执行存储过程时,execute和call的区别
EXEC is a sqlplus command that put its argument as an anonymous pl/sql block: 'EXEC xxx' is transformed to 'BEGIN xxx; END;'
So you can use it to call a procedure, or do any pl/sql
It is documented here: http://download.oracle.com/docs/cd/B19306_01/server.102/b14357/ch12022.htm#i2697931
CALL is a SQL statement that calls a stored procedure It is the 'standard' way to call a procedure without doing pl/sql.
For example if you call a procedure from JDBC it uses CALL to call the procedure and return parameters.
It is documented here: http://download.oracle.com/docs/cd/B19306_01/server.102/b14200/statements_4008.htm#BABDEHHG
Now about v$sql, I can see both:
执行存储过程
SQL> set serveroutput on
SQL> execute dbms_output.put_line('test string1')
test string1
PL/SQL procedure successfully completed.
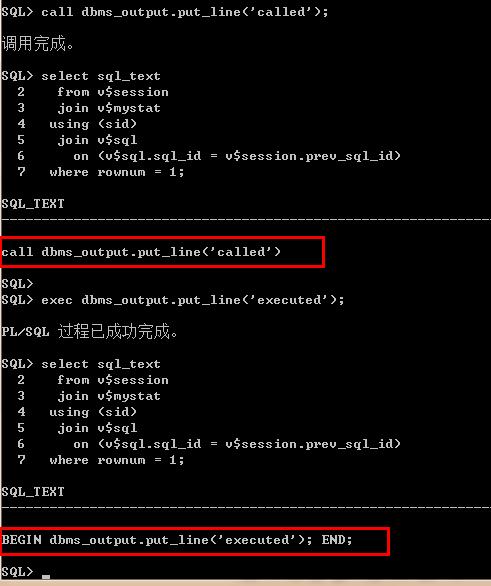
SQL> call dbms_output.put_line('called'); 调用完成。 SQL> select sql_text 2 from v$session 3 join v$mystat 4 using (sid) 5 join v$sql 6 on (v$sql.sql_id = v$session.prev_sql_id) 7 where rownum = 1; SQL_TEXT ---------------------------------------------------------------- call dbms_output.put_line('called') SQL> SQL> exec dbms_output.put_line('executed'); PL/SQL 过程已成功完成。 SQL> select sql_text 2 from v$session 3 join v$mystat 4 using (sid) 5 join v$sql 6 on (v$sql.sql_id = v$session.prev_sql_id) 7 where rownum = 1; SQL_TEXT ---------------------------------------------------------------- BEGIN dbms_output.put_line('executed'); END; SQL>
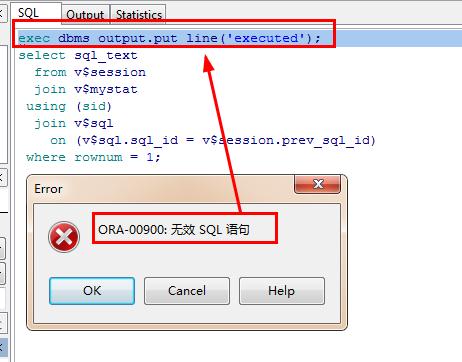
上面的测试sql,使用PL/SQL developer无法得到预期的结果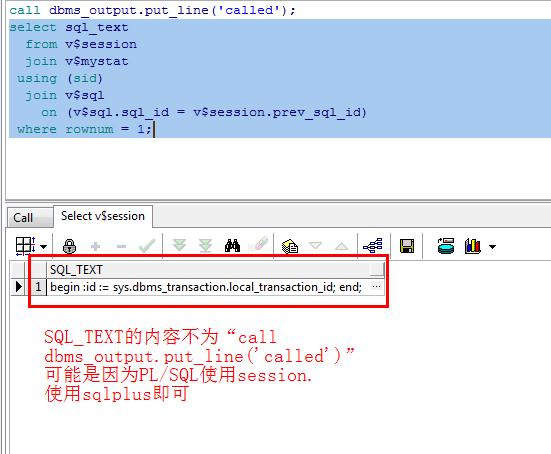
oracle中斜杠(/)的含义
斜杠就是让服务器执行前面所写的sql脚本。如果是普通的select语句,一个分号,就可以执行了。但是如果是存储过程,那么遇到分号,就不能马上执行了。这个时候,就需要通过斜杠(/)来执行。
set serveroutput on;
begin
dbms_output.put_line('Hello World!');
end;
/
执行运行结果:
Hello World!
PL/SQL procedure successfully completed
dbms_output包主要用于调试pl/sql程序,或者在sql*plus命令中显示信息(displaying message)和报表,譬如我们可以写一个简单的匿名pl/sql程序块,而该块出于某种目的使用dbms_output包来显示一些信息。
涉及到的知识点如下:
1、enable:在serveroutput on的情况下,用来使dbms_output生效(默认即打开)
2、disable:在serveroutput on的情况下,用来使dbms_output失效
3、put:将内容写到内存,等到put_line时一起输出
4、put_line:不用多说了,输出字符,清空buffer
5、new_line:作为一行的结束,可以理解为写入buffer时的换行符
6、get_line(value, index):获取缓冲区的单行信息
7、get_lines(array, index):以数组形式来获取缓冲区的多行信息
需要注意以下几点:
1、set serveroutput on:如果要在sqlplus中看到dbms_output的输出,则必须设置该参数值为on
2、每行能容纳的最大值是32767bytes
3、buffer的默认值是20000bytes,可设置的最小值为2000bytes,最大值为1000000bytes
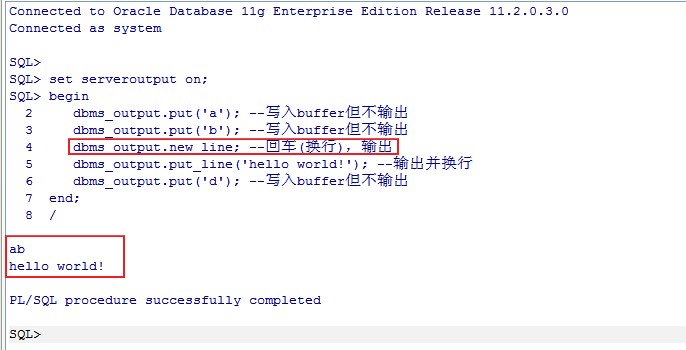
例子一、put和new_line
set serveroutput on; begin dbms_output.put('a'); --写入buffer但不输出 dbms_output.put('b'); --写入buffer但不输出 dbms_output.new_line; --回车(换行),输出 dbms_output.put_line('hello world!'); --输出并换行 dbms_output.put('d'); --写入buffer但不输出 end; /
例子二、put_line
set serveroutput off; create table t(a int, b int, c int); insert into t values(111111,222222,333333); insert into t values(444444,555555,666666); insert into t values(777777,888888,999999); commit; create table tt(a int,b varchar2(100)); declare msg varchar2(120); cursor t_cur is select * from t order by a; v_line varchar2(100); v_status integer := 0; begin dbms_output.enable; for i in t_cur loop msg := i.a || ',' || i.b || ',' || i.c; dbms_output.put_line(msg); --put end loop; dbms_output.get_line(v_line, v_status); --get while v_status = 0 loop insert into tt values(v_status, v_line); dbms_output.get_line(v_line, v_status); end loop; end; / select * from tt;
执行结果如下:
a b
--- -----------------------
0 111111,222222,333333
0 444444,555555,666666
0 777777,888888,999999
注:使用get_line时不能用put_line输出,因为put_line之后会将buffer清空。(当然在serveroutput off的情况下put_line是不影响buffer的)。
例子三:put_lines
set serveroutput on; declare v_data dbms_output.chararr; v_numlines number; begin --enable the buffer first. dbms_output.enable(1000000); dbms_output.put_line('line one'); dbms_output.put_line('line two'); dbms_output.put_line('line three'); v_numlines := 3; dbms_output.get_lines(v_data, v_numlines); --array, index for v_counter in 1..v_numlines loop dbms_output.put_line(v_data(v_counter)); end loop; end; /
执行结果如下:
line one
line two
line three
http://www.cnblogs.com/linjiqin/archive/2013/06/24/3152647.html
一、过程 (存储过程)
过程是一个能执行某个特定操作的子程序。使用CREATE OR REPLACE创建或者替换保存在数据库中的一个子程序。
示例1:声明存储过程,该过程返回dept表行数DECLARE PROCEDURE getDeptCount AS deptCount INT; BEGIN SELECT COUNT(*) INTO deptCount FROM DEPT; DBMS_OUTPUT.PUT_LINE('DEPT表的共有记录数:'||deptCount); END getDeptCount; BEGIN getDeptCount[()]; END;
注意:此存储过程getDeptCount只在块运行时有效。
示例2:创建不带参数的存储过程,该过程返回dept表行数CREATE OR REPLACE PROCEDURE getDeptCount AS | IS deptCount int; BEGIN SELECT COUNT(*) INTO deptCount FROM dept; DBMS_OUTPUT.PUT_LINE('dept表共有'||deptCount||'行记录'); END [getDeptCount];
当我们创建的存储过程没有参数时,在存储过程名字后面不能有括号。在AS或者IS后至BEGIN之前是声明部分,存储过程中的声明不使用DECLARE关键字。同匿名PL/SQL块一样,EXCEPTION和声明部分都是可选的。
当我们创建的过程带有错误时,我们可以通过SELECT * FROM USER_ERRORS查看,或者使用SHOW ERRORS [ PROCEDURE Proc_Name]查看。
使用以下代码可以执行存储过程:BEGIN getDeptCount; END; 以上存储过程还可以通过以下代码来简化调用: EXEC getDeptCount[;] CALL getDeptCount();
注意:
- 并不是所有的存储过程都可以用这种方式来调用
- 定义无参存储过程时,存储过程名后不能加()
- 在块中或是通过EXEC调用存储过程时可以省略()
- 通过CALL调用无参存储过程必须加上()
示例3:创建带有输入参数的存储过程,该过程通过员工编号打印工资额
CREATE OR REPLACE PROCEDURE getSalaryByEmpNo(eNo NUMBER) --参数的数据类型不能指定长度 AS salary emp.sal%TYPE; BEGIN SELECT SAL INTO salary FROM EMP WHERE EMPNO=eNo; DBMS_OUTPUT.PUT_LINE(eNo||'号员工的工资为'||salary); EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE('没有找到该编号的员工'); END;
当定义的存储过程含有参数时,参数的数据类型不能指定长度。参数还有输入和输出之分,本例中没有指定,默认情况为输入参数,也可显示的指定某个参数是输入参数,如(eNo IN NUMBER)。同示例1不同,该例中加入了异常处理。同示例1类似可以使用下面的两种方式调用存储过程:
BEGIN
getSalaryByEmpNo(7788);
END;
或者
EXEC getSalaryByEmpNo(7788); 或者
CALL getSalaryByEmpNo(7788);
但是如果传给一个存储过程的参数是变量时,必须使用BEGIN END块,如下:DECLARE no emp.empNo%TYPE; BEGIN no:=7788; getSalaryByEmpNo(no); END;
如果某个包中含有常量,也可以通过如下的方式调用:
EXEC getSalaryByEmpNo(ConstantPackage.no);
但这种方式不能再使用CALL调用。
示例4:创建含有输入和输出参数的存储过程,该过程通过员工编号查找工资额,工资额以输出参数返回CREATE OR REPLACE PROCEDURE getSalaryByEmpNo(eNo IN NUMBER,salary OUT NUMBER) AS BEGIN SELECT SAL INTO salary FROM EMP WHERE EMPNO=eNo; EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE('没有找到该编号的员工'); END;
当过程中含有输出参数时,调用时必须通过BEGIN END块,不能通过EXEC或CALL调用。如:
DECLARE salary NUMBER(7,2); BEGIN getSalaryByEmpNo(7788,salary); DBMS_OUTPUT.PUT_LINE(salary); END;
示例5:创建参数类型既是输入参数也是输出参数的过程
CREATE OR REPLACE PROCEDURE getSalaryByEmpNo(noSalary IN OUT NUMBER) AS BEGIN SELECT SAL INTO noSalary FROM EMP WHERE EMPNO=noSalary; EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE('没有找到该编号的员工'); END;
调用如下:
DECLARE no NUMBER(7,2); BEGIN no:=7788; getSalaryByEmpNo(no); DBMS_OUTPUT.PUT_LINE(no); END;
示例6:创建带有默认值的过程
CREATE OR REPLACE PROCEDURE addEmp ( empNo NUMBER, eName VARCHAR2, job VARCHAR2 :='CLERK', mgr NUMBER, hiredate DATE DEFAULT SYSDATE, sal NUMBER DEFAULT 1000, comm NUMBER DEFAULT 0, deptNo NUMBER DEFAULT 30 ) AS BEGIN INSERT INTO emp VALUES(empNo,eName,job,mgr,hiredate,sal,comm,deptNo); END;
调用如下:
EXEC addEmp(7776,'zhangsan','CODER',7788,'06-1月-2000',2000,0,10); --没有使用默认值 EXEC addEmp(7777,'lisi','CODER',7788,'06-1月-2000',2000,NULL,10); --可以使用NULL值 EXEC addEmp(7778,'wangwu',mgr=>7788); --使用默认值 EXEC addEmp(mgr=>7788,empNo=>7779,eName=>'sunliu'); --更改参数顺序
示例7:使用NOCOPY编译提示
当参数是大型数据结构时,如集合、记录和对象实例,把它们的内容全部拷贝给形参会降低执行速度,消耗大量内存。为了防止这样的情况发生,我们可以使用 NOCOPY提示来让编译器按引用传递方式给IN OUT模式的参数。DECLARE TYPE DeptList IS TABLE OF VARCHAR2(10); dList DeptList:=DeptList('CORESUN','CORESUN','CORESUN','CORESUN'); PROCEDURE My_Proc(d IN OUT NOCOPY DeptList) AS...
注意:NOCOPY只是一个提示,而不是指令。即使有时候我们使用了NOCOPY,但编译器有可能仍然会进行值拷贝。通常情况下NOCOPY是可以成功的。
二、维护过程
1、删除存储过程
DROP PROCEDURE Proc_Name;
2、查看过程状态
SELECT object_name,status FROM USER_OBJECTS WHERE object_type='PROCEDURE';
3、重新编译过程
ALTER PROCEDURE Proc_Name COMPILE;
4、查看过程代码
SELECT * FROM USER_SOURCE WHERE TYPE='PROCEDURE';
三、参数的理解
-- 输出参数不可以修改解决的方法有两种
--1 把参数改成输入参数
--2 就是参数改成 可输入输出的参数;
调用过程的 三个方式
1 就是使用call
在只用call方式调用函数的时候,必须加要括号,有参数,还要加参数值
这个方式在命令窗口,调用过程,将不会出现输入的数据.
2 就是使用exec 命令,进行命令调用过程, 使用命令,就必须在命令行里面输入
过程名,这个命令窗口中,可加可不加() ,如果有参数的,就一定要加,还有参数值,参数值的类型要与
变量类型相同.
3 在语句块中进行调用过程,这个方式和命令模式类似,他们都是可要可不要(),
-- 在2 和 3 中的 没有括号的情况是,过程没有参数 ,如果有,就必须要有()
输出参数的特点
1 一个过程中,如果有输出参数(OUT 参数),在调用过程的使用,也要传入一个参数, 这个参数可以不用在调用的地方
进行赋值,就直接传入一个声明好的一个变量,用来接受存储过程中的输出参数的值(OUT 参数)
2 输入参数 值不可以改变在过程中,
注意: 在存储过程中,他的参数类型不可以设置它的大小 ;
例如;CREATE OR REPLACE PROCEDURE hello( p_name IN VARCHAR2(12), p_age OUT NUMBER(10,2) ) IS BEGIN
如果有输出参数就必须有有一个参数进行接收 ;
CREATE OR REPLACE PROCEDURE hello( p_name IN VARCHAR2, p_age OUT emp.sal%TYPE ) IS BEGIN SELECT emp.sal + 3131 INTO p_age FROM emp WHERE empno = 7788 ; dbms_output.put_line( p_age); END ;
--------- 块中调用方法
DECLARE v_nanme varchar2(12); v_age NUMBER (12,2); BEGIN hello (v_nanme,v_age); dbms_output.put_line(v_age); END ;
-- 在这个过程中 传入的v_age 就是接受 存储过程输出参数的值 ; 类似于Java的中的返回值
-- 理解 in out 参数
CREATE OR REPLACE PROCEDURE hello1 (
p_name IN OUT emp.ename%TYPE
)
IS BEGIN -- SELECT emp.ename INTO p_name FROM emp ; p_name:='a;sk , ' || p_name ; END ; -------------------------------------------------------------------------- DECLARE v_nanme varchar2(12); BEGIN v_nanme:='12312'; hello1(v_nanme);
补充:sqlplus中执行含有输出参数为游标的存储过程
实例6:
sqlplus创建存储过程,使用如下:
SQL>create or replace procedure test1(rcursor out sys_refcursor) as begin open rcursor for select decode(row_number() over(partition by deptno order by ename), 1, deptno, null) deptno, t.ename from scott.emp t; end; /
--使用sqlplus执行上面创建的带有游标输出参数的存储过程
SQL> var cur refcursor
SQL> exec test1(:cur);
PL/SQL procedure successfully completed.
SQL> print cur; DEPTNO ENAME ---------- ---------- 10 CLARK KING MILLER 20 ADAMS FORD JONES SCOTT SMITH 30 ALLEN BLAKE JAMES DEPTNO ENAME ---------- ---------- MARTIN TURNER WARD 14 rows selected.
Email:gaojun_le@163.com
http://www.cnblogs.com/gaojun/archive/2012/12/21/2827494.html

