转自:http://asyty.iteye.com/blog/1202072
二、Cassandra数据模型
Colum / Colum Family, SuperColum / SuperColum Family
Colum排序
三、分区策略
Token,Partitioner
bloom-filter,HASH
四、副本存储
五、网络嗅探
六、一致性
Quorum NRW
维护最终一致性
七、存储机制
CommitLog
MenTable
附
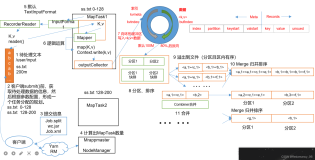
一、Cassandra框架

图1 Cassandra
Cassandra是社交网络理想的数据库,适合于实时事务处理和提供交互型数据。以Amazon的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型,P2P去中心化的存储,目前twitter和digg中都有使用。
在CAP特性上,HBase选择了CP,Cassandra更倾向于AP,而在一致性上有所减弱。
Cassandra的类Dynamo特性有以下几点:
l 对称的,P2P架构
n 无特殊节点,无单点故障
l 基于Gossip的分布式管理
l 通过分布式hash表放置数据
n 可插拔的分区
n 可插拔的拓扑发现
n 可配置的放置策略
l 可配置的,最终一致性
类BigTable特性:
l 列族数据模型
n 可配置,2级maps,Super Colum Family
l SSTable磁盘存储
n Append-only commit log
n Mentable (buffer and sort)
n 不可修改的SSTable文件
l 集成Hadoop
二、 Cassandra数据模型
Colum / Colum Family, SuperColum / SuperColum Family
Column是数据增量最底层(也就是最小)的部分。它是一个包含名称(name)、值(value)和时间戳(timestamp)的三重元组。
下面是一个用JSON格式表示的column:
{ // 这是一个Column
name: "emailAddress",
value: "arin@example.com",
timestamp: 123456789
}
需要注意的是,name和value都是二进制的(技术上指byte[]),并且可以是任意长度。
与HBase相比,除了Colum/Colum Family外,Cassandra还支持SuperColum/SuperColum Family。
SuperColum与Colum的区别就是,标准Column的value是一个“字符串”,而 SuperColumn的value是一个包含多个Column的map,另一个细微的差别是:SuperColumn没有时间戳。
{ // 这是一个SuperColumn
name: "homeAddress",
// 无限数量的Column
value: {
street: {name: "street", value: "1234 x street", timestamp: 123456789},
city: {name: "city", value: "san francisco", timestamp: 123456789},
zip: {name: "zip", value: "94107", timestamp: 123456789},
}
}
Column Family(CF)是某个特定Key的Colum集合,是一个行结构类型,每个CF物理上被存放在单独的文件中。从概念上看,CF像数据库中的Table。
SuperColum Family概念上和Column Family(CF)相似,只不过它是Super Colum的集合。
Colum排序
不同于数据库可以通过Order by定义排序规则,Cassandra取出的数据顺序是总是一定的,数据保存时已经按照定义的规则存放,所以取出来的顺序已经确定了。另外,Cassandra按照column name而不是column value来进行排序。
Cassandra可以通过Colum Family的CompareWith属性配置Colume值的排序,在SuperColum中,则是通过SuperColum Family的CompareSubcolumnsWith属性配置Colum的排序。
Cassandra提供了以下一些选:BytesType,UTF8Type,LexicalUUIDType,TimeUUIDType,AsciiType, Column name识别成为不同的类型,以此来达到灵活排序的目的。
三、分区策略
Token,Partitioner
Cassandra中,Token是用来分区数据的关键。每个节点都有一个第一无二的Token,表明该节点分配的数据范围。节点的Token形成一个Token环。例如使用一致性HASH进行分区时,键值对将根据一致性Hash值来判断数据应当属于哪个Token。

图3 Token Ring
分区策略的不同,Token的类型和设置原则也有所不同。 Cassandra (0.6版本)本身支持三种分区策略:
RandomPartitioner:随机分区是一种hash分区策略,使用的Token是大整数型(BigInteger),范围为0~2^127,Cassandra采用了MD5作为hash函数,其结果是128位的整数值(其中一位是符号位,Token取绝对值为结果)。因此极端情况下,一个采用随机分区策略的Cassandra集群的节点可以达到2^127+1个节点。采用随机分区策略的集群无法支持针对Key的范围查询。
OrderPreservingPartitioner:如果要支持针对Key的范围查询,那么可以选择这种有序分区策略。该策略采用的是字符串类型的Token。每个节点的具体选择需要根据Key的情况来确定。如果没有指定InitialToken,则系统会使用一个长度为16的随机字符串作为Token,字符串包含大小写字符和数字。
CollatingOrderPreservingPartitioner:和OrderPreservingPartitioner一样是有序分区策略。只是排序的方式不一样,采用的是字节型Token,支持设置不同语言环境的排序方式,代码中默认是en_US。
分区策略和每个节点的Token(Initial Token)都可以在storage-conf.xml配置文件中设置。
bloom-filter, HASH
Bloom Filter是一种空间效率很高的随机数据结构,本质上就是利用一个位数组来表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有误差的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合,而在能容忍低错误率的场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
原理:位数组 + K个独立hash(y)函数。将位数组中hash函数对应的值的位置设为1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是完全正确的。
在Cassandra中,每个键值对使用1Byte的位数组来实现bloom-filter。

图4 Bloom Filter