SQLSERVER中的ALL、PERCENT、CUBE关键字、ROLLUP关键字和GROUPING函数
先来创建一个测试表
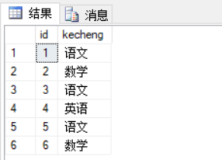
1 USE [tempdb] 2 GO 3 4 CREATE TABLE #temptb(id INT ,NAME VARCHAR(200)) 5 GO 6 7 INSERT INTO [#temptb] ( [id], [NAME] ) 8 SELECT 1,'中国' UNION ALL 9 SELECT 2,'中国' UNION ALL 10 SELECT 3,'英国' UNION ALL 11 SELECT 4,'英国' UNION ALL 12 SELECT 5,'美国' UNION ALL 13 SELECT 6,'美国' UNION ALL 14 SELECT null, '法国' UNION ALL 15 SELECT 8,'法国' 16 GO 17 18 SELECT * FROM [#temptb] 19 GO
先来看一下SELECT语句的语法:
1 SELECT [ ALL | DISTINCT ] [ topSubclause ] aliasedExpr 2 [{ , aliasedExpr }] FROM fromClause [ WHERE whereClause ] [ GROUP BY groupByClause [ HAVING havingClause ] ] [ ORDER BY orderByClause ] 3 or 4 SELECT VALUE [ ALL | DISTINCT ] [ topSubclause ] expr FROM fromClause [ WHERE whereClause ] [ GROUP BY groupByClause [ HAVING havingClause ] ] [ ORDER BY orderByClause
ALL关键字:指定在结果集中可以显示重复的行,这是默认的关键字,也就是说,当您在查询中不使用ALL关键字,默认都已经附加上了ALL这个关键字
例如下面两个SQL语句,实际上是等价的,都会把重复的记录select出来
1 --这两个语句是等价的 2 SELECT * FROM [#temptb] 3 GO 4 ------------------------------------------- 5 SELECT ALL * FROM [#temptb] 6 GO
如果您需要把唯一值select出来,过滤掉那些重复值需要使用DISTINCT关键字
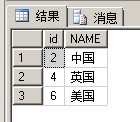
1 SELECT DISTINCT([NAME]) FROM [#temptb]
而当您把SQL语句,字段放在ALL括号中,这时候就会变成一个表达式,例如下面SQL语句
1 SELECT ALL([NAME]+'您好') AS '国别' FROM [#temptb]

在我上一篇文章里:处理表重复记录(查询和删除)
在Name相同ID最大的记录,其中有一个SQL语句
1 SELECT * 2 FROM [#temptb] a 3 WHERE ID!<ALL ( SELECT ID 4 FROM [#temptb] 5 WHERE Name = a.Name )
如果去掉ALL关键字会怎样呢?

因为子查询需要的是一个表达式,所以需要使用ALL关键字把他变为一个表达式,所以要用ALL
ALL关键字还可以放在GROUP BY 之后
这里要分两种情况,一种是SQL语句中有where子句的的,另一种是SQL语句中没有where子句的
情况一:
1 SELECT AVG(id) FROM [#temptb] WHERE NAME='法国' GROUP BY ALL NAME 2 SELECT AVG(id) FROM [#temptb] WHERE NAME='法国' GROUP BY NAME
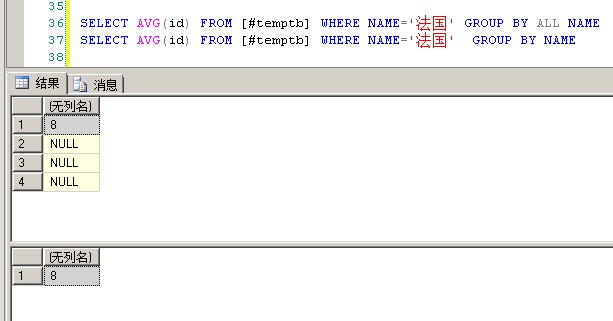
对于没有符合条件的行的组,这里是没有符合name='法国',作为聚合值的列值为NULL
如果没有ALL关键字,GROUP BY子句将不显示没有符合条件的行的组
情况二:
1 SELECT AVG(id) FROM [#temptb] GROUP BY ALL NAME 2 SELECT AVG(id) FROM [#temptb] GROUP BY NAME
当SQL语句中没有where子句的时候,查询出来的结果都是一样的
ALL关键字还可以放在UNION之后
1 USE [GPOSDB] 2 GO 3 INSERT INTO [dbo].[SystemPara] ( [ParaValue], [Name], [Description] ) 4 SELECT 'nihao','nihao','nihao' UNION ALL 5 SELECT 'nihao','nihao','nihao'
PERCENT关键字
PERCENT关键字需要跟TOP 关键字一起使用
从结果集中输出百分之N行,n必须是介于0~100之间的整数
1 SELECT TOP 10 PERCENT * from [#temptb] 2 GO
上面的SQL语句意思是:从[#temptb]表中输出10%的记录数,因为没有使用order by子句,所以这条记录是随机的
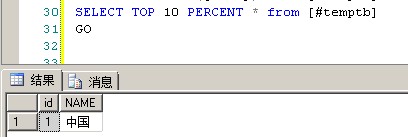
因为[#temptb]表有8条记录,8*10%=0.8 四舍五入之后相当于一条记录
1 SELECT TOP 30 PERCENT * from [#temptb] 2 GO
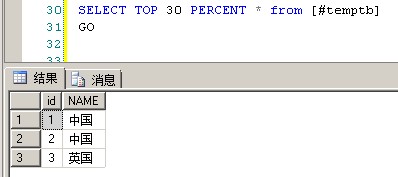
8*30%=2.4 四舍五入之后相当于三条记录,SQLSERVER在这里就算四舍五入不足三条记录,他也会输出偏大的数,也就是三条记录
CUBE关键字
CUBE关键字:如果需要在结果集内不仅包含由GROUP BY提供的正常行,还包含汇总行,可以用CUBE关键字。CUBE关键字与GROUP BY一起使用
当使用CUBE关键字的时候,可以使用GROUPING函数来输出一个额外的列,当结果行是正常的行时,返回0;当结果行是汇总行时,返回1。
1 SELECT AVG(id) AS '平均值', GROUPING(NAME) AS '是否已汇总' 2 FROM [#temptb] 3 GROUP BY NAME 4 WITH CUBE
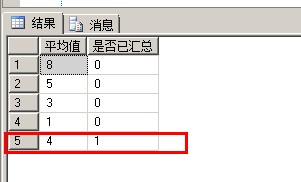
最后一行显示了GROUP BY的记录有多少行,一共有4行记录,而在汇总行(即最后一行)是否已汇总那列显示1,表示是汇总行
Grouping关键字
指示是否聚合 GROUP BY 列表中的指定列表达式。
在结果集中,如果 GROUPING 返回 1 则指示聚合;返回 0 则指示不聚合。
如果指定了 GROUP BY,则 GROUPING 只能用在 SELECT <select> 列表、HAVING 和 ORDER BY 子句中。
http://msdn.microsoft.com/zh-cn/library/ms178544(v=sql.105).aspx
GROUPING 用于区分标准空值和由 ROLLUP、CUBE 或 GROUPING SETS 返回的空值。
作为 ROLLUP、CUBE 或 GROUPING SETS 操作结果返回的 NULL 是 NULL 的特殊应用。
它在结果集内作为列的占位符,表示全体。
以下示例将分组 SalesQuota 并聚合 SaleYTD 数量。GROUPING 函数应用于 SalesQuota 列。
1 USE [AdventureWorks]; 2 GO 3 SELECT SalesQuota, SUM(SalesYTD) 'TotalSalesYTD', 4 GROUPING(SalesQuota) AS 'Grouping' 5 FROM Sales.SalesPerson 6 GROUP BY SalesQuota 7 WITH ROLLUP; 8 GO
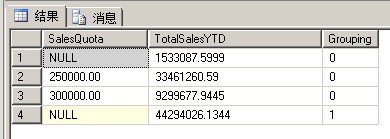
结果集在 SalesQuota 下面显示两个空值。
第一个 NULL 代表从表中的这一列得到的空值组。
第二个 NULL 位于 ROLLUP 操作所添加的汇总行之中。
汇总行显示所有 SalesQuota 组的 TotalSalesYTD 数量,并以 Grouping 列中的 1 进行指示。
http://msdn.microsoft.com/zh-cn/library/ms191500(v=sql.100).aspx
对简单汇总报表使用 Transact-SQL
生成简单汇总报表的应用程序可使用下列 Transact-SQL 元素:
ROLLUP、CUBE 或 GROUPING SETS 运算符。这些是 SELECT 语句的 GROUP BY 子句的扩展。
COMPUTE 或 COMPUTE BY 运算符。这两种运算符也与 GROUP BY 相关联。
这些运算符生成的结果集中,既包含每个项目的明细行,也包含每个组的汇总行,汇总行显示了该组的聚合合计。
GROUP BY 子句可用于生成只包含各组的聚合而不包含其明细行的结果。
应用程序应使用 Analysis Services,而不是 CUBE、ROLLUP、COMPUTE 或 COMPUTE BY。
特别要注意的是,CUBE 和 ROLLUP 应当只用在无法访问 OLE DB 或 ADO 的环境中,例如脚本或存储过程中。
支持 COMPUTE 和 COMPUTE BY 是为了向后兼容。
应当优先选用 ROLLUP 运算符而非 COMPUTE 或 COMPUTE BY。由 COMPUTE 或 COMPUTE BY 生成的汇总值将作为多个单独的结果集返回,
这些结果集之间还插入了包含各组明细行的结果集;或者作为包含合计的结果集返回,附加在主结果集之后。
处理这些多个结果集将增加应用程序代码的复杂性。服务器游标既不支持 COMPUTE,也不支持 COMPUTE BY。
但 ROLLUP 支持服务器游标。CUBE 和 ROLLUP 将生成单个结果集,其中包含嵌入的小计和合计行。
此外,查询优化器有时还可以为 ROLLUP 生成比为 COMPUTE 和 COMPUTE BY 生成的执行计划更高效的执行计划。
如果使用不带这些运算符的 GROUP BY,将返回单个结果集,其中每组对应一行,行中包含该组的聚合小计。结果集中没有明细行。
SQLSERVER中Cube 、RollUp的用法
Cube 、RollUp可以对查询的数据进行汇总,在数据统计中经常用到,尤其是做报表时,用在Select语句中
下面就对两种统计方式进行对比
SQL脚本如下:
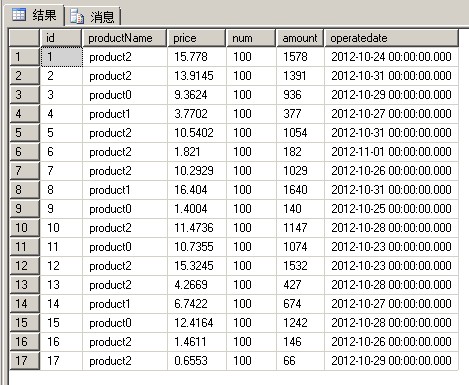
1 USE [tempdb] 2 GO 3 CREATE TABLE t_test 4 ( 5 id INT , 6 productName VARCHAR(200) , 7 price MONEY , 8 num INT , 9 amount INT , 10 operatedate DATETIME 11 ) 12 GO 13 14 --插入随机数据 15 DECLARE @i INT 16 DECLARE @rand MONEY 17 DECLARE @date DATETIME 18 DECLARE @index INT 19 DECLARE @DateBase INT 20 SET @date = '2012-10-23' 21 SET @i = 1 22 WHILE ( @i < 18 ) 23 BEGIN 24 SET @rand = RAND() * 20 25 SET @index = CAST(RAND() * 3 AS INT) 26 SET @DateBase = CAST(RAND() * 10 AS INT) 27 28 INSERT INTO t_test ( id, productName, price, num, amount, operatedate ) 29 VALUES ( @i, 'product' + CAST (@index AS VARCHAR(10)), @rand, 100, 30 @rand * 100, @date + @DateBase ) 31 SET @i = @i + 1 32 END 33 34 35 SELECT * FROM t_test
分别用两种方式统计:
1 --分别用两种方式统计: 2 3 SELECT CASE WHEN GROUPING(operatedate) = 1 THEN '小计' 4 ELSE CONVERT(VARCHAR(10), operatedate, 120) 5 END AS 日期, CASE WHEN GROUPING(productName) = 1 THEN '小计' 6 ELSE productName 7 END AS 产品名称, SUM(amount) / SUM(num) AS 平均价格, SUM(num) AS 数量, 8 SUM(amount) AS 金额 9 FROM t_test 10 GROUP BY operatedate, productName WITH ROLLUP; 11 ------------------------------------------------------------------- 12 SELECT CASE WHEN GROUPING(operatedate) = 1 THEN '小计' 13 ELSE CONVERT(VARCHAR(10), operatedate, 120) 14 END AS 日期, CASE WHEN GROUPING(productName) = 1 THEN '小计' 15 ELSE productName 16 END AS 产品名称, SUM(amount) / SUM(num) AS 平均价格, SUM(num) AS 数量, 17 SUM(amount) AS 金额 18 FROM t_test 19 GROUP BY operatedate, productName WITH CUBE;
ROLLUP 按照分组顺序,先对第一个字段operatedate分组,在组内进行统计,最后给出合计
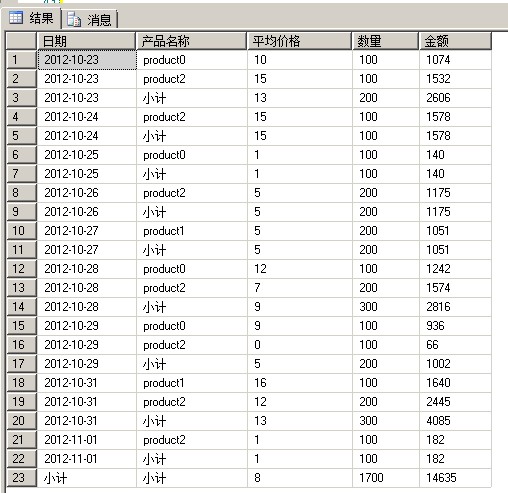
1 SELECT CASE WHEN GROUPING(operatedate) = 1 THEN '小计' --用GROUPING得出是否是汇总行,这个例子里最后一行是汇总行 2 ELSE CONVERT(VARCHAR(10), operatedate, 120) 3 END AS 日期, CASE WHEN GROUPING(productName) = 1 THEN '小计' 4 ELSE productName 5 END AS 产品名称, SUM(amount) / SUM(num) AS 平均价格, SUM(num) AS 数量, 6 SUM(amount) AS 金额 7 FROM t_test 8 GROUP BY operatedate, productName WITH ROLLUP; --因为operatedate和productName字段都在GROUPING函数里统计是否汇总,所以GROUP BY后面就需要加operatedate和productName这两个字段
CUBE 会对所有的分组字段进行统计,如上例,先对日期求小计,也就是统计每天的产品总金额,然后统计每个产品的总金额,最后给出总的合计。
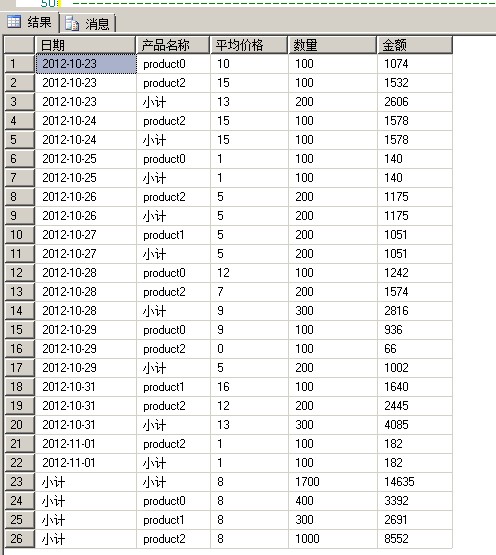
ROLLUP和CUBE的区别就是: ROLLUP 只会去统计group by 后面的第一个字段每个分组的小计和第一个字段的总计
Grouping(字段名) 用来区分当前行是不是小计产生的行, Grouping(字段名)=1 说明是统计行,Grouping(字段名)=0 说明是表中行
可以用在case,where 后面
http://www.2cto.com/database/201210/163455.html
另外一个例子
SQL脚本如下:


1 USE [tempdb] 2 GO 3 CREATE TABLE Sales (EmpId INT, Yr INT, Sales MONEY) 4 INSERT Sales VALUES(1, 2005, 12000) 5 INSERT Sales VALUES(1, 2006, 18000) 6 INSERT Sales VALUES(1, 2007, 25000) 7 INSERT Sales VALUES(2, 2005, 15000) 8 INSERT Sales VALUES(2, 2006, 6000) 9 INSERT Sales VALUES(3, 2006, 20000) 10 INSERT Sales VALUES(3, 2007, 24000) 11 12 SELECT * FROM [dbo].[Sales]
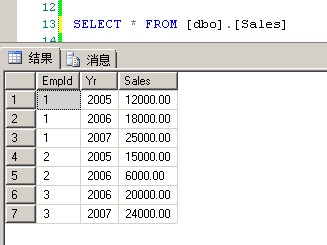
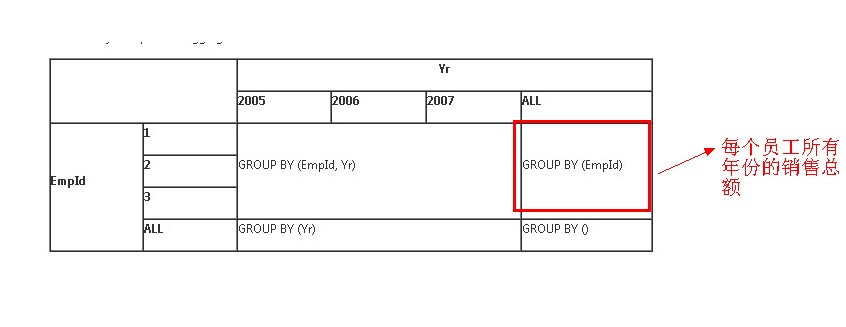
ROLLUP
1 SELECT EmpId, Yr, SUM(Sales) AS Sales 2 FROM Sales 3 GROUP BY EmpId, Yr WITH ROLLUP
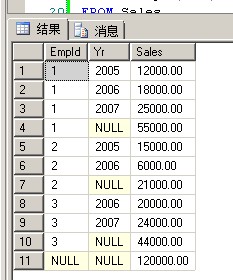
CUBE
1 SELECT EmpId, Yr, SUM(Sales) AS Sales 2 FROM Sales 3 GROUP BY EmpId, Yr WITH CUBE
CUBE比ROLLUP多了年份的统计,统计了2005、2006、2007年的销售额
可以用下图来表示

ROLLUP
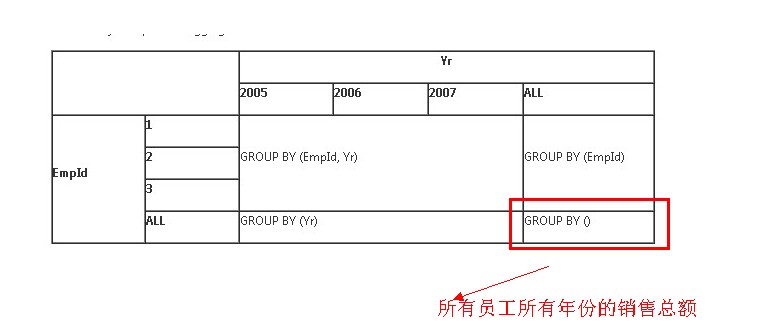
CUBE
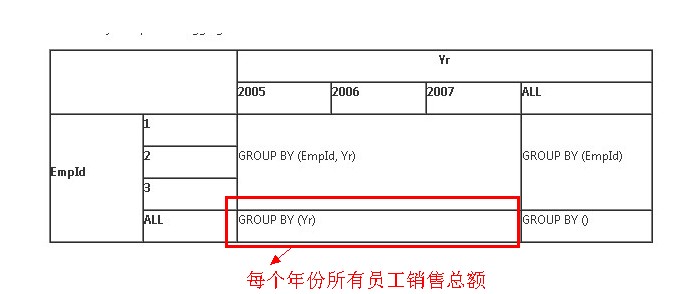
http://blogs.msdn.com/b/craigfr/archive/2007/10/11/grouping-sets-in-sql-server-2008.aspx
验证CUBE和ROLLUP 的区别
ROLLUP和CUBE的区别就是: ROLLUP 只会去统计group by 后面的第一个字段每个分组的小计和第一个字段的总计
我们修改一下上面那个实验
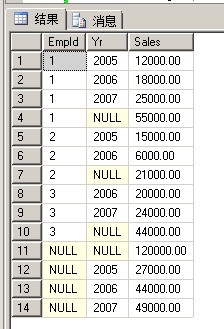
1 USE [tempdb] 2 GO 3 CREATE TABLE Sales (EmpId INT,productName VARCHAR(200), Yr INT, Sales MONEY) 4 GO 5 INSERT Sales VALUES(1,'product2', 2005, 12000) 6 INSERT Sales VALUES(1,'product1', 2005, 18000) 7 INSERT Sales VALUES(1,'product0', 2006, 25000) 8 INSERT Sales VALUES(1,'product2', 2007, 15000) 9 INSERT Sales VALUES(2,'product1', 2005, 60000) 10 INSERT Sales VALUES(2,'product1', 2006, 22000) 11 INSERT Sales VALUES(2,'product0', 2007, 24000) 12 INSERT Sales VALUES(3,'product0', 2005, 32000) 13 INSERT Sales VALUES(3,'product2', 2006, 42000) 14 INSERT Sales VALUES(3,'product0', 2007, 24000) 15 GO 16 17 SELECT * FROM [dbo].[Sales]
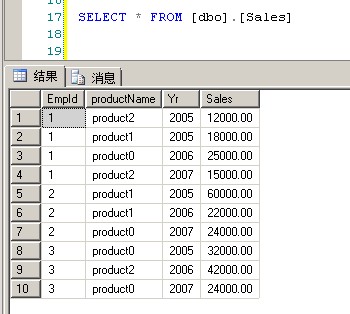
ROLLUP
1 SELECT EmpId, Yr,[productName], SUM(Sales) AS Sales 2 FROM Sales 3 GROUP BY EmpId, Yr,[productName] WITH ROLLUP
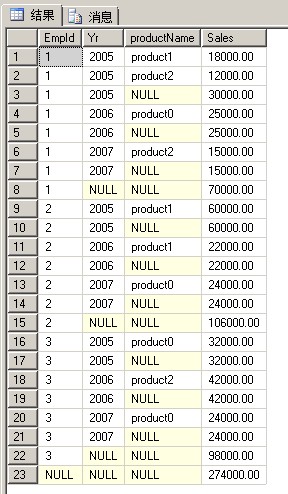
CUBE
1 SELECT EmpId, Yr,[productName], SUM(Sales) AS Sales 2 FROM Sales 3 GROUP BY EmpId, Yr,[productName] WITH CUBE
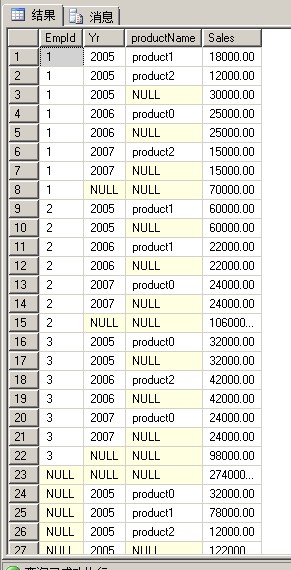
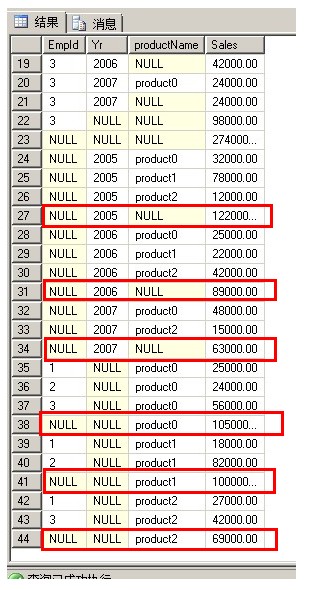
可以看到CUBE除了统计EmpId字段之外,还统计了GROUP BY后面的Yr和productName这两个字段
而ROLLUP只统计了EmpId这个字段
总结
这些关键字和函数对平时用于统计的应用程序都非常有用,如果大家对这些函数功能都很熟悉的话,在开发当中一定能够得心应手
另外,个人觉得PERCENT关键字可以应用在分页上
如有不对的地方,欢迎大家拍砖哦o(∩_∩)o