前言
selenium脚本写完之后,一般是集成到jenkins环境了,方便一键执行。
一、环境准备
小编环境:
1.win10 64位
2.JDK 1.8.0_66
3.tomcat 9.0.0.M4
4.jenkins 2.0
二、安装JDK
1.安装JDK教程很多,这里就不讲了,可以参考这个链接的教程:JDK安装配置教程_百度经验
在系统环境变量里添加以下变量:
①JAVA_HOME:jdk的安装路径C:\Sun\Java\jdk
②CLASSPATH:“.;%JAVA_HOME%\lib;”
③Path:“;%JAVA_HOME%\bin”
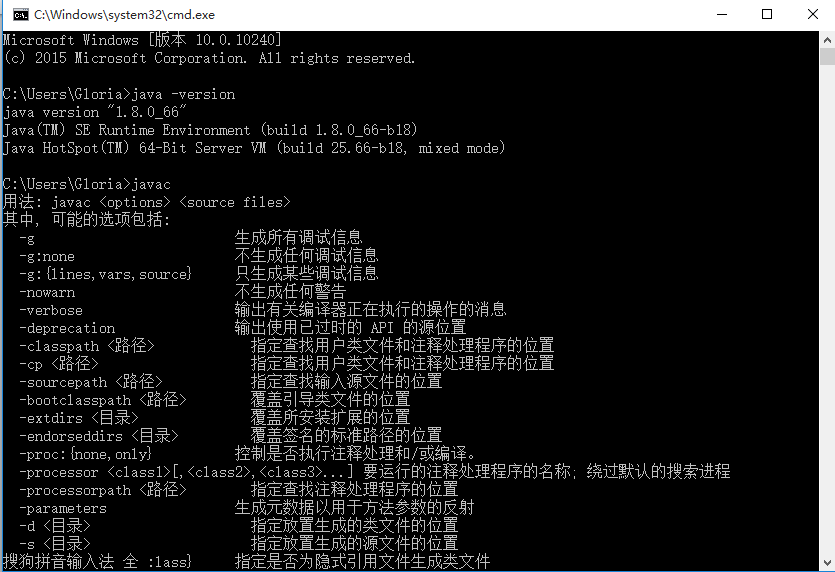
2.检查环境是否成功(这一步很重要)
>>java -version
>>javac
(输入javac一定要看到中文的这些内容)
二、tomcat环境
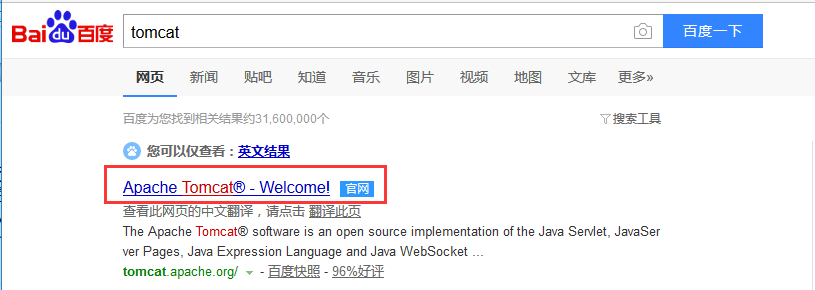
1.打开百度网页,在百度搜索栏里输入关键子:tomcat,在查询结果里点击tomcat官网进行下载。(下软件一定要在官网下载,别乱下,小心塞木马)
2.安装过程,网上也有现成的:tomcat怎样下载安装如何配置环境变量_百度经验
3.tomcat环境变量
在系统变量中添加以下变量windows 7系统安装与配置Tomcat服务器环境_百度经验
1)新建TOMCAT_HOME变量
变量名TOMCAT_HOME
变量值d:\tomcat
变量值即为我们下载的tomcat解压路径,在这里我的是d:\tomcat
2)新建CATALINA_HOME变量
变量名CATALINA_HOME
变量值c:\tomcat
没错,CATALINA_HOME的变量值与TOMCAT_HOME的变量值是一样的。
3)修改变量Path
在系统变量中找到Path变量名,双击或点击编辑,在末尾添加如下内容
;%CATALINA_HOME%\bin;%CATALINA_HOME%\lib
这里要注意,各个变量值之间一定要用;分隔。
三、启动tomcat
1.启动Tomcat服务器
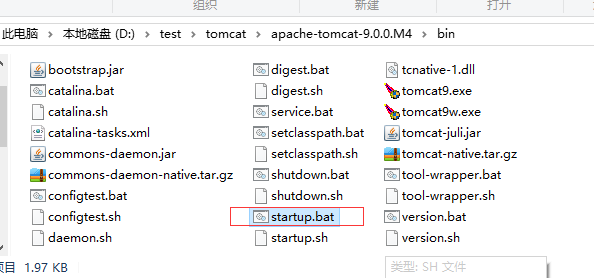
在cmd命令窗口下输入startup.bat回车,运行如下图所示

(装了环境变量就不用切换到目录了)
2.双击启动运行
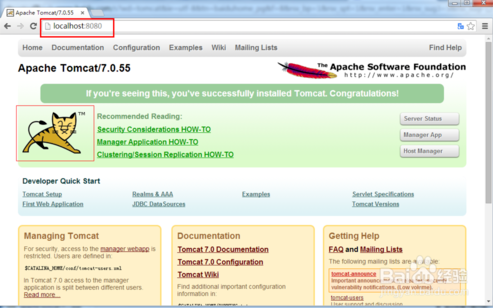
3.Tomcat成功启动后,启动浏览器,在浏览器的地址栏里输入:http://localhost:8080/。然后回车。进入如下画面。此时表示Tomcat已经正确安装
四、jenins环境
1.Jenkins包分两种:
一种是setup.exe客户端包(这个双击跟装QQ一样,就不说了)
一种是war包
2.war包放到webapps下
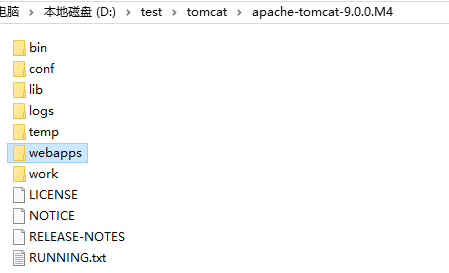
3.启动jenkins
先重启tomcat:startup.bat,然后在浏览器输入http://localhost:8080/jenkins/
五、配置jenkins
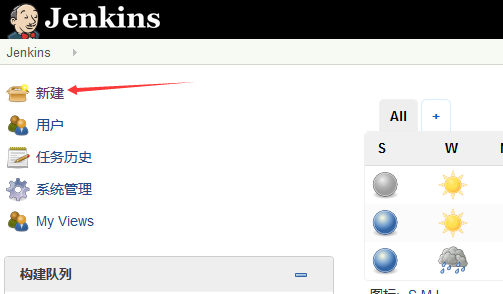
1.新建一个job
2.输入项目名称
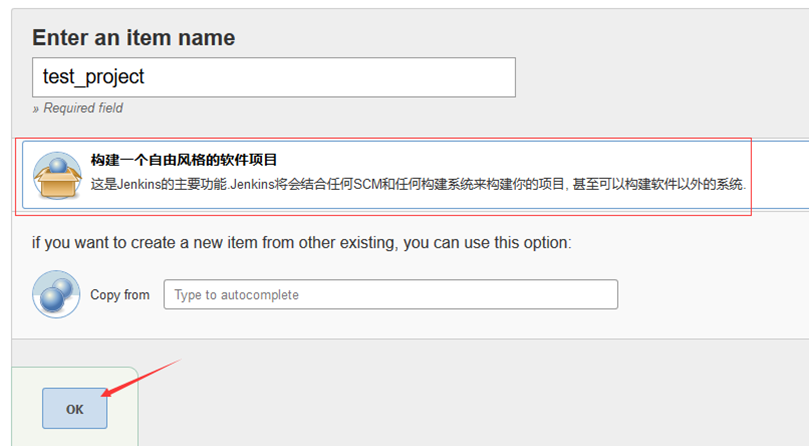
3.构建触发器
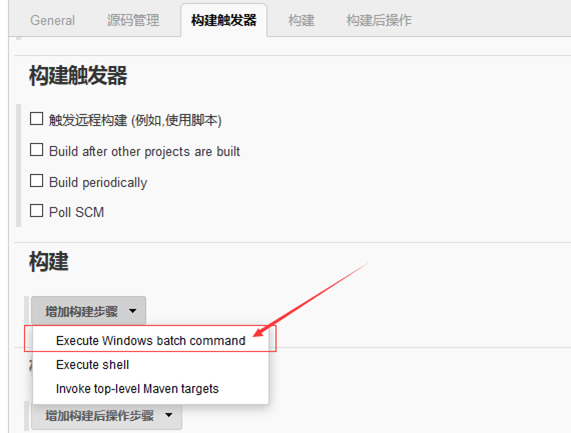
4.配置cmd指令
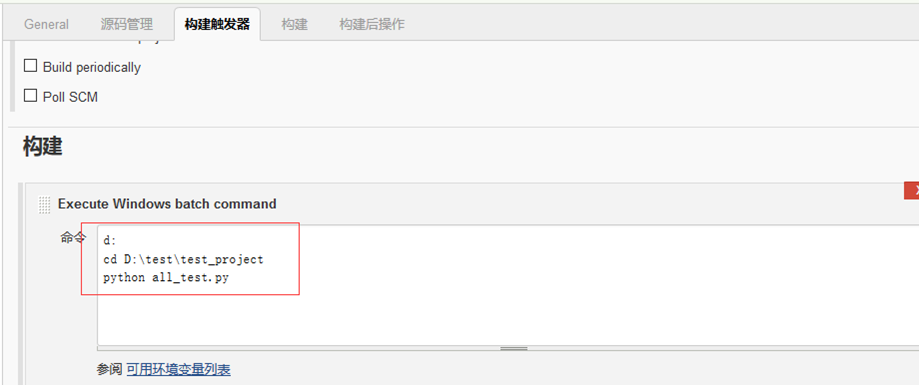
5.选择项目一键执行,启动自动化

(已购买此书的同学,可以在10.1章节,获取对应的jenkins视频教程)
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
也可以关注下我的个人公众号:

selenium+python高级教程》已出书:selenium webdriver基于Python源码案例(购买此书送对应PDF版本)

