一. 数据读写流程简要
SQL Server作为一个关系型数据库,自然也维持了事务的ACID特性,数据库的读写冲突由事务隔离级别控制。无论有没有显示开启事务,事务都是存在的。流程图如下:
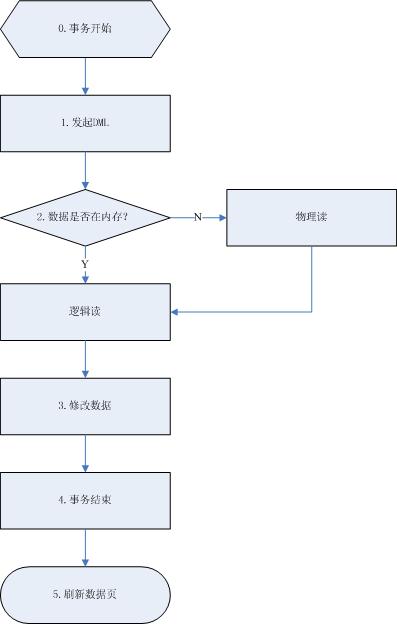
数据读写流程图
0. 事务开始
(1) 所有DML语句必然是基于事务的,如果没有显式开启事务,即手动写下BEGIN TRAN,SQL Server则把每条语句作为一个事务,并自动提交事务。
也就是说SQL SERVER 默认不开启隐式事务,这点与ORACLE正好相反,ORACLE默认开启了隐式事务,每条DML语句或者语句块,都要手动commit才会提交。
SQL Server里如要改变这个默认行为,可以在会话里做如下设置,如果没有打开隐式事务,SQL Server会自动提交当前的DML语句,而打开后,需要手动COMMIT才会提交。
--开启隐式事务 SET IMPLICIT_TRANSACTIONS ON --插入一条记录 CREATE TABLE TEST_TRAN(ID INT) INSERT INTO TEST_TRAN VALUES(1) --查看开启的事务 DBCC OPENTRAN()
(2) 如果手动开启了一个事务(BEGIN TRAN),则和开启隐式事务(SET IMPLICIT_TRANSACTIONS ON)一样,需要手动提交事务(COMMIT);
1. 发起DML
(1) DML通常指的是:INSERT、DELETE、UPDATE;
(2) DDL语句最终是被转化为对系统表的DML,在SQL SERVER中DDL语句也可以被回滚,比如:CREATE/ALTER/DROP/TRUNCATE,在ORACLE里是不可以的,另外SQL Server中的DCL语句:DENY,REVOKE,也可以被回滚;
2. 数据是否在内存
(1) 在内存中使用HASH算法查找数据,如果找到数据那么记为逻辑读;
(2) 如果数据页不在内存中,则需要从磁盘上的数据文件中,读取相应的数据页到内存中,即物理读,物理读也会被记数为逻辑读,也就是说无论内存中有没有数据,逻辑读是一定有的。
3. 修改数据
(1) 在SQL SERVER内存的数据缓冲区中将数据页修改,此时数据页称为脏页(DIRTY PAGE);
(2) 在SQL SERVER内存的日志缓冲区中记录REDO LOG,姑且称为脏日志;
4. 事务结束
(1) 提交(COMMIT),此时将当前事务的脏日志刷新到数据库的日志文件中,并打上事务结束标记(COMMIT),脏页有可能暂未被刷新到数据文件;
事务日志结构如下(可通过log explorer等类似工具查看):
BEGIN TRAN
DML
COMMIT TRAN
(2) 回滚(ROLLBACK),此时读REDO LOG得到反向DML操作,反向修改脏页,正向的DML+反向DML都会被记录在数据库的日志文件中,并打上事务结束标记(ROLLBACK),同样,脏页有可能暂未被刷新到数据文件;
事务日志结构如下:
BEGIN TRAN
DML
反向DML
ROLLBACK TRAN
不难发现,SQL SERVER的日志容易成为一个瓶颈(BOTTLENECK),因为在写的同时引入了读,即引入了竞争,而ORACLE用UNDO SEGMENT很好地避免了这个问题,REDO LOG永远只是在被串行写。
5. 刷新数据页
(1) SQL Server数据库遵循预写日志(WAL:Write-Ahead Logging)原则,因为关系型数据库是基于事务的,而日志正是事务ACID属性的保证,也是数据恢复的保证;
(2) 检查点(CHECKPOINT),检查点周期性地将脏页刷新到数据文件中,最终在日志文件打上检查点标记(CHECKPOINT),至此上面事务中修改的数据被正式写到磁盘上的数据文件中。
二. 数据读写流程深入
试想:
(1) 日志是不是一定要在COMMIT后才写到日志文件?如果有个很长很大的事务,那么提交日志时,日志从缓冲区被写入磁盘,岂不是要等很久?
(2) 数据是不是一定要在日志提交后,发生了CHECKPOINT,才写到数据文件?如果日志一直没提交,那么数据缓冲区岂不是很拥挤?
考虑到这2点,SQL Server还会通过Log Writer/Lazy Writer不定时的刷新日志/数据到磁盘,至于日志和数据的一致性,在启动或者数据库还原时,SQL Server会去做检查,也即是我们常说的前滚(REDO)和回滚(UNDO)。
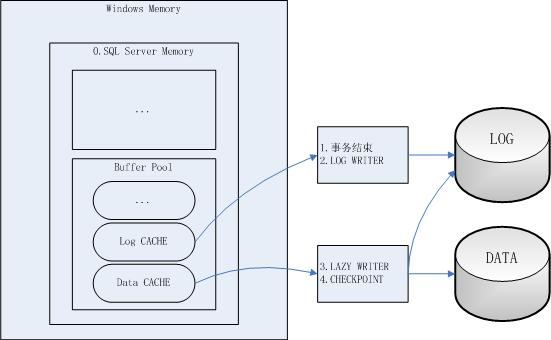
数据读写体系结构图
0. SQL SERVER MEMORY
(1) SQL SERVER占用服务器内存的一部分,非SQL SERVER占用的内存,供操作系统及服务器上其他应用程序使用;
(2) SQL SERVER内存对象可分为两大类,图中仅标出Buffer Pool中的数据及日志缓存;
1. 事务结束
(1) 事务结束的前提是日志缓存成功写入到日志文件中,也就是说客户端收到COMMIT/ROLLBACK语句运行成功的消息时,日志已被成功写入日志文件(数据还不定是否被写入数据文件);
(2) 不过,日志缓存并不是一定要等到事务结束时才刷新到日志文件的;
2. LOG WRITER
(1) 当遇到长事务时,不必等到发出事务结束命令,LOG WRITER也会周期性地将脏日志刷新到日志文件,以保证用户发出COMMIT时快速响应以结束事务;
(2) 微软并没有公布SQL SERVER 除去COMMIT外,LOG WRITER将脏日志刷新到日志文件的周期,这里可以参考ORACLE的:每3秒,或者日志缓冲区1/3满;或者已经包含1M的脏日志;
3. LAZY WRITER
(1) LAZY WRITER周期性扫描缓存(默认1s),维护自由页面(free page)列表,根据LRU算法将已刷新到磁盘的页释放;
(2) 如果是脏页,则Lazy Writer将脏页刷新到磁盘(这时事务可能还未提交),以最终将内存页释放并加入自由页面列表;
4. CHECKPOINT
(1) CHECKPOINT同LAZY WRITER一样也会刷新脏页到数据文件中(只刷新已提交的事务数据),但不会维护内存自由页面列表;
(2) 可以设置SP_CONFIGURE ‘RECOVERY INTERVAL’选项来改变CHECKPOINT发生的频率,默认为1分钟一次。
小结:可以发现,数据和日志被写入数据/日志文件,并不是同步的。有可能写入/提交了日志,数据没有写入磁盘;有可能写入了数据,事务未被提交;
(1) 针对有完整事务日志,数据未被写入磁盘的情况,启动/还原数据库时,SQL SERVER做前滚(REDO);
(2) 针对有数据写入数据文件,日志未完整提交的事务,启动/还原数据库时,SQL SERVER做回滚(UNDO)。

