前言
在使用 Lambda 表达式时,我们常会碰到一些典型的应用场景,而从常用场景中抽取出来的应用方式可以描述为应用模式。这些模式可能不全是新的模式,有的参考自 JavaScript 的设计模式,但至少我看到了一些人为它们打上了名字标签。无论名字的好与坏,我还是决定给这些模式进行命名,至少这些名字很具有描述性。同时我也会给出这些模式的可用性、强大的部分和危险的部分。提前先说明:绝大多数模式是非常强大的,但有可能在代码中引入些潜在的 Bug。所以,慎用。
目录导航
- 回调模式 (Callback Pattern)
- 函数作为返回值 (Returning Functions)
- 自定义函数 (Self-Defining Functions)
- 立即调用的函数表达式 (Immediately-Invoked Function Expression)
- 对象即时初始化 (Immediate Object Initialization)
- 初始化时间分支(Init-Time Branching)
- 延迟加载 (Lazy Loading)
- 属性多态模式 (Lambda Property Polymorphism Pattern)
- 函数字典模式 (Function Dictionary Pattern)
- 函数式特性 (Functional Attribute Pattern)
- 避免循环引用 (Avoiding cyclic references)
回调模式 (Callback Pattern)
老生常谈了。事实上,在 .NET 的第一个版本中就已经支持回调模式了,但形式有所不同。现在通过 Lambda 表达式中的闭包和局部变量捕获,这个功能变得越来越有趣了。现在我们的代码可以类似于:
1 void CreateTextBox() 2 { 3 var tb = new TextBox(); 4 tb.IsReadOnly = true; 5 tb.Text = "Please wait ..."; 6 DoSomeStuff(() => 7 { 8 tb.Text = string.Empty; 9 tb.IsReadOnly = false; 10 }); 11 } 12 13 void DoSomeStuff(Action callback) 14 { 15 // Do some stuff - asynchronous would be helpful ... 16 callback(); 17 }
对于 JavaScript 开发人员,这个模式已经没什么新鲜的了。而且通常我们在大量的使用这种模式,因为其非常的有用。例如我们可以使用时间处理器作为参数来处理 AJAX 相关的事件等。在 LINQ 中,我们也使用了这个模式,例如 LINQ 中的 Where 会在每次迭代中回调查询函数。这些仅是些能够说明回调模式非常有用的简单的示例。在 .NET 中,通常推荐使用事件回调机制。原因有两点,一是已经提供了特殊的关键字和类型模式(有两个参数,一个是发送者,一个数事件参数,而发送者通常是 object 类型,而事件参数通常从 EventArgs 继承),同时通过使用 += 和 -+ 操作符,也提供了调用多个方法的机会。
函数作为返回值 (Returning Functions)
就像常见的函数一样,Lambda 表达式可以返回一个函数指针(委托实例)。这就意味着我们能够使用一个 Lambda 表达式来创建并返回另一个 Lambda 表达式。这种行为在很多场景下都是非常有用的。我们先来看下面这个例子:
1 Func<string, string> SayMyName(string language) 2 { 3 switch (language.ToLower()) 4 { 5 case "fr": 6 return name => 7 { 8 return "Je m'appelle " + name + "."; 9 }; 10 case "de": 11 return name => 12 { 13 return "Mein Name ist " + name + "."; 14 }; 15 default: 16 return name => 17 { 18 return "My name is " + name + "."; 19 }; 20 } 21 } 22 23 void Main() 24 { 25 var lang = "de"; 26 //Get language - e.g. by current OS settings 27 var smn = SayMyName(lang); 28 var name = Console.ReadLine(); 29 var sentence = smn(name); 30 Console.WriteLine(sentence); 31 }
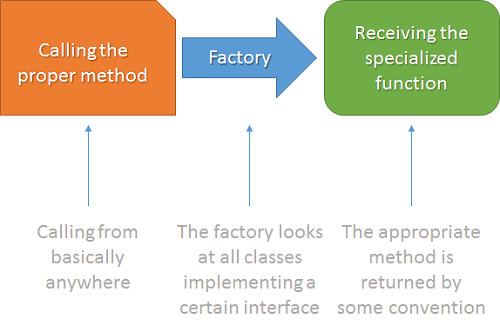
这段代码可以写的更简洁些。如果请求的语言类型未找到,我们可以直接抛出一个异常,以此来避免返回一个默认值。当然,出于演示的目的,这个例子展示了类似于一种函数工厂。另外一种方式是引入 Hashtable ,或者更好的 Dictionary<K, V> 类型。
1 static class Translations 2 { 3 static readonly Dictionary<string, Func<string, string>> smnFunctions 4 = new Dictionary<string, Func<string, string>>(); 5 6 static Translations() 7 { 8 smnFunctions.Add("fr", name => "Je m'appelle " + name + "."); 9 smnFunctions.Add("de", name => "Mein Name ist " + name + "."); 10 smnFunctions.Add("en", name => "My name is " + name + "."); 11 } 12 13 public static Func<string, string> GetSayMyName(string language) 14 { 15 //Check if the language is available has been omitted on purpose 16 return smnFunctions[language]; 17 } 18 } 19 20 // Now it is sufficient to call Translations.GetSayMyName("de") 21 // to get the function with the German translation.
尽管这看起来有点过度设计之嫌,但毕竟这种方式很容易扩展,并且可以应用到很多场景下。如果结合反射一起使用,可以使程序变得更灵活,易于维护,并且更健壮。下面展示了这个模式如何工作:
自定义函数 (Self-Defining Functions)
在 JavaScript 中,自定义函数是一种极其常见的设计技巧,并且在某些代码中可以获得更好的性能。这个模式的主要思想就是,将一个函数作为一个属性,而此属性可以被其他函数很容易的更改。
1 class SomeClass 2 { 3 public Func<int> NextPrime 4 { 5 get; 6 private set; 7 } 8 9 int prime; 10 11 public SomeClass() 12 { 13 NextPrime = () => 14 { 15 prime = 2; 16 17 NextPrime = () => 18 { 19 //Algorithm to determine next - starting at prime 20 //Set prime 21 return prime; 22 }; 23 24 return prime; 25 }; 26 } 27 }
在这里做了什么呢?首先我们得到了第一个质数,值为 2。这不是重点,重点在于我们可以调整算法来排除所有偶数。这在一定程度上会加快我们的算法,但我们仍然设置 2 为质数的起点。我们无需看到是否已经调用了 NextPrime() 函数,因为根据函数内的定义会直接返回 2。通过这种方式,我们节省了资源,并且能够优化算法。
同样,我们也看到了这么做可以性能会更好。让我们来看下下面这个例子:
1 Action<int> loopBody = i => { 2 if(i == 1000) 3 loopBody = /* set to the body for the rest of the operations */; 4 5 /* body for the first 1000 iterations */ 6 }; 7 8 for(int j = 0; j < 10000000; j++) 9 loopBody(j);
这里我们有两个截然不同的区域,一个是前 1000 次迭代,另一个是剩下的 9999000 次迭代。通常我们需要一个条件来区分这两种情况。大部分情况下会引起不必要的开销,这也就是我们为什么要使用自定义函数在执行一小段代码后来改变其自身。
立即调用的函数表达式 (Immediately-Invoked Function Expression)
在 JavaScript 中,立即调用函数表达式(简写为 IIFE)是非常常见的用法。原因是 JavaScript 并没有使用类似 C# 中的大括号方式来组织变量的作用域,而是根据函数块来划分的。因此变量会污染全局对象,通常是 window 对象,这并不是我们期待的效果。
解决办法也很简单,尽管大括号并没有给定作用域,但函数给定了,因为在函数体内定义的变量的作用域均被限制在函数内部。而 JavaScript 的使用者通常认为如果那些函数只是为了直接执行,为其中的变量和语句指定名称然后再执行就变成了一种浪费。还有一个原因就是这些函数仅需要执行一次。
在 C# 中,我们可以简单编写如下的函数达到同样的功能。在这里我们同样也得到了一个全新的作用域,但这并不是我们的主要目的,因为如果需要的话,我们可以在任何地方创建新的作用域。
1 (() => { 2 // Do Something here! 3 })();
代码看起来很简单。如果我们需要传递一些参数,则需要指定参数的类型。
1 ((string s, int no) => { 2 // Do Something here! 3 })("Example", 8);
看起来写了这么多行代码并没有给我们带来什么好处。尽管如此,我们可以将这个模式和 async 关键字结合使用。
1 await (async (string s, int no) => { 2 // Do Something here async using Tasks! 3 })("Example", 8); 4 5 //Continue here after the task has been finished
这样,类似于异步包装器的用法就形成了。
对象即时初始化 (Immediate Object Initialization)
将这个模式包含在这篇文章当中的原因是,匿名对象这个功能太强大了,而且其不仅能包含简单的类型,而且还能包含 Lambda 表达式。
1 //Create anonymous object 2 var person = new 3 { 4 Name = "Florian", 5 Age = 28, 6 Ask = (string question) => 7 { 8 Console.WriteLine("The answer to `" + question + "` is certainly 42!"); 9 } 10 }; 11 12 //Execute function 13 person.Ask("Why are you doing this?");
如果你运行了上面这段代码,可能你会看到一个异常(至少我看到了)。原因是,Lambda 表达式不能被直接赋予匿名对象。如果你觉得不可思议,那我们的感觉就一样了。幸运的是,编译器告诉了我们“老兄,我不知道我应该为这个 Lambda 表达式创建什么样的委托类型”。既然这样,我们就帮下编译器。
1 var person = new 2 { 3 Name = "Florian", 4 Age = 28, 5 Ask = (Action<string>)((string question) => 6 { 7 Console.WriteLine("The answer to `" + question + "` is certainly 42!"); 8 }) 9 };
一个问题就出现了:这里的函数(Ask 方法)的作用域是什么?答案是,它就存活在创建这个匿名对象的类中,或者如果它使用了被捕获变量则存在于其自己的作用域中。所以,编译器仍然创建了一个匿名对象,然后将指向所创建的 Lambda 表达式的委托对象赋值给属性 Ask。
注意:当我们想在匿名对象中直接设定的 Lambda 表达式中访问匿名对象的任一属性时,则尽量避免使用这个模式。原因是:C# 编译器要求每个对象在被使用前需要先被声明。在这种情况下,使用肯定在声明之后,但是编译器是怎么知道的?从编译器的角度来看,在这种情况下声明与使用是同时发生的,因此变量 person 还没有被声明。
有一个办法可以帮助我们解决这个问题(实际上办法有很多,但依我的观点,这种方式是最优雅的)。
1 dynamic person = null; 2 person = new 3 { 4 Name = "Florian", 5 Age = 28, 6 Ask = (Action<string>)((string question) => 7 { 8 Console.WriteLine("The answer to `" + question + "` is certainly 42! My age is " + person.Age + "."); 9 }) 10 }; 11 12 //Execute function 13 person.Ask("Why are you doing this?");
看,现在我们先声明了它。当然我们也可以直接将 person 声明为 object 类型,但通过这种方式我们可以使用反射来访问匿名对象中的属性。此处我们依托于 DLR (Dynamic Language Runtime)来实现,这应该是最好的包装方式了。现在,这代码看起来很有 JavaScript 范儿了,但实际上我不知道这东西到底有什么用。
初始化时间分支(Init-Time Branching)
这个模式与自定义函数模式密切相关。唯一的不同就是,函数不再定义其自身,而是通过其他函数定义。当然,其他函数也可能没有通过传统的方式去定义,而是通过覆盖属性。
这个模式通常也称为加载时分支(Load-Time Branching),本质上是一种优化模式。该模式被用于避免恒定的 switch-case 和 if-else 等控制结构的使用。所以在某种程度上可以说,这种模式为某些恒定代码分支之间建立了联系。
1 public Action AutoSave { get; private set; } 2 3 public void ReadSettings(Settings settings) 4 { 5 /* Read some settings of the user */ 6 7 if (settings.EnableAutoSave) 8 AutoSave = () => { /* Perform Auto Save */ }; 9 else 10 AutoSave = () => { }; //Just do nothing! 11 }
这里我们做了两件事。首先,我们有一个方法读取了用户设置信息。如果我们发现用于已经打开了自动保存功能,则我们将保存代码赋予该属性。否则我们仅是指定一个空方法。然后,我们就可以一直调用 AutoSave 属性在执行操作。而且在此之后我们不再需要检查用户设置信息了。我们也不需要将这个特定的设置保存到一个 boolean 变量中,因为响应的函数已经被动态的设定了。
你可能说这并没有太大的性能改善,但这只是一个简单的例子。在一些复杂的代码中,这种方法确实可以节省很多时间,尤其是在大循环中调用那个动态设置的方法时。
同时,这样的代码可能更易于维护,并非常易读。在省去了很多不必要的控制过程之后,我们能够直达重点:调用 AutoSave 函数。
在 JavaScript 中,这种模式常用于检测浏览器的功能集。浏览器功能的检测对于任何网站来说都是噩梦一样,而这个模式在实现中就显得非常有用。同样 jQuery 也使用了同样的模式来检测正确的对象,以便使用 AJAX 功能。一旦它识别出浏览器支持 XMLHttpRequest ,则因为浏览器不会在脚本执行期间变化,所以无需在考虑处理 ActiveX 对象了。
延迟加载 (Lazy Loading)
我们想要创建一个对象,它能够执行某种延迟加载操作。也就是说,尽管对象已经被正确地初始化了,但我们并没有加载所有需要的资源。一个原因是想避免在获取需要的数据时引发的大量的 IO 操作。同时,我们也想在准备使用数据时,数据尽可能是最新的。有多种方式可以实现这个功能,而在 Entity Framework 中使用了效率极高的 LINQ 来解决延迟加载的情况。其中,IQueryable<T> 仅存储了查询而没有存储基础的数据。一旦我们需要这些数据,不仅已构造的查询会被执行,而且查询也是以最高效的形式来执行,例如在远端数据库服务器上执行 SQL 查询语句。
在我们想要的场景中,我们需要区别两种状况。首先我们进行查询,然后后续的操作将在已经获取到的结果上进行。
1 class LazyLoad 2 { 3 public LazyLoad() 4 { 5 Search = query => 6 { 7 var source = Database.SearchQuery(query); 8 9 Search = subquery => 10 { 11 var filtered = source.Filter(subquery); 12 13 foreach (var result in filtered) 14 yield return result; 15 }; 16 17 foreach (var result in source) 18 yield return result; 19 }; 20 } 21 22 public Func<string, IEnumerable<ResultObject>> Search { get; private set; } 23 }
那么,在这里基本上我们需要设置两个不同的方法。一个是从数据库拉数据,另一个是从已获取到的数据中进行过滤。当然你可能会想我们也可以在类中创建另一个方法来设置这些行为或者使用其他方式可能更有效。
属性多态模式 (Lambda Property Polymorphism Pattern)
Lambda表达式可以被用于实现多态(override),而不需要使用 abstract 和 virtual 等关键字。
1 class MyBaseClass 2 { 3 public Action SomeAction { get; protected set; } 4 5 public MyBaseClass() 6 { 7 SomeAction = () => 8 { 9 //Do something! 10 }; 11 } 12 }
这里没什么特别的。我们创建了一个类,通过一个属性来暴露一个函数。这有点像 JavaScript 风格。有趣的地方不仅在于可以在这个类中控制和更改这个函数属性,而且可以在它的衍生类中更改。
1 class MyInheritedClass : MyBaseClass 2 { 3 public MyInheritedClass 4 { 5 SomeAction = () => { 6 //Do something different! 7 }; 8 } 9 }
看!实际上这里我们能够更改这个属性完全是依赖于 protected 的应用。这种方式的缺点是我们无法直接访问父类的实现。这里我们丢失了 base 的强大能力,因为 base 中的属性具有相同的值。如果你确实还需要这样的功能,我建议使用下面这种“模式”:
1 class MyBaseClass 2 { 3 public Action SomeAction { get; private set; } 4 5 Stack<Action> previousActions; 6 7 protected void AddSomeAction(Action newMethod) 8 { 9 previousActions.Push(SomeAction); 10 SomeAction = newMethod; 11 } 12 13 protected void RemoveSomeAction() 14 { 15 if (previousActions.Count == 0) 16 return; 17 18 SomeAction = previousActions.Pop(); 19 } 20 21 public MyBaseClass() 22 { 23 previousActions = new Stack<Action>(); 24 25 SomeAction = () => 26 { 27 //Do something! 28 }; 29 } 30 }
这样,在子类中只能调用 AddSomeAction() 来覆写当前已设置的方法。这个方法将被直接放入一个栈内,这使我们能够记录之前的状态。
我给这个模式起的名字是 Lambda属性多态模式(Lambda Property Polymorphism Pattern)。它主要描述将函数封装为属性的可能性,然后能够在衍生类中覆写父类的属性。上面代码中的栈只是一个额外的功能,并不会改变这个模式的目标。
为什么需要这个模式?坦白的说,有多种原因。首先就是因为我们能这么做。但要注意,实际上如果我们要使用多个不同的属性时,这个模式会变得更灵活。“多态”这个词也就有了全新的含义,但那就是另一个模式了。所以这里我主要是想强调这个模式可以实现一些以前曾认为不可能的功能。
例如:你想覆写一个静态方法(不推荐这么做,但或许这么做是能解决你的问题的最优雅的方法)。那么,继承是不可能改变静态方法的。原因很简单:继承仅应用于类的实例,而静态方法却没有被绑定到类的实例上。静态方法对所有的类的实例都是相同的。这里也蕴含着一个警告,下面的这个模式可能不没有达到你想要的结果,所以一定要明确你为什么要这么用。
1 void Main() 2 { 3 var mother = HotDaughter.Activator().Message; 4 //mother = "I am the mother" 5 var create = new HotDaughter(); 6 var daughter = HotDaughter.Activator().Message; 7 //daughter = "I am the daughter" 8 } 9 10 class CoolMother 11 { 12 public static Func<CoolMother> Activator { get; protected set; } 13 14 //We are only doing this to avoid NULL references! 15 static CoolMother() 16 { 17 Activator = () => new CoolMother(); 18 } 19 20 public CoolMother() 21 { 22 //Message of every mother 23 Message = "I am the mother"; 24 } 25 26 public string Message { get; protected set; } 27 } 28 29 class HotDaughter : CoolMother 30 { 31 public HotDaughter() 32 { 33 //Once this constructor has been "touched" we set the Activator ... 34 Activator = () => new HotDaughter(); 35 //Message of every daughter 36 Message = "I am the daughter"; 37 } 38 }
这是一个极其简单的示例,并且希望不要引起误导。如果这么用可能会导致事情变的更复杂,所以我一直说为什么我们需要避免这么用,只是描述了其可行性。关于静态多态的较好的方案总不是易于实现的,并且需要很多的代码,所以除非它真能帮你解决实际的问题,而不是让你更头痛。
函数字典模式 (Function Dictionary Pattern)
之前我已经介绍了这个模式,只是还没有指定名字,它就是函数字典模式(Function Dictionary Pattern)。这个模式的基本成分包括:一个哈希表或字典用于包含一些键值对,键可能是任意类型,值是某些类型的函数。这个模式也指定了一个特殊的字典构造方式。这在这个模式中是必须的,否则只能使用 switch-case 来达到相同的目的了。
1 public Action GetFinalizer(string input) 2 { 3 switch 4 { 5 case "random": 6 return () => { /* ... */ }; 7 case "dynamic": 8 return () => { /* ... */ }; 9 default: 10 return () => { /* ... */ }; 11 } 12 }
上面代码中我们需要一个字典类型吗?当然。我们可以这么做:
1 Dictionary<string, Action> finalizers; 2 3 public void BuildFinalizers() 4 { 5 finalizers = new Dictionary<string, Action>(); 6 finalizers.Add("random", () => { /* ... */ }); 7 finalizers.Add("dynamic", () => { /* ... */ }); 8 } 9 10 public Action GetFinalizer(string input) 11 { 12 if(finalizers.ContainsKey(input)) 13 return finalizers[input]; 14 15 return () => { /* ... */ }; 16 }
但要注意,在这里使用这个模式并没有带来任何好处。实际上,这个模式的效率更低,并且需要更多格外的代码。但是我们能做的事情是,通过反射来是函数字典的构造过程自动化。同样还是没有使用 switch-case 语句的效率高,但代码更健壮,可维护性更高。实际上这个操作也很方便,比如我们有大量的代码,我们甚至不知道在哪个方法内加入 switch-case 代码块。
我们来看一个可能的实现。通常我会建议在代码中增加一些约定,以便能够得到字典的键。当然,我们也可以通过选择类中某个属性的名称,或者直接使用方法的名称来满足需求。在下面的示例中,我们仅选择一种约定:
1 static Dictionary<string, Action> finalizers; 2 3 //The method should be called by a static constructor or something similar 4 //The only requirement is that we built 5 public static void BuildFinalizers() 6 { 7 finalizers = new Dictionary<string, Action>(); 8 9 //Get all types of the current (= where the code is contained) assembly 10 var types = Assembly.GetExecutingAssembly().GetTypes(); 11 12 foreach (var type in types) 13 { 14 //We check if the class is of a certain type 15 if (type.IsSubclassOf(typeof(MyMotherClass))) 16 { 17 //Get the constructor 18 var m = type.GetConstructor(Type.EmptyTypes); 19 20 //If there is an empty constructor invoke it 21 if (m != null) 22 { 23 var instance = m.Invoke(null) as MyMotherClass; 24 //Apply the convention to get the name - in this case just we pretend it is as simple as 25 var name = type.Name.Remove("Mother"); 26 //Name could be different, but let's just pretend the method is named MyMethod 27 var method = instance.MyMethod; 28 29 finalizers.Add(name, method); 30 } 31 } 32 } 33 } 34 35 public Action GetFinalizer(string input) 36 { 37 if (finalizers.ContainsKey(input)) 38 return finalizers[input]; 39 40 return () => { /* ... */ }; 41 }
现在这段代码是不是更好些呢。事实上,这个模式可以节省很多工作。而其中最好的就是:它允许你实现类似插件的模式,并且使此功能跨程序集应用。为什么这么说呢?比如我们可以扫描指定模式的类库,并将其加入到代码中。通过这种方式也可以将其他类库中的功能添加到当前代码中。
1 //The start is the same 2 3 internal static void BuildInitialFinalizers() 4 { 5 finalizers = new Dictionary<string, Action>(); 6 LoadPlugin(Assembly.GetExecutingAssembly()); 7 } 8 9 public static void LoadPlugin(Assembly assembly) 10 { 11 //This line has changed 12 var types = assembly.GetTypes(); 13 14 //The rest is identical! Perfectly refactored and obtained a new useful method 15 foreach (var type in types) 16 { 17 if (type.IsSubclassOf(typeof(MyMotherClass))) 18 { 19 var m = type.GetConstructor(Type.EmptyTypes); 20 21 if (m != null) 22 { 23 var instance = m.Invoke(null) as MyMotherClass; 24 var name = type.Name.Remove("Mother"); 25 var method = instance.MyMethod; 26 finalizers.Add(name, method); 27 } 28 } 29 } 30 } 31 32 //The call is the same
现在我们仅需要通过一个点来指定插件。最后将会从某路径中读取类库,尝试创建程序集对象,然后调用 LoadPlugin() 来加载程序集。
函数式特性 (Functional Attribute Pattern)
Attribute 是 C# 语言中最棒的功能之一。借助 Attribute,曾在 C/C++ 中不太容易实现的功能,在C#中仅需少量的代码即可实现。 这个模式将 Attribute 与 Lambda 表达式结合到一起。在最后,函数式特性模式(Functional Attribute Pattern)将会提高 Attribute 应用的可能性和生产力。
可以说,将 Lambda 表达式和 Attribute 结合到也一起相当的有帮助,因为我们不再需要编写特定的类。让我们来看个例子来具体解释是什么意思。
1 class MyClass 2 { 3 public bool MyProperty 4 { 5 get; 6 set; 7 } 8 }
现在针对这个类的实例,我们想要能够根据一些领域特性语言或脚本语言来改变这个属性。然后我们还想能够在不写任何额外代码的条件下来改变属性的值。当然,我们还是需要一些反射机制。同时也需要一些 attribute 来指定是否这个属性值能够被用户更改。
1 class MyClass 2 { 3 [NumberToBooleanConverter] 4 [StringToBooleanConverter] 5 public bool MyProperty 6 { 7 get; 8 set; 9 } 10 }
我们定义两种转换器。虽然使用一个即可标示这个属性可以被任何用于更改。我们使用两个来为使用者提供更多的可能性。在这个场景下,一个使用者可能实际上使用一个字符串来设置这个值(将字符串转换成布尔值)或者用一个数字(比如0或1)。
那么这些转换器如何实现呢?我们来看下 StringToBooleanConverterAttribute 的实现。
1 public class StringToBooleanConverterAttribute : ValueConverterAttribute 2 { 3 public StringToBooleanConverterAttribute() 4 : base(typeof(string), v => { 5 var str = (v as string ?? string.Empty).ToLower(); 6 7 if (str == "on") 8 return true; 9 else if (str == "off") 10 return false; 11 12 throw new Exception("The only valid input arguments are [ on, off ]. You entered " + str + "."); 13 }) 14 { 15 /* Nothing here on purpose */ 16 } 17 } 18 19 public abstract class ValueConverterAttribute : Attribute 20 { 21 public ValueConverterAttribute(Type expected, Func<object, object> converter) 22 { 23 Converter = converter; 24 Expected = expected; 25 } 26 27 public ValueConverterAttribute(Type expected) 28 { 29 Expected = expected; 30 } 31 32 public Func<Value, object> Converter { get; set; } 33 34 public object Convert(object argument) 35 { 36 return Converter.Invoke(argument); 37 } 38 39 public bool CanConvertFrom(object argument) 40 { 41 return Expected.IsInstanceOfType(argument); 42 } 43 44 public Type Expected 45 { 46 get; 47 set; 48 } 49 50 public string Type 51 { 52 get { return Expected.Name; } 53 } 54 }
使用这个模式我们得到了什么好处呢?如果 Attribute 能够接受非常量表达式作为参数(比如委托、Lambda 表达式等都有可能),则我们得到的好处会更多。通过这种方式,我们仅需使用 Lambda 表达式来替换抽象方法,然后将其传递给父类的构造函数。
你可能有些意见,这和 abstract 函数比并没什么新鲜的,但有趣的地方在于不能像使用函数一样来用,而是作为一个属性能够被外部进行设置。这可以被用于一些动态代码中,来重写一些转换器,尽管其已经被实例化了。
避免循环引用 (Avoiding cyclic references)
在 C#中,循环引用并不是一个大问题。实际上仅在一种方式下会使循环引用带来问题,那就是在 struct 结构体中。因为类是引用类型,循环引用并没有什么坏处。在源对象上持有目标对象的一个引用指针,而在目标对象上持有一个源对象的引用指针,这不会有任何问题。
但是如果是结构体,我们没法使用指针,其在栈上创建对象。因为在这种情况下,若源对象包含一个目标对象,实际上是包含了一个目标对象的拷贝,而不是真正的目标对象,而反过来也一样。
大部分情况下,编译器会检测到这种循环引用,然后抛出一个编译错误,这个功能其实很棒。我们来看个能引起错误的例子:
1 struct FirstStruct 2 { 3 public SecondStruct Target; 4 } 5 6 struct SecondStruct 7 { 8 public FirstStruct Source; 9 }
这上面的代码中,使用结构体变量。这与类有巨大的不同:尽管我们没初始化变量,但变量其实已经被初始化为默认值。
所以说,编程是件复杂的事,编译器也不是万能的神。通过一些方式可以骗过编译器。如果我们欺骗了编译器,编译器就会告诉我们一个运行时错误,无法创建这个对象。一种欺骗方式是使用自动属性:
1 struct FirstStruct 2 { 3 public SecondStruct Target { get; set; } 4 } 5 6 struct SecondStruct 7 { 8 public FirstStruct Source { get; set; } 9 }
这不会阻止问题的发生,其只是将问题从编译时错误延迟到了运行时错误。我们脑中立即会产生一个方案,就是使用可空结构(nullable struct)。
1 struct FirstStruct 2 { 3 public SecondStruct? Target { get; set; } 4 } 5 6 struct SecondStruct 7 { 8 public FirstStruct Source { get; set; } 9 }
这里的问题是,那些可空结构也同样是结构体,他们继承自 System.Nullable<T> ,实际上也是一个结构体类型。
终于,Lambda表达式来拯救我们了。
1 struct FirstStruct 2 { 3 readonly Func<SecondStruct> f; 4 5 public FirstStruct(SecondStruct target) 6 { 7 f = () => target; 8 } 9 10 public SecondStruct Target 11 { 12 get 13 { 14 return f(); 15 } 16 } 17 } 18 19 struct SecondStruct 20 { 21 public FirstStruct Source { get; set; } 22 }
这里我们做了什么呢?我们使用了一个对函数的引用,而该函数会返回给我们结构体。编译器会生成一个类来包含这个结构体,这样这个结构体就作为一个全局变量存在了。因为结构体总是会包含一个默认的构造函数,会保持 f 的未引用状态,我们加了另一个构造函数,并且将目标结构体作为参数传入。
最后,我们创建了一个闭包,在其中返回被捕获的结构体实例。重点的强调下,可能会有其他可能性。如果使用一个引用类型作为值类型的容器,可能循环引用的情况更糟。Lambda 表达式只是能完成这个功能的一种方式,但在某些条件下,其是能处理这种场景的最具表达性和最直接的方式。
完整代码


1 class TestPatterns 2 { 3 public static void SelfDefining() 4 { 5 Console.WriteLine(":: Pattern: Self-definining function"); 6 7 Action foo = () => 8 { 9 Console.WriteLine("Hi there!"); 10 11 foo = () => 12 { 13 Console.WriteLine("Hi again!"); 14 }; 15 }; 16 17 Console.WriteLine("First call (initilization)."); 18 foo(); 19 Console.WriteLine("Second call - use different one now!"); 20 foo(); 21 Console.WriteLine("Third call - still the same."); 22 foo(); 23 } 24 25 public static void Callback() 26 { 27 Console.WriteLine(":: Pattern: Callback pattern"); 28 Console.WriteLine("Calling the function with lambda expression."); 29 30 CallMe(() => "The boss."); 31 32 Console.WriteLine("Back at the starting point."); 33 } 34 35 static void CallMe(Func<string> caller) 36 { 37 Console.WriteLine("Received function as parameter - Who called?!"); 38 Console.WriteLine(caller()); 39 } 40 41 public static void Returning() 42 { 43 Console.WriteLine(":: Pattern: Returning function"); 44 Console.WriteLine("Calling to obtain the method ..."); 45 Func<double, double> method = GetProperMethod("sin"); 46 Console.WriteLine("Doing something with the method ..."); 47 Console.WriteLine("f(pi / 4) = {0}", method(Math.PI / 4)); 48 } 49 50 static Func<double, double> GetProperMethod(string what) 51 { 52 switch (what) 53 { 54 case "sin": 55 return Math.Sin; 56 57 case "cos": 58 return Math.Cos; 59 60 case "exp": 61 return Math.Exp; 62 63 default: 64 return x => x; 65 } 66 } 67 68 public static void IIFE() 69 { 70 Console.WriteLine(":: Pattern: IIFE"); 71 72 ((Action<double>)((x) => 73 { 74 Console.WriteLine(2.0 * x * x - 0.5 * x); 75 }))(1.0); 76 77 78 ((Action<double, double>)((x, y) => 79 { 80 Console.WriteLine(2.0 * x * y - 1.5 * x); 81 }))(2.0, 3.0); 82 } 83 84 public static void ImmediateObject() 85 { 86 Console.WriteLine(":: Pattern: Immediate object initialization"); 87 88 var terminator = new 89 { 90 Typ = "T1000", 91 Health = 100, 92 Hit = (Func<double, double>)((x) => 93 { 94 return 100.0 * Math.Exp(-x); 95 }) 96 }; 97 98 Console.WriteLine("Terminator with type {0} has been created.", terminator.Typ); 99 Console.WriteLine("Let's hit the terminator with 0.5. Rest health would be {0}!", terminator.Hit(0.5)); 100 } 101 102 public static void InitTimeBranching() 103 { 104 Console.WriteLine(":: Pattern: Init-time branching"); 105 Action<int> loopBody = null; 106 Console.WriteLine("Select a proper loop body method ..."); 107 Random r = new Random(); 108 int sum = 0; 109 110 if (r.NextDouble() < 0.5) 111 { 112 Console.WriteLine("Selected random choice ..."); 113 114 loopBody = index => 115 { 116 sum += r.Next(0, 10000); 117 }; 118 } 119 else 120 { 121 Console.WriteLine("Selected little gauss ..."); 122 123 loopBody = index => 124 { 125 sum += index; 126 }; 127 } 128 129 Console.WriteLine("Execute the loop ..."); 130 131 for (var i = 0; i < 10000; i++) 132 loopBody(i); 133 134 Console.WriteLine("Loop has finished with result sum = {0}.", sum); 135 } 136 }
文章内容翻译并改编自 Way to Lambda ,章节和代码有很大的改动,未包含全部内容。
