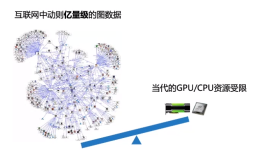
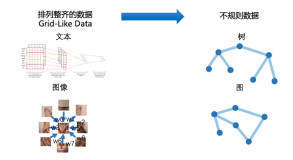
修改的地方:
1. 函数名、数据格式与sklearn一致
2. 增加了网络性能不变时就结束的判断(否则,存在偶然的机会报NaN错误)
# neuralnetwork.py # modified by Robin 2016/04/20 import numpy as np from math import exp, pow from mpl_toolkits.mplot3d import Axes3D import matplotlib.pyplot as plt import sys import copy from scipy.linalg import norm, pinv class Layer: '''层''' def __init__(self, w, b, neure_number, transfer_function, layer_index): self.transfer_function = transfer_function self.neure_number = neure_number self.layer_index = layer_index self.w = w self.b = b class NetStruct: '''神经网络结构''' def __init__(self, ni, nh, no, active_fun_list): # ni 输入层节点(int) # ni 隐藏层节点(int 或 list) # no 输出层节点(int) # active_fun_list 隐藏层激活函数类型(list) # ==> 1 self.neurals = [] # 各层的神经元数目 self.neurals.append(ni) if isinstance(nh, list): self.neurals.extend(nh) else: self.neurals.append(nh) self.neurals.append(no) # ==> 2 if len(self.neurals)-2 == len(active_fun_list): active_fun_list.append('line') self.active_fun_list = active_fun_list # ==> 3 self.layers = [] # 所有的层 for i in range(0, len(self.neurals)): if i == 0: self.layers.append(Layer([], [], self.neurals[i], 'none', i)) continue f = self.neurals[i - 1] s = self.neurals[i] self.layers.append(Layer(np.random.randn(s, f), np.random.randn(s, 1), self.neurals[i], self.active_fun_list[i-1], i)) class NeuralNetwork: '''神经网络''' def __init__(self, net_struct, mu=1e-3, beta=10, tol=0.1): '''初始化''' self.net_struct = net_struct self.mu = mu self.beta = beta self.tol = tol def fit(self, x, y, n_iter=100, method = 'lm'): '''训练''' self.net_struct.x = x.T self.net_struct.y = y.reshape(1, -1) self.n_iter = n_iter if(method == 'lm'): self.lm() def predict(self, x, predict_type='clf'): '''预测''' self.net_struct.x = x.T self.forward() layer_num = len(self.net_struct.layers) pred = self.net_struct.layers[layer_num - 1].output_val pred = pred.reshape(-1,) if predict_type == 'clf': # 分类 return np.where(pred>pred.mean(), 1, -1) elif predict_type == 'reg': # 回归 return pred def score(self, X, y): '''预测效果,只适用于分类,不适用回归''' y0 = self.predict(X, predict_type='clf') return np.sum(y0 == y) / X.shape[0] def actFun(self, z, active_type = 'sigm'): ''' 激活函数 ''' # activ_type: 激活函数类型有 sigm、tanh、radb、line if active_type == 'sigm': f = 1.0 / (1.0 + np.exp(-z)) elif active_type == 'tanh': f = (np.exp(z) + np.exp(-z)) / (np.exp(z) + np.exp(-z)) elif active_type == 'radb': f = np.exp(-z * z) elif active_type == 'line': f = z return f def actFunGrad(self, z, active_type = 'sigm'): '''激活函数的变化(派生)率''' # active_type: 激活函数类型有 sigm、tanh、radb、line y = self.actFun(z, active_type) if active_type == 'sigm': grad = y * (1.0 - y) elif active_type == 'tanh': grad = 1.0 - y * y elif active_type == 'radb': grad = -2.0 * z * y elif active_type == 'line': m = z.shape[0] n = z.shape[1] grad = np.ones((m, n)) return grad def forward(self): ''' 前向 ''' layer_num = len(self.net_struct.layers) for i in range(0, layer_num): if i == 0: curr_layer = self.net_struct.layers[i] curr_layer.input_val = self.net_struct.x curr_layer.output_val = self.net_struct.x continue before_layer = self.net_struct.layers[i - 1] curr_layer = self.net_struct.layers[i] curr_layer.input_val = curr_layer.w.dot(before_layer.output_val) + curr_layer.b curr_layer.output_val = self.actFun(curr_layer.input_val, self.net_struct.active_fun_list[i - 1]) def backward(self): '''反向''' layer_num = len(self.net_struct.layers) last_layer = self.net_struct.layers[layer_num - 1] last_layer.error = -self.actFunGrad(last_layer.input_val, self.net_struct.active_fun_list[layer_num - 2]) layer_index = list(range(1, layer_num - 1)) layer_index.reverse() for i in layer_index: curr_layer = self.net_struct.layers[i] curr_layer.error = (last_layer.w.transpose().dot(last_layer.error)) * self.actFunGrad(curr_layer.input_val,self.net_struct.active_fun_list[i - 1]) last_layer = curr_layer def parDeriv(self): '''标准梯度(求导)''' layer_num = len(self.net_struct.layers) for i in range(1, layer_num): befor_layer = self.net_struct.layers[i - 1] befor_input_val = befor_layer.output_val.transpose() curr_layer = self.net_struct.layers[i] curr_error = curr_layer.error curr_error = curr_error.reshape(curr_error.shape[0]*curr_error.shape[1], 1, order='F') row = curr_error.shape[0] col = befor_input_val.shape[1] a = np.zeros((row, col)) num = befor_input_val.shape[0] neure_number = curr_layer.neure_number for i in range(0, num): a[neure_number*i:neure_number*i + neure_number,:] = np.repeat([befor_input_val[i,:]],neure_number,axis = 0) tmp_w_par_deriv = curr_error * a curr_layer.w_par_deriv = np.zeros((num, befor_layer.neure_number * curr_layer.neure_number)) for i in range(0, num): tmp = tmp_w_par_deriv[neure_number*i:neure_number*i + neure_number,:] tmp = tmp.reshape(tmp.shape[0] * tmp.shape[1], order='C') curr_layer.w_par_deriv[i, :] = tmp curr_layer.b_par_deriv = curr_layer.error.transpose() def jacobian(self): '''雅可比行列式''' layers = self.net_struct.neurals row = self.net_struct.x.shape[1] col = 0 for i in range(0, len(layers) - 1): col = col + layers[i] * layers[i + 1] + layers[i + 1] j = np.zeros((row, col)) layer_num = len(self.net_struct.layers) index = 0 for i in range(1, layer_num): curr_layer = self.net_struct.layers[i] w_col = curr_layer.w_par_deriv.shape[1] b_col = curr_layer.b_par_deriv.shape[1] j[:, index : index + w_col] = curr_layer.w_par_deriv index = index + w_col j[:, index : index + b_col] = curr_layer.b_par_deriv index = index + b_col return j def gradCheck(self): '''梯度检查''' W1 = self.net_struct.layers[1].w b1 = self.net_struct.layers[1].b n = self.net_struct.layers[1].neure_number W2 = self.net_struct.layers[2].w b2 = self.net_struct.layers[2].b x = self.net_struct.x p = [] p.extend(W1.reshape(1,W1.shape[0]*W1.shape[1],order = 'C')[0]) p.extend(b1.reshape(1,b1.shape[0]*b1.shape[1],order = 'C')[0]) p.extend(W2.reshape(1,W2.shape[0]*W2.shape[1],order = 'C')[0]) p.extend(b2.reshape(1,b2.shape[0]*b2.shape[1],order = 'C')[0]) old_p = p jac = [] for i in range(0, x.shape[1]): xi = np.array([x[:,i]]) xi = xi.transpose() ji = [] for j in range(0, len(p)): W1 = np.array(p[0:2*n]).reshape(n,2,order='C') b1 = np.array(p[2*n:2*n+n]).reshape(n,1,order='C') W2 = np.array(p[3*n:4*n]).reshape(1,n,order='C') b2 = np.array(p[4*n:4*n+1]).reshape(1,1,order='C') z2 = W1.dot(xi) + b1 a2 = self.actFun(z2) z3 = W2.dot(a2) + b2 h1 = self.actFun(z3) p[j] = p[j] + 0.00001 W1 = np.array(p[0:2*n]).reshape(n,2,order='C') b1 = np.array(p[2*n:2*n+n]).reshape(n,1,order='C') W2 = np.array(p[3*n:4*n]).reshape(1,n,order='C') b2 = np.array(p[4*n:4*n+1]).reshape(1,1,order='C') z2 = W1.dot(xi) + b1 a2 = self.actFun(z2) z3 = W2.dot(a2) + b2 h = self.actFun(z3) g = (h[0][0]-h1[0][0])/0.00001 ji.append(g) jac.append(ji) p = old_p return jac def jjje(self): '''计算jj与je''' layer_num = len(self.net_struct.layers) e = self.net_struct.y - self.net_struct.layers[layer_num - 1].output_val e = e.transpose() j = self.jacobian() #check gradient #j1 = -np.array(self.gradCheck()) #jk = j.reshape(1,j.shape[0]*j.shape[1]) #jk1 = j1.reshape(1,j1.shape[0]*j1.shape[1]) #plt.plot(jk[0]) #plt.plot(jk1[0],'.') #plt.show() jj = j.transpose().dot(j) je = -j.transpose().dot(e) return[jj, je] def lm(self): '''Levenberg-Marquardt训练算法''' mu = self.mu beta = self.beta n_iter = self.n_iter tol = self.tol y = self.net_struct.y layer_num = len(self.net_struct.layers) self.forward() pred = self.net_struct.layers[layer_num - 1].output_val pref = self.perfermance(y, pred) for i in range(0, n_iter): print('iter:',i, 'error:', pref) #1) 第一步: if(pref < tol): break #2) 第二步: self.backward() self.parDeriv() [jj, je] = self.jjje() while(1): #3) 第三步: A = jj + mu * np.diag(np.ones(jj.shape[0])) delta_w_b = pinv(A).dot(je) #4) 第四步: old_net_struct = copy.deepcopy(self.net_struct) self.updataNetStruct(delta_w_b) self.forward() pred1 = self.net_struct.layers[layer_num - 1].output_val pref1 = self.perfermance(y, pred1) if (pref1 < pref): mu = mu / beta pref = pref1 break if pref - pref1 ==0: # 1e-12: # 修改:若几乎不变了,就停止 return mu = mu * beta self.net_struct = copy.deepcopy(old_net_struct) def updataNetStruct(self, delta_w_b): '''更新网络权重及阈值''' layer_num = len(self.net_struct.layers) index = 0 for i in range(1, layer_num): before_layer = self.net_struct.layers[i - 1] curr_layer = self.net_struct.layers[i] w_num = before_layer.neure_number * curr_layer.neure_number b_num = curr_layer.neure_number w = delta_w_b[index : index + w_num] w = w.reshape(curr_layer.neure_number, before_layer.neure_number, order='C') index = index + w_num b = delta_w_b[index : index + b_num] index = index + b_num curr_layer.w += w curr_layer.b += b def perfermance(self, y, pred): '''性能函数''' error = y - pred return norm(error) / len(y) # 以下函数为测试样例 def plotSamples(n = 40): x = np.array([np.linspace(0, 3, n)]) x = x.repeat(n, axis = 0) y = x.transpose() z = np.zeros((n, n)) for i in range(0, x.shape[0]): for j in range(0, x.shape[1]): z[i][j] = sampleFun(x[i][j], y[i][j]) fig = plt.figure() ax = fig.gca(projection='3d') surf = ax.plot_surface(x, y, z, cmap='autumn', cstride=2, rstride=2) ax.set_xlabel("X-Label") ax.set_ylabel("Y-Label") ax.set_zlabel("Z-Label") plt.show() def sinSamples(n): x = np.array([np.linspace(-0.5, 0.5, n)]) #x = x.repeat(n, axis = 0) y = x + 0.2 z = np.zeros((n, 1)) for i in range(0, x.shape[1]): z[i] = np.sin(x[0][i] * y[0][i]) X = np.zeros((n, 2)) n = 0 for xi, yi in zip(x.transpose(), y.transpose()): X[n][0] = xi X[n][1] = yi n = n + 1 # print(x.shape, y.shape) # print(X.shape, z.shape) #return X, z.transpose() return X, z.reshape(-1,) def peaksSamples(n): x = np.array([np.linspace(-3, 3, n)]) x = x.repeat(n, axis = 0) y = x.transpose() z = np.zeros((n, n)) for i in range(0, x.shape[0]): for j in range(0, x.shape[1]): z[i][j] = sampleFun(x[i][j], y[i][j]) X = np.zeros((n*n, 2)) x_list = x.reshape(n*n,1 ) y_list = y.reshape(n*n,1) z_list = z.reshape(n*n,1) n = 0 for xi, yi in zip(x_list, y_list): X[n][0] = xi X[n][1] = yi n = n + 1 # print(x.shape, y.shape) # print(X.shape, z.shape, z_list.shape, z_list.transpose().shape) #return X,z_list.transpose() return X, z.reshape(-1,) def sampleFun( x, y): z = 3*pow((1-x),2) * exp(-(pow(x,2)) - pow((y+1),2)) - 10*(x/5 - pow(x, 3) - pow(y, 5)) * exp(-pow(x, 2) - pow(y, 2)) - 1/3*exp(-pow((x+1), 2) - pow(y, 2)) return z def test(): active_fun_list = ['sigm','sigm','sigm']# 【必须】设置【各】隐层的激活函数类型,可以设置为tanh,radb,tanh,line类型,如果不显式的设置最后一层为line ns = NetStruct(2, [10, 10, 10], 1, active_fun_list) # 确定神经网络结构,中间两个隐层各10个神经元 nn = NeuralNetwork(ns) # 神经网络类实例化 #[X, z] = peaksSamples(20) # 产生训练数据 [X, z] = sinSamples(20) # 第二个训练数据 nn.fit(X, z) # 训练!!!!!! #[X0, z0] = peaksSamples(40) # 产生测试数据 [X0, z0] = sinSamples(40) # 第二个测试数据 z1 = nn.predict(X0) # 预测!!!!!! fig = plt.figure() ax = fig.add_subplot(111) ax.plot(z0) # 画出真实值 real data ax.plot(z1,'r.') # 画出预测值 predict data plt.legend(('real data', 'predict data')) plt.show() def test_lotto(): import lotto import kline lt = lotto.Lotto() lt.make_real_history() series = lt.mod(7, m=2) kl = kline.KLine(series) X, y, x_last = kl.data_for_predict() active_fun_list = ['sigm','sigm','sigm']# 【必须】设置【各】隐层的激活函数类型,可以设置为tanh,radb,tanh,line类型,如果不显式的设置最后一层为line ns = NetStruct(4, [10, 10], 1, active_fun_list) # 确定神经网络结构,中间两个隐层各10个神经元 nn = NeuralNetwork(ns) # 神经网络类实例化 nn.fit(X, y) # 训练!!!!!! y0 = nn.predict(X) # 预测!!!!!! print(y==y0) print(nn.score(X, y)) # 0.63... def test3(): X = np.array([[1,1,0], [1,0,0], [0,1,1], [0,0,1]]) y = np.array([1,-1,-1,1]) active_fun_list = ['sigm','sigm']# 【必须】设置【各】隐层的激活函数类型,可以设置为tanh,radb,tanh,line类型,如果不显式的设置最后一层为line ns = NetStruct(3, [10], 1, active_fun_list) # 确定神经网络结构,中间两个隐层各10个神经元 nn = NeuralNetwork(ns) # 神经网络类实例化 nn.fit(X, y) # 训练!!!!!! y0 = nn.predict(X) # 预测!!!!!! print(y==y0) print(nn.score(X, y)) # 0.63... # 测试 if __name__ == '__main__': # test() #test_lotto() test3() plotSamples()