在端午节放假的三天中,我对正在开发的 Service 进行了 LoadTest,尝试在增大压力的条件下发现问题。
该 Service 为独立进程的 WCF 服务,宿主于 WindowsService,其接收其他 Service 的调用,并根据业务流程调用不同的依赖 Service。
问题现象
果真,假期归来,问题来了。内存正常在 200M 左右,已经膨胀到 4.5G,同时正常线程数为 40-60 左右,已经占用了 560 个。
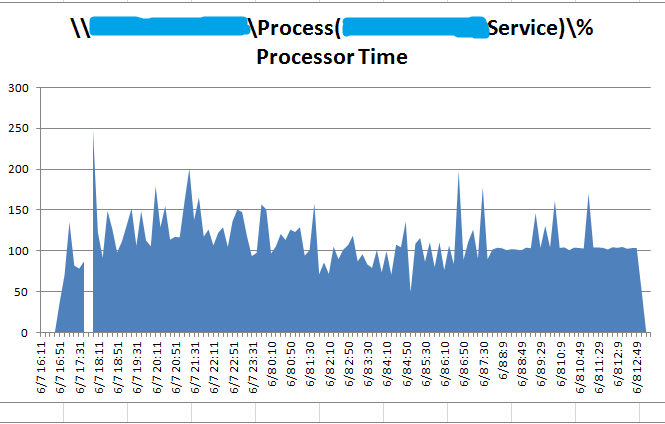
基于在测试之前已经准备好了 PerformanceCounter 记录,从报表数据来看,CPU 使用率不高,并且仍然在偶尔活跃,可以猜测只是部分业务 Block,而非全部。
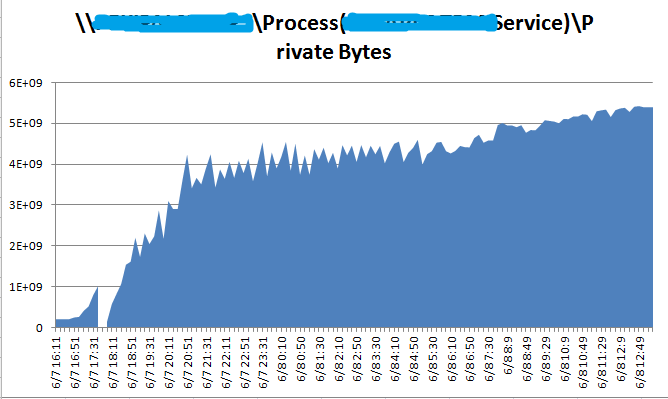
在此期间,内存不断攀升,而且比想象的要快。
但奇怪的是,线程数在 6 月 8 日 7:30 左右才开始爆发。

所以大概可以分析,内存的增加与线程的增加,没有之间的联系,线程数虽在 500 以上,但按照业务代码核算,不至于产生 4.5G 以上的内存使用。
所以猜测,应该有两个问题:
- 在代码某处有持续的内存泄漏。
- 在代码某处有单点故障导致 Block 线程。
分析内存泄漏
好的消息是,进程还活着,虽然不再进行正经的业务。此时,祭出神器 WinDbg,尝试看看内存中有什么。
!dumpheap -stat
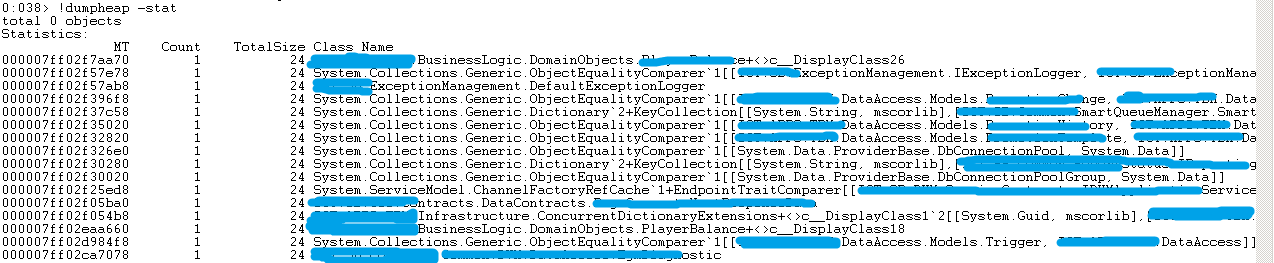
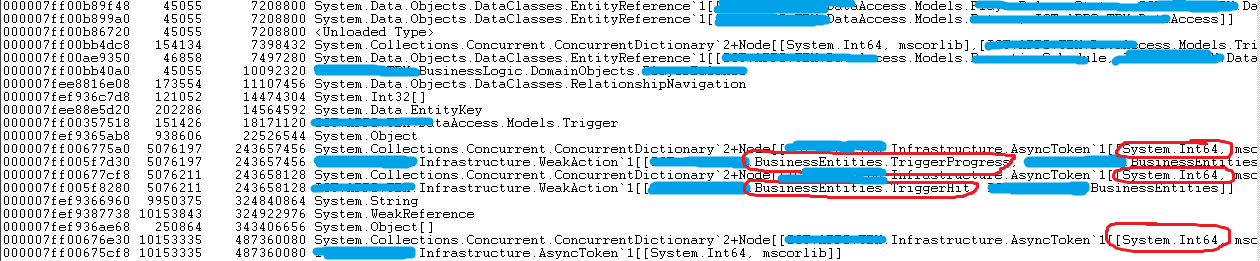
- MT :对应 Method Table 地址。
- Count : 该对象的数量。
- TotalSize :该对象的总大小,Bytes。
TriggerHit和TriggerProgress都是业务类型,可以大概看一下TriggerHit类型的大小,使用:
!dumpheap -mt 000007ff006775a0
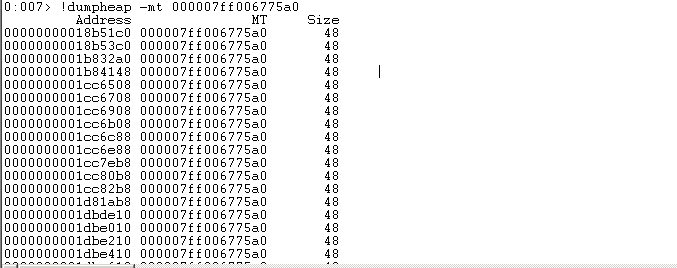
!dumpobj 0000000005cbbf78

可以明确判断,每个AsyncToken实例只占48Bytes。而其为ConcurrentDictionary中的一个Node,代表一个KeyValue键值对。
综合以上可以看出,几种类型 TriggerProgress、TriggerHit、long、AsyncToken 类型最多。从业务设计上看 TriggerProgress/TriggerHit 业务类实例的个数是相同的,从图上看也是相同的,但数量肯定不至于有507万个。每个类型的占用内存大概在240M以上。而有差不多数量的 AsyncToken 类型,占用也在240M左右。而 long 类型,存放在 ConcurrentDictionary 中,应该是作为某种索引,居然有1000万条,空间占用480M以上。这几个类型的占用总和已经达到了3G左右。所以说,这里应该是内存泄漏的根源。
此时,查看对应的数据库表 Triggers,

居然有700多万条数据处在Enabled状态。此处的Trigger是个业务概念,其代表该Service与另外一个Service之间的Transaction,如果其为活跃,则证明在所依赖的Service并没有明确回复该Transaction已结束。而从业务设计角度,每秒会产生100-200个Transaction,每个Transaction通常在5分钟左右的时间结束。进一步在Service的日志Log中确认是否有Exception出现,排除处理Transaction异常的情况,发现没有。也就是说,有大量的Transaction未接收到回复,所依赖的Service应该出了问题。
走到此处,在LoadTest中内存泄漏的问题算是被确认了,而后来经过与相应的Service开发人员沟通,确认所依赖的Service确实有性能问题,因为在Load很高的情况下,发送的Transaction数量已经超过了对方Service承受的能力。后续的补充解决办法是为Transaction增加Timeout超时检测。
好,问题解决一个,线程数高的问题还没有解决,前面已经描述了,内存高与线程多没有关系。那么,那560个线程每个走在做什么工作呢?
分析线程使用
显然需要继续使用WinDbg,因为此时使用ProcessExplorer只能帮助确认线程在使用那些DLLs,没有更多帮助。
由于有500多个线程,所以也不知道从哪个开始,只能从头一个一个来。一般1-10可能是进程启动时启用的线程,比如MainThread、GC回收线程等。同时,业务中的一些常规Timer也会先启动占用线程。
当查到第22个线程时,
~22 e !clrstack
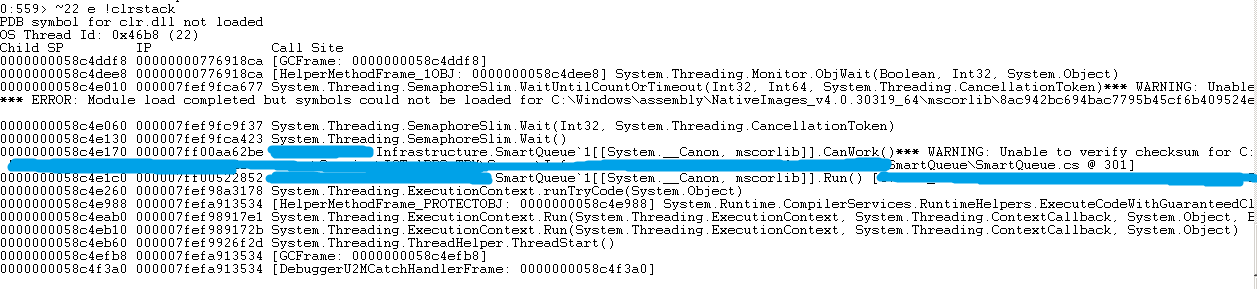
这个很有帮助,发现第22个线程在 SemaphoreSlim.Wait() 等待一个信号量释放,而其为类 SmartQueue 中的代码。还好加了PDB文件,直接显示到 SmartQueue.cs 的第 301 行。直接看看代码,
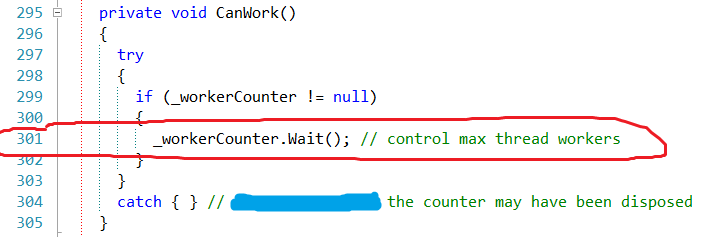
发现这句代码在等待信号量的释放,并且没有指定超时时间,所以如果信号量在占用线程不被释放,这里将一直阻塞着。那这是一个被阻塞的线程,而不是引发阻塞的线程。
下一个线程,23号线程也在做同样的事情,等待信号量释放,所以猜测有很多线程在等待同一个信号量释放。

问题是,系统中有至少10个SmartQueue在工作,而此处无法看出是哪个SmartQueue被阻塞了。但根据业务设计和配置文件中的配置,
![]()
每个SmartQueue中最多启160个线程,而这个Queue的配置已经是最大的了,其他均小于160。这样看来,达到560,还不是一个SmartQueue在努力。
问题复杂了,一时看不出究竟,只能继续查看。当查到第30号线程时,
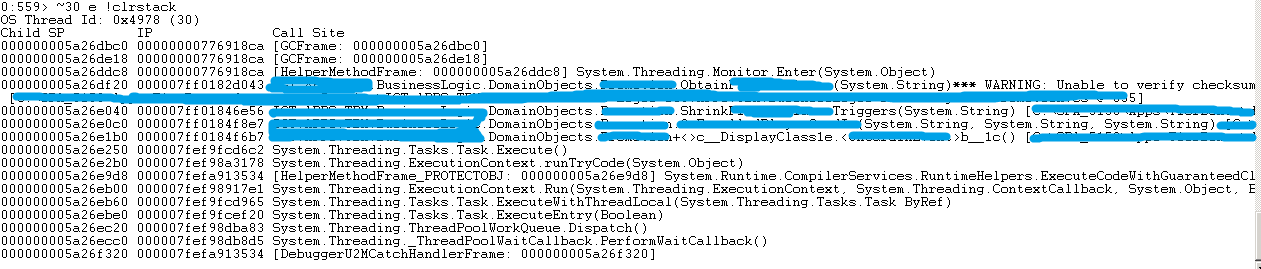
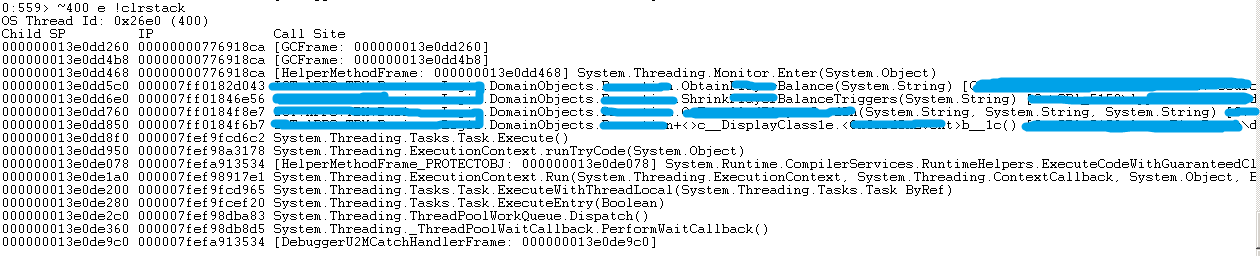
希望来了,这个调用占说明,在方法ObtainXXX中,正在Monitor.Enter(object),也就是一个lock在尝试锁定对象。此时继续查看线程调用栈,40/50/100/200/300/400/500线程均Block在ObtainXXX方法中。
PDB信息中已经给出的代码行,

这里__activeXXX是一个ConcurrentDictionary,这里已经进行了DoubleCheck检测,也就是获得锁的线程需要检测是否该ID已经在其他线程中增加了。但调用这个ObtainXXX方法的代码有8处,并且在不同的业务规则中,所以确实可以发生在不同的SmartQueue中的线程中,也验证了上面的猜测。
那么,问题是,既然一个线程得到了锁,而其不释放这个锁,那么就是说{}代码中应该有可阻塞调用。
![]()
发现代码中,除了Log,只有一句代码,就是这个LoadXXXByID,其功能就是从数据库中获取数据并生成对象实例。
此处我开始疑惑,Service访问数据库使用EntityFramework,此处针对这个业务对象,只有两种操作,
- 如果数据库中不存在此业务对象ID,则Insert一条新的。
- 如果数据库中存在此业务对象ID,则通过Select读取数据构造业务对象。
业务代码简写为:

Balance storedBalance = Repository.Balance.QueryWithPC() .SingleOrDefault(p => p.RelatedId == xxx); if storedBalance == null) { storedBalance = CreateBalanceToRepository(xxx); }
这能产生死锁?
分析数据库
走到这一步,开始关注数据库了。因为,感觉Insert操作会产生表级锁,阻塞所有Select操作,Update操作可能产生多种类型的锁,但Insert/Update会很快处理完毕释放锁。Select操作,默认EntityFramework并不加QueryHint,所以默认查询隔离级别为ReadCommitted,即使这样,查询只会变慢,但不会死锁。所以,有些想不通。
先查看了针对数据库访问定制的PerformanceCounter,
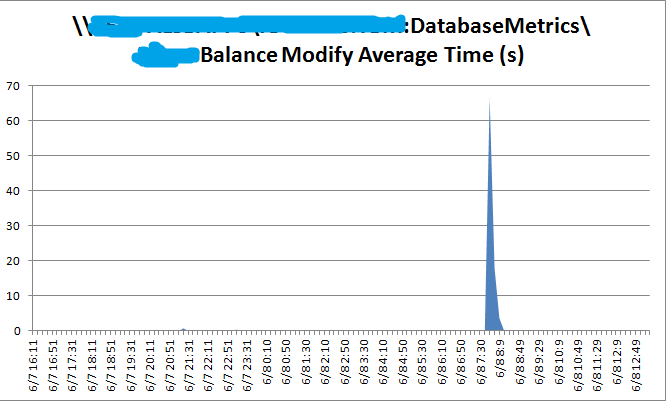

发现在发生故障之前,CRUD操作均在0.1秒以下。在发生故障的那个时间点,针对Balance表的Insert操作的时长已经达到了60秒的量级,而Select操作也已经平均在5秒以上。
到底发生了什么?
SQL Server Management Studio 提供了些默认的报表,先看看。发现一张有用的报表 Top Transactions by Locks Count,
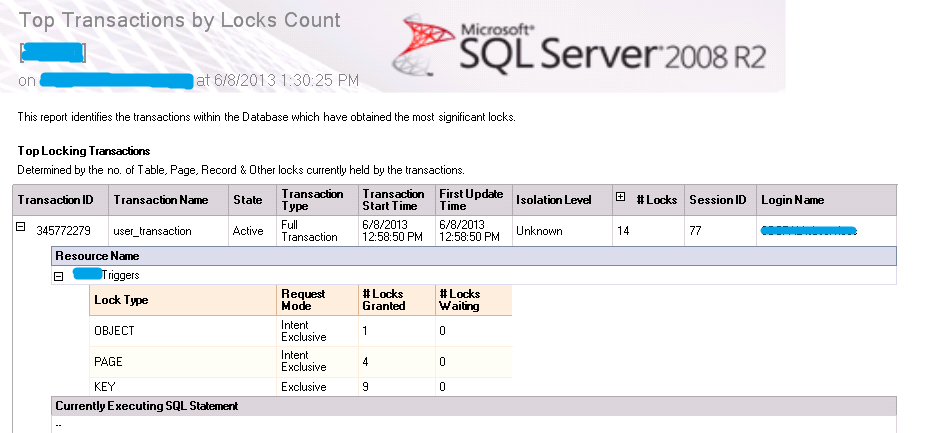
貌似Triggers表有死锁出现,而业务上,Balance与Trigger是一对多的关系。
查看Trigger表的PerformanceCounter监控记录,
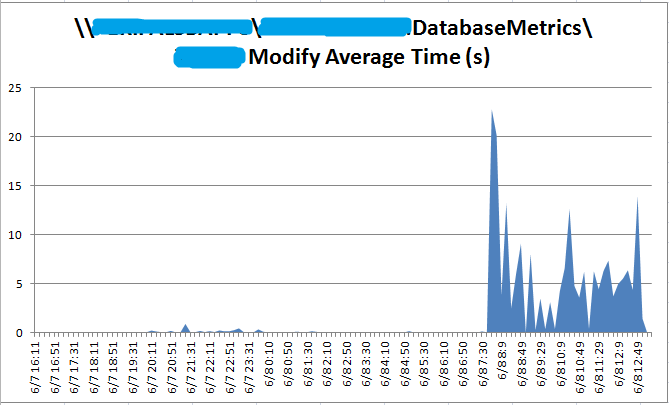
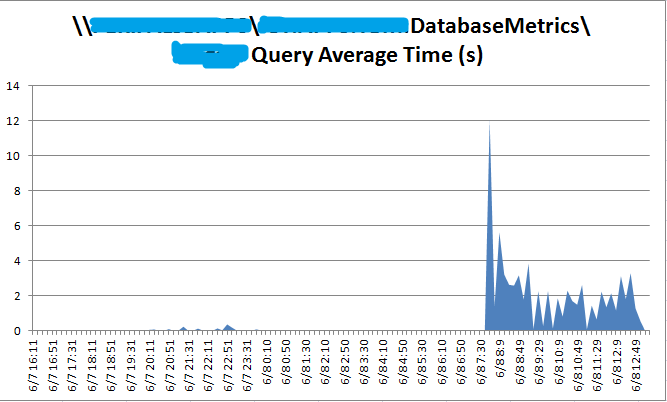
Trigger这张数据库表,在同样的时间也发生了类似的访问时间异常。
SELECT REQUEST_MODE, REQUEST_TYPE, REQUEST_SESSION_ID FROM sys.dm_tran_locks WHERE RESOURCE_TYPE = 'OBJECT' AND RESOURCE_ASSOCIATED_ENTITY_ID =(SELECT OBJECT_iD('Triggers'))
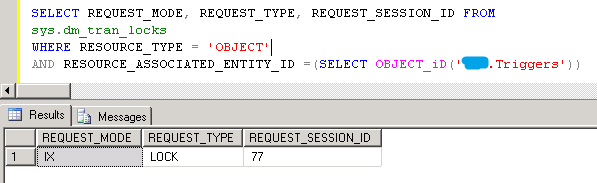
用上面这个SQL查询确认Triggers表在SessionID=77上发生了IX类型的锁,不释放。
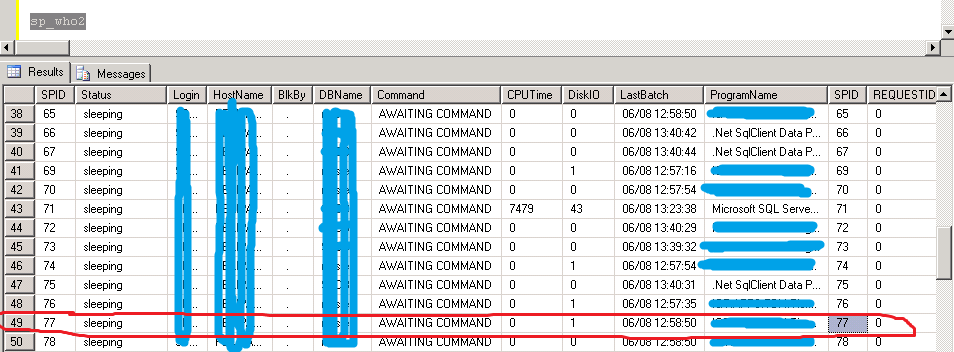
并且使用 sp_who2 确认这个session是由我们的Service保持的,因为有多个Service在使用同一个数据库。
我在Google上搜索到了一个可以查看具体锁内容的SQL,
SELECT L.request_session_id AS SPID, DB_NAME(L.resource_database_id) AS DatabaseName, SC.name AS SchemaName, O.Name AS LockedObjectName, P.object_id AS LockedObjectId, L.resource_type AS LockedResource, L.request_mode AS LockType, ST.text AS SqlStatementText, ES.login_name AS LoginName, ES.host_name AS HostName, TST.is_user_transaction as IsUserTransaction, AT.name as TransactionName, CN.auth_scheme as AuthenticationMethod FROM sys.dm_tran_locks L JOIN sys.partitions P ON P.hobt_id = L.resource_associated_entity_id JOIN sys.objects O ON O.object_id = P.object_id JOIN sys.schemas SC ON O.schema_id = SC.schema_id JOIN sys.dm_exec_sessions ES ON ES.session_id = L.request_session_id JOIN sys.dm_tran_session_transactions TST ON ES.session_id = TST.session_id JOIN sys.dm_tran_active_transactions AT ON TST.transaction_id = AT.transaction_id JOIN sys.dm_exec_connections CN ON CN.session_id = ES.session_id CROSS APPLY sys.dm_exec_sql_text(CN.most_recent_sql_handle) AS ST WHERE resource_database_id = db_id() ORDER BY SchemaName
查询结果:

从SqlStatementText的样子可以看出,这些SQL基本上就是EntityFramework生成的。进而总结所有对Trigger表的操作SQL,
Insert Trigger:
insert [Triggers]([BalanceID], [Origin], [Offset], [Target], [TriggerId], [Category], [CreatedTime], [LastUpdatedTime], [Enabled]) values (@0, @1, @2, @3, @4, @5, @6, @7, @8) select [ID] from [Triggers] where @@ROWCOUNT > 0 and [ID] = scope_identity()',N'@0 bigint,@1 bigint,@2 bigint,@3 bigint,@4 bigint,@5 smallint,@6 datetime2(7),@7 datetime2(7),@8 bit',@0=14,@1=0,@2=0,@3=2000,@4=635062714505193632,@5=0,@6='2013-06-08 07:00:19.8322818',@7='2013-06-08 07:00:19.8322818',@8=1
Update Trigger:
update [Triggers] set [BalanceID] = @0, [Origin] = @1, [Offset] = @2, [Target] = @3, [TriggerId] = @4, [Category] = @5, [CreatedTime] = @6, [LastUpdatedTime] = @7, [Enabled] = @8 where ([ID] = @9) ',N'@0 bigint,@1 bigint,@2 bigint,@3 bigint,@4 bigint,@5 smallint,@6 datetime2(7),@7 datetime2(7),@8 bit,@9 bigint',@0=14,@1=0,@2=0,@3=266,@4=635062714505193629,@5=3,@6='2013-06-08 07:00:19.8292815',@7='2013-06-08 07:00:37.1550139',@8=0,@9=111
Select Trigger:
SELECT [Extent1].[ID] AS [ID], [Extent1].[BalanceID] AS [BalanceID], [Extent1].[Origin] AS [Origin], [Extent1].[Offset] AS [Offset], [Extent1].[Target] AS [Target], [Extent1].[TriggerId] AS [TriggerId], [Extent1].[Category] AS [Category], [Extent1].[CreatedTime] AS [CreatedTime], [Extent1].[LastUpdatedTime] AS [LastUpdatedTime], [Extent1].[Enabled] AS [Enabled] FROM [Triggers] AS [Extent1] WHERE ([Extent1].[BalanceID] = @p__linq__0) AND ([Extent1].[Enabled] = 1) AND ([Extent1].[LastUpdatedTime] > @p__linq__1)',N'@p__linq__0 bigint,@p__linq__1 datetime2(7)',@p__linq__0=22,@p__linq__1='2013-06-08 06:15:56.6259518'
这些SQL都已经是简单到不能再简单的SQL了,但根据上图描述,在多个Key上产生了X锁,在多个Page上产生了IX锁,而我猜测就是这个IX锁阻塞了所有操作。
但,我还是不知道为什么会产生DeadLock。我只能猜测,一个Update在把持一个Key-X锁,而另一个Update把持着Page-IX锁,他们互相等,而Select在等S锁,并等待X、IX结束。
然后,我尝试了一个很stupid的操作,Kill 77。我把这个session给kill掉了,瞬间,service进程没了。我破坏了现场。
我以为,然后就没有然后了。

是的,在进程死之前,居然打了句Log,真给力啊。至少它明确的告诉了我,“An existing connection was forcibly closed by the remote host.”。这就是我的Kill操作。
而且,其证明了这个session阻塞在 UnitOfWork.Commit() 方法上,也就是最终的 DbContext.SaveChanges() 上。
而这个操作是在Update这个Triggers表,也就是Transaction在这里产生了DeadLock最终没有返回,导致此处代码一直被Block,进而没有释放lock(object),进而阻塞线程,并阻止了其他线程的访问。
最后,我做了些更改,当获取 Repository<Trigger> 时,增加 TransactionScope,并指定 ReadUncommitted。
private static T Get<T>() where T : class { T obj = default(T); using (var transactionScope = new TransactionScope( TransactionScopeOption.RequiresNew, new TransactionOptions() { IsolationLevel = IsolationLevel.ReadUncommitted })) { obj = UnityContainerDispatcher.GetContainer().Resolve<T>(); transactionScope.Complete(); } return obj; }
在新的一轮测试中,相同 Load 下,DeadLock 没有再产生,只能说 "貌似" 解决了问题。
本文转自匠心十年博客园博客,原文链接:http://www.cnblogs.com/gaochundong/p/troubleshooting_with_windbg.html,如需转载请自行联系原作者
