原文 http://www.cnblogs.com/qinjian123/p/3240702.html
一、前言
从 SQL Server 2005 开始,就增加了 xml 字段类型,也就是说可以直接把 xml 内容存储在该字段中,并且 SQL Server 会把它当作 xml 来对待,而不是当作 varchar 来对待。
随着SQL Server 对XML字段的支持,相应的,T-SQL语句也提供了大量对XML操作的功能来配合SQL Server中XML字段的使用。本文主要说明如何使用SQL语句对XML进行操作。
二、定义XML字段
在进行数据库的设计中,我们可以在表设计器中,很方便的将一个字段定义为XML类型。需要注意的是,XML字段不能用来作为主键或者索引键。同样,我们也 可以使用SQL语句来创建使用XML字段的数据表,下面的语句创建一个名为“docs”的表,该表带有整型主键“pk”和非类型化的 XML 列“xCol”:
CREATE TABLE docs (pk INT PRIMARY KEY, xCol XML not null)
XML类型除了在表中使用,还可以在存储过程、事务、函数等中出现。下面我们来完成我们对XML操作的第一步,使用SQL语句定义一个XML类型的数据,并为它赋值:
set @xmlDoc='<?xml version="1.0" ?>
<books>
<book id="0001">
<title>C Program</title>
<author>David</author>
<price>21</price>
</book>
<book id="0002">
<title>你必须知道的.NET</title>
<author>王涛</author>
<price>79</price>
</book>
</books>'
select @xmlDoc
三、XML字段注意点
- SQL Server 中以 Unicode(UTF-16) 来存储 XML 数据。
- XML 字段最多可存储 2G 的数据。
- 可以像插入字符串一样向 XML 字段写入内容。
- 当在 xml 数据类型实例中存储 XML 数据时,不会保留 XML 声明(如 <?xml version='1.0'?>)。
- 插入的 xml 内容的属性的顺序可能会与原 xml 实例的顺序变化。
- 不保留属性值前后的单引号和双引号。
- 不保留命名空间前缀。
- 可以对 XML 字段中的 XML 内容建立索引。
- 可以对 XML 字段中的 XML 内容建立约束,比如 age 节点必须大于等于 18。
- 可以通过创建架构来对 XML 进行类型化,比如让 xml 内容的 <user> 节点下面必须有 <fullname> 节点。
四、查询操作
在定义了一个XML类型的数据之后,我们最常用的就是查询操作,下面我们来介绍如何使用SQL语句来进行查询操作的。
在T-Sql中,提供了两个对XML类型数据进行查询的函数,分别是query(xquery)和value(xquery, dataType),其中,query(xquery)得到的是带有标签的数据,而value(xquery, dataType)得到的则是标签的内容。接下类我们分别使用这两个函数来进行查询。
1、使用query(xquery) 查询
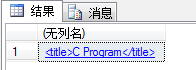
我们需要得到书的标题(title),使用query(xquery)来进行查询,查询语句为:
select @xmlDoc.query('(books/book/title)[1]')
运行结果如图:
2、使用value(xquery, dataType) 查询
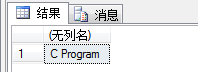
同样是得到书的标题,使用value函数,需要指明两个参数,一个为xquery, 另一个为得到数据的类型。看下面的查询语句:
select @xmlDoc.value('(books/book/title)[1]', 'nvarchar(max)')
运行结果如图:
3、查询属性值
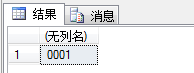
无论是使用query还是value,都可以很容易的得到一个节点的某个属性值,例如,我们很希望得到book节点的id,我们这里使用value方法进行查询,语句为:
select @xmlDoc.value('(books/book/@id)[1]', 'nvarchar(max)')
运行结果如图:
4、使用xpath进行查询
xpath是.net平台下支持的,统一的Xml查询语句。使用XPath可以方便的得到想要的节点,而不用使用where语句。例如,
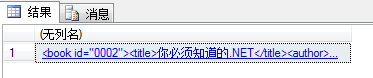
--得到id为0002的book节点
select @xmlDoc.query('(/books/book[@id="0002"])')
上面的语句可以独立运行,它得到的是id为0002的节点。运行结果如下
五、修改操作
SQL的修改操作包括更新和删除。SQL提供了modify()方法,实现对Xml的修改操作。modify方法的参数为XML修改语言。XML修改语言类似于SQL 的Insert、Delete、UpDate,但并不一样。
1、修改节点值
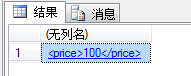
我们希望将id为0001的书的价钱(price)修改为100, 我们就可以使用modify方法。代码如下:
set @xmlDoc.modify('replace value of (/books/book[@id=0001]/price/text())[1] with "100"')
--得到id为0001的book节点
select @xmlDoc.query('(/books/book[@id="0001"])')
注意:modify方法必须出现在set的后面。运行结果如图:
2、删除节点
接下来我们来删除id为0002的节点,代码如下:
--删除节点id为0002的book节点
set @xmlDoc.modify('delete /books/book[@id=0002]')
select @xmlDoc
运行结果如图:

3、添加节点
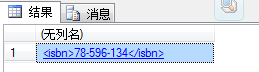
很多时候,我们还需要向xml里面添加节点,这个时候我们一样需要使用modify方法。下面我们就向id为0001的book节点中添加一个ISBN节点,代码如下:
--添加节点
set @xmlDoc.modify('insert <isbn>78-596-134</isbn> before (/books/book[@id=0001]/price)[1]')
select @xmlDoc.query('(/books/book[@id="0001"]/isbn)')
运行结果如图:
4、添加和删除属性
当你学会对节点的操作以后,你会发现,很多时候,我们需要对节点进行操作。这个时候我们依然使用modify方法,例如,向id为0001的book节点中添加一个date属性,用来存储出版时间。代码如下:
--添加属性
set @xmlDoc.modify('insert attribute date{"2008-11-27"} into (/books/book[@id=0001])[1]')
select @xmlDoc.query('(/books/book[@id="0001"])')
运行结果如图:

如果你想同时向一个节点添加多个属性,你可以使用一个属性的集合来实现,属性的集合可以写成:(attribute date{"2008-11-27"}, attribute year{"2008"}),你还可以添加更多。这里就不再举例了。
5、删除属性
删除一个属性,例如删除id为0001 的book节点的id属性,我们可以使用如下代码:
--删除属性
set @xmlDoc.modify('delete books/book[@id="0001"]/@id')
select @xmlDoc.query('(/books/book)[1]')
运行结果如图:

6、修改属性
修改属性值也是很常用的,例如把id为0001的book节点的id属性修改为0005,我们可以使用如下代码:
--修改属性
set @xmlDoc.modify('replace value of ( books/book[@id="0001"]/@id)[1] with "0005"')
select @xmlDoc.query('(/books/book)[1]')
运行结果如图:

经过上面的学习,相信你已经可以很好的在SQL中使用Xml类型了,下面是我们没 有提到的:exist()方法,用来判断指定的节点是否存在,返回值为true或false; nodes()方法,用来把一组由一个查询返回的节点转换成一个类似于结果集的表中的一组记录行。 你可以去MSDN查阅 http://msdn.microsoft.com/zh-cn/library/ms190798.aspx。

