一、背景
股民是网络用户的一大群体,他们的网络情绪在一定程度上反映了该股票的情况,也反映了股市市场的波动情况。作为一只时间充裕的研究僧,我课余时间准备写个小代码get一下股民的评论数据,分析用户情绪的走势。代码还会修改,因为结果不准确,哈哈!
二、数据来源
本次项目不用于商用,数据来源于东方财富网,由于物理条件,我只获取了一只股票的部分评论,没有爬取官方的帖子,都是获取的散户的评论。
三、数据获取
Python是个好工具,这次我使用了selenium和PhantomJS组合进行爬取网页数据,当然还是要分析网页的dom结构拿到自己需要的数据。
爬虫部分:
from selenium import webdriver
import time
import json
import re
# from HTMLParser import HTMLParser
from myNLP import *
# from lxml import html
# import requests
class Crawler:
url = ''
newurl = set()
headers = {}
cookies = {}
def __init__(self, stocknum, page):
self.url = 'http://guba.eastmoney.com/list,'+stocknum+',5_'+page+'.html'
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
#cap["phantomjs.page.settings.loadImages"] = False
#cap["phantomjs.page.settings.localToRemoteUrlAccessEnabled"] = True
self.driver = webdriver.PhantomJS(desired_capabilities=cap)
def crawAllHtml(self,url):
self.driver.get(url)
time.sleep(2)
# htmlData = requests.get(url).content.decode('utf-8')
# domTree = html.fromstring(htmlData)
# return domTree
def getNewUrl(self,url):
self.newurl.add(url)
def filterHtmlTag(self, htmlStr):
self.htmlStr = htmlStr
#先过滤CDATA
re_cdata=re.compile('//<!CDATA
[>]∗//
>',re.I) #匹配CDATA
re_script=re.compile('<\s*script[^>]*>[^<]*<\s*/\s*script\s*>',re.I)#Script
re_style=re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>',re.I)#style
re_br=re.compile('<br\s*?/?>')#处理换行
re_h=re.compile('</?\w+[^>]*>')#HTML标签
re_comment=re.compile('<!--[^>]*-->')#HTML注释
s=re_cdata.sub('',htmlStr)#去掉CDATA
s=re_script.sub('',s) #去掉SCRIPT
s=re_style.sub('',s)#去掉style
s=re_br.sub('\n',s)#将br转换为换行
blank_line=re.compile('\n+')#去掉多余的空行
s = blank_line.sub('\n',s)
s=re_h.sub('',s) #去掉HTML 标签
s=re_comment.sub('',s)#去掉HTML注释
#去掉多余的空行
blank_line=re.compile('\n+')
s=blank_line.sub('\n',s)
return s
def getData(self):
comments = []
self.crawAllHtml(self.url)
postlist = self.driver.find_elements_by_xpath('//*[@id="articlelistnew"]/div')
for post in postlist:
href = post.find_elements_by_tag_name('span')[2].find_elements_by_tag_name('a')
if len(href):
self.getNewUrl(href[0].get_attribute('href'))
# if len(post.find_elements_by_xpath('./span[3]/a/@href')):
# self.getNewUrl('http://guba.eastmoney.com'+post.find_elements_by_xpath('./span[3]/a/@href')[0])
for url in self.newurl:
self.crawAllHtml(url)
time = self.driver.find_elements_by_xpath('//*[@id="zwconttb"]/div[2]')
post = self.driver.find_elements_by_xpath('//*[@id="zwconbody"]/div')
age = self.driver.find_elements_by_xpath('//*[@id="zwconttbn"]/span/span[2]')
if len(post) and len(time) and len(age):
text = self.filterHtmlTag(post[0].text)
if len(text):
tmp = myNLP(text)
comments.append({'time':time[0].text,'content':tmp.prob, 'age':age[0].text})
commentlist = self.driver.find_elements_by_xpath('//*[@id="zwlist"]/div')
if len(commentlist):
for comment in commentlist:
time = comment.find_elements_by_xpath('./div[3]/div[1]/div[2]')
post = comment.find_elements_by_xpath('./div[3]/div[1]/div[3]')
age = comment.find_elements_by_xpath('./div[3]/div[1]/div[1]/span[2]/span[2]')
if len(post) and len(time) and len(age):
text = self.filterHtmlTag(post[0].text)
if len(text):
tmp = myNLP(text)
comments.append({'time':time[0].text,'content':tmp.prob, 'age':age[0].text})
return json.dumps(comments) 存储部分:
这部分其实可以用数据库来做,但是由于只是试水,就简单用json文件来存部分数据:
import io
class File:
name = ''
type = ''
src = ''
file = ''
def __init__(self,name, type, src):
self.name = name
self.type = type
self.src = src
filename = self.src+self.name+'.'+self.type
self.file = io.open(filename,'w+', encoding = 'utf-8')
def inputData(self,data):
self.file.write(data.decode('utf-8'))
self.file.close()
def closeFile(self):
self.file.close() 测试用的local服务器:
这里只是为了要用浏览器浏览数据图,由于需要读取数据,js没有权限操作本地的文件,只能利用一个简单的服务器来弄了:
import SimpleHTTPServer
import SocketServer;
PORT = 8000
Handler = SimpleHTTPServer.SimpleHTTPRequestHandler
httpd = SocketServer.TCPServer(("", PORT), Handler);
httpd.serve_forever() NLP部分:snowNLP这个包还是用来评价买卖东西的评论比较准确
不是专门研究自然语言的,直接使用他人的算法库。这个snowNLP可以建立一个训练,有空自己来弄一个关于股票评论的。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
from snownlp import SnowNLP
class myNLP:
prob = 0.5
def _init_(self, text):
self.prob = SnowNLP(text).sentiments 主调度:
# -*- coding: UTF-8 -*-
'''''
Created on 2017年5月17日
@author: luhaiya
@id: 2016110274
@description:
'''
#http://data.eastmoney.com/stockcomment/ 所有股票的列表信息
#http://guba.eastmoney.com/list,600000,5.html 某只股票股民的帖子页面
#http://quote.eastmoney.com/sh600000.html?stype=stock 查询某只股票
from Crawler import *
from File import *
import sys
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
def main():
stocknum = str(600000)
total = dict()
for i in range(1,10):
page = str(i)
crawler = Crawler(stocknum, page)
datalist = crawler.getData()
comments = File(stocknum+'_page_'+page,'json','./data/')
comments.inputData(datalist)
data = open('./data/'+stocknum+'_page_'+page+'.json','r').read()
jsonData = json.loads(data)
for detail in jsonData:
num = '1' if '年' not in detail['age'].encode('utf-8') else detail['age'].encode('utf-8').replace('年','')
num = float(num)
date = detail['time'][4:14].encode('utf-8')
total[date] = total[date] if date in total.keys() else {'num':0, 'content':0}
total[date]['num'] = total[date]['num'] + num if total[date]['num'] else num
total[date]['content'] = total[date]['content'] + detail['content']*num if total[date]['content'] else detail['content']*num
total = json.dumps(total)
totalfile = File(stocknum,'json','./data/')
totalfile.inputData(total)
if __name__ == "__main__":
main() 四、前端数据展示
使用百度的echarts。用户的情绪是使用当天所有评论的情绪值的加权平均,加权系数与用户的股龄正相关。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>分析图表</title>
<style>
body{texr-align:center;}
#mainContainer{width:100%;}
#fileContainer{width:100%; text-align:center;}
#picContainer{width: 800px;height:600px;margin:0 auto;}
</style>
</head>
<body>
<div id = 'mainContainer'>
<div id = 'fileContainer'>这里是文件夹列表</div>
<div id = 'picContainer'></div>
</div>
<script src="http://apps.bdimg.com/libs/jquery/2.1.1/jquery.min.js"></script>
<script src = "./echarts.js"></script>
<script>
main();
function main(){
var stocknum = 600000;
getDate(stocknum);
}
function getDate(stocknum){
var src = "./data/"+stocknum+".json";
$.getJSON(src, function (res){
var date = [];
for(var key in res){
key = key.replace('-','/').replace('-','/');
date.push(key);
}
date.sort();
data = [];
for (var i = 0; i < date.length; i++) {
dat = date[i].replace('/','-').replace('/','-');
data.push(res[dat]['content']/res[dat]['num']);
}
drawPic(date,data);
})
}
function drawPic(date, data){
//initialize and setting options
var myChart = echarts.init(document.getElementById('picContainer'));
option = {
tooltip: {
trigger: 'axis',
position: function (pt) {
return [pt[0], '10%'];
}
},
title: {
left: 'center',
text: '股票情绪走向图',
},
toolbox: {
feature: {
dataZoom: {
yAxisIndex: 'none'
},
restore: {},
saveAsImage: {}
}
},
xAxis: {
type: 'category',
boundaryGap: false,
data: date
},
yAxis: {
type: 'value',
boundaryGap: [0, '100%']
},
dataZoom: [{
type: 'inside',
start: 0,
end: 10
}, {
start: 0,
end: 10,
handleIcon: 'M10.7,11.9v-1.3H9.3v1.3c-4.9,0.3-8.8,4.4-8.8,9.4c0,5,3.9,9.1,8.8,9.4v1.3h1.3v-1.3c4.9-0.3,8.8-4.4,8.8-9.4C19.5,16.3,15.6,12.2,10.7,11.9z M13.3,24.4H6.7V23h6.6V24.4z M13.3,19.6H6.7v-1.4h6.6V19.6z',
handleSize: '80%',
handleStyle: {
color: '#fff',
shadowBlur: 3,
shadowColor: 'rgba(0, 0, 0, 0.6)',
shadowOffsetX: 2,
shadowOffsetY: 2
}
}],
series: [
{
name:'stocknum',
type:'line',
smooth:true,
symbol: 'none',
sampling: 'average',
itemStyle: {
normal: {
color: 'rgb(255, 70, 131)'
}
},
areaStyle: {
normal: {
color: new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0,
color: 'rgb(255, 158, 68)'
}, {
offset: 1,
color: 'rgb(255, 70, 131)'
}])
}
},
data: data
}
]
};
//draw pic
myChart.setOption(option);
}
</script>
</body>
</html> 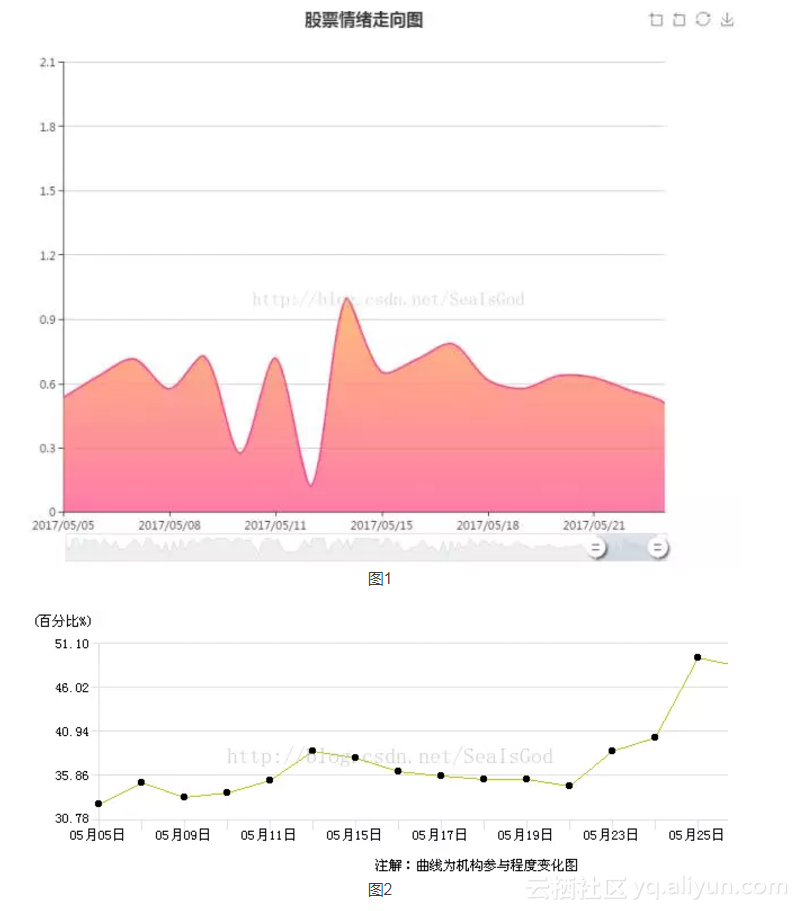
图1是我分析用户情绪画出的时间推进图,理论上小于0.5表消极情绪,大于0.5表示积极情绪。图2是实际股价的走势。
原文发布时间为:2017-12-12
