost=0.00..25.88 rows=6 width=36)
-> Seq Scan on t0 (cost=0.00..25.88 rows=6 width=36)
Filter: (id = 2)
(3 rows)
将edb_enable_pruning关闭,过滤不受影响。只是没有起到优化效果。
postgres=# set edb_enable_pruning =off;
SET
postgres=# explain select * from t where id=1+1;
QUERY PLAN
----------------------------------------------------------
Append (cost=0.00..25.88 rows=6 width=36)
-> Seq Scan on t0 (cost=0.00..25.88 rows=6 width=36)
Filter: (id = 2)
(3 rows)
postgres=# explain select * from t where id=1;
QUERY PLAN
----------------------------------------------------------
Append (cost=0.00..25.88 rows=6 width=36)
-> Seq Scan on t0 (cost=0.00..25.88 rows=6 width=36)
Filter: (id = 1)
(3 rows)
性能测试
为了体现优化效果,加到2000个分区。
postgres=# do language plpgsql $$
declare
begin
for i in 2..2000 loop
execute 'create table t'||i||' PARTITION OF t for values from ('||200+i||') to ('||200+i+1||')';
end loop;
end;
$$;
DO
测试简单SQL(起到优化效果的SQL)
vi test.sql
select * from t where id=1;
TPS达到了100万。
pgbench -M prepared -n -r -P 1 -f ./test.sql -c 56 -j 56 -T 120
progress: 1.0 s, 1031487.3 tps, lat 0.053 ms stddev 0.328
progress: 2.0 s, 1098419.2 tps, lat 0.051 ms stddev 0.009
progress: 3.0 s, 1075788.5 tps, lat 0.052 ms stddev 0.014
progress: 4.0 s, 1090429.9 tps, lat 0.051 ms stddev 0.010
progress: 5.0 s, 1091784.5 tps, lat 0.051 ms stddev 0.010
progress: 6.0 s, 1084007.3 tps, lat 0.052 ms stddev 0.012
progress: 7.0 s, 1094544.1 tps, lat 0.051 ms stddev 0.009
测试不能优化的SQL,只能走传统的constraint_exclusion参数过滤的,性能下降到了1000多TPS
vi test.sql
select * from t where id=1+1;
pgbench -M prepared -n -r -P 1 -f ./test.sql -c 56 -j 56 -T 120
progress: 1.0 s, 0.0 tps, lat -nan ms stddev -nan
progress: 2.0 s, 412.2 tps, lat 247.149 ms stddev 591.770
progress: 3.0 s, 1196.0 tps, lat 53.604 ms stddev 112.786
progress: 4.0 s, 1198.0 tps, lat 46.672 ms stddev 5.575
pg_pathman 的对比性能
pg_pathman实际上以前已经对比过,性能非常好。
《PostgreSQL 10 内置分区 vs pg_pathman perf profiling》
同样创建2000个分区,测试简单和不简单的查询。
postgres=# CREATE EXTENSION pg_pathman;
CREATE EXTENSION
postgres=# create table tbl_range(id int not null, info text, crt_time timestamp);
CREATE TABLE
postgres=# select create_range_partitions('tbl_range', 'id', 0, 100, 2000);
create_range_partitions
-------------------------
2000
(1 row)
postgres=# \d tbl_range
Table "public.tbl_range"
Column | Type | Collation | Nullable | Default
----------+-----------------------------+-----------+----------+---------
id | integer | | not null |
info | text | | |
crt_time | timestamp without time zone | | |
Number of child tables: 2000 (Use \d+ to list them.)
pg_pathman不依赖传统的constraint_exclusion参数,简单和不简单的SQL,都被过滤了。
postgres=# set constraint_exclusion =off;
SET
postgres=# explain select * from tbl_range where id=1;
QUERY PLAN
-------------------------------------------------------------------
Append (cost=0.00..24.12 rows=6 width=44)
-> Seq Scan on tbl_range_1 (cost=0.00..24.12 rows=6 width=44)
Filter: (id = 1)
(3 rows)
postgres=# explain select * from tbl_range where id=1+1;
QUERY PLAN
-------------------------------------------------------------------
Append (cost=0.00..24.12 rows=6 width=44)
-> Seq Scan on tbl_range_1 (cost=0.00..24.12 rows=6 width=44)
Filter: (id = 2)
(3 rows)
性能测试
pgbench -M prepared -n -r -P 1 -f ./test.sql -c 56 -j 56 -T 120
-- 简单SQL
progress: 3.0 s, 947237.9 tps, lat 0.059 ms stddev 0.010
progress: 4.0 s, 949539.4 tps, lat 0.059 ms stddev 0.009
progress: 5.0 s, 948459.0 tps, lat 0.059 ms stddev 0.010
progress: 6.0 s, 947355.4 tps, lat 0.059 ms stddev 0.010
progress: 7.0 s, 947789.2 tps, lat 0.059 ms stddev 0.010
progress: 8.0 s, 949380.5 tps, lat 0.059 ms stddev 0.010
progress: 9.0 s, 944190.6 tps, lat 0.059 ms stddev 0.023
progress: 10.0 s, 947677.8 tps, lat 0.059 ms stddev 0.010
-- 非简单SQL
progress: 3.0 s, 951051.2 tps, lat 0.059 ms stddev 0.012
progress: 4.0 s, 960237.6 tps, lat 0.058 ms stddev 0.010
progress: 5.0 s, 961659.2 tps, lat 0.058 ms stddev 0.009
progress: 6.0 s, 946538.5 tps, lat 0.059 ms stddev 0.012
progress: 7.0 s, 956382.1 tps, lat 0.059 ms stddev 0.011
progress: 8.0 s, 961674.0 tps, lat 0.058 ms stddev 0.009
progress: 9.0 s, 957060.6 tps, lat 0.059 ms stddev 0.010
progress: 10.0 s, 950707.1 tps, lat 0.059 ms stddev 0.013
progress: 11.0 s, 955766.4 tps, lat 0.059 ms stddev 0.010
pg_pathman对简单和非简单SQL的优化效果一样,都非常的好。
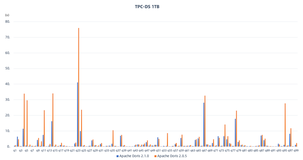
性能对比
| 分区特性 | TPS |
|---|---|
| PPAS native分区 edb_enable_pruning=on 常量条件过滤 | 1031487 |
| PPAS native分区 edb_enable_pruning=on 条件无法过滤 | 1196 |
| PG pg_pathman分区 | 957060 |
小结
对于PPAS用户,建议能常量输入的,就使用常量输入,这样能够用到分区过滤的优化特性。(特别是在分区表非常多的情况下,优化效果非常明显)。
对于PG用户,使用pg_pathman作为分区组件,在分区很多的情况下,性能比native的分区好很多很多。