前言
本篇继续我们的微软挖掘算法系列总结,前几篇我们分别介绍了:Microsoft决策树分析算法、Microsoft聚类分析算法、Microsoft Naive Bayes 算法、Microsoft 时序算法,后续还补充了二篇结果预测篇、Microsoft 时序算法——结果预算+下期彩票预测篇,看样子有必要整理一篇目录了,不同的算法应用的场景也是不同的,每篇文章都有它自己的应用场景介绍,有兴趣的同学可以参阅。本篇我们总结微软挖掘算法系列中一款比较重要的算法:Microsoft关联规则分析算法,根据马克思哲学理论,所谓世间万物皆有联系,而且联系是普遍的,此篇的Microsoft关联规则算法就是用来挖掘关联关系的典型算法,闲言少叙,我们直接进入正题。
应用场景介绍
关联规则算法是在大量数据事例中挖掘项集之间的关联或相关联系,它典型的应用就是购物篮分析,通过关联规则分析帮助我们发现交易数据库中不同的商品(项)之间的联系,找到顾客购买行为模式,如购买某一个商品对其它商品的影响。进而通过挖掘结果应用于我们的超市货品摆放、库存安排、电子商务网站的导航安排、产品分类、根据购买模式对用户进行分类,相关产品推荐等等。
比较典型的为大家所熟知的就是:啤酒和尿布的故事
其实很多电子商务网站中在我们浏览相关产品的时候,它的旁边都会有相关产品推荐,当然这些它们可能仅仅是利用了分类的原理,将相同类型的的产品根据浏览量进而推荐给你,这也是关联规则应用的一种较简单的方式,而关联规则算法是基于大量的数据事实,通过数据层面的挖掘来告诉你某些产品项存在关联,有可能这种关联关系有可能是自身的,比如:牙刷和牙膏、筷子和碗...有些本身就没有关联是通过外界因素所形成的关系,经典的就是:啤酒和尿布,前一种关系通过常识我们有时候可以获取,但后一种关系通过经验就不易获得,而我们的关联规则算法解决的就是这部分问题。
技术准备
(1)微软案例数据仓库(AdventureWorksDW208R2),这里我们应用到两张表:vAssocSeqLineItems 表和 vAssocSeqOrders 表,这两张表典型的“一对多”的关联关系,vAssocSeqOrders为订单表,vAssocSeqLineItems 表为订单明细表,两者通过OrderNumber关联,稍后的步骤我们会详细的分析这两张表内容
(2)VS2008、SQL Server、 Analysis Services
操作步骤
(1)我们这里还是利用上一期的解决方案,然后数据源,然后数据源视图,很简单的步骤,不明白的可以看我们前面几篇文章,然后将这两张表的主外键关联上,我们来看图:
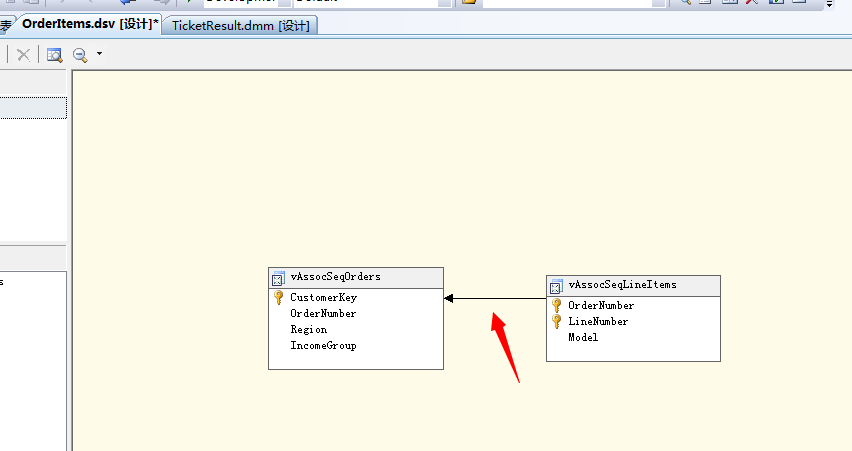
很基础的东西,这里不做过多的解释,Orders为主表,Items为明细表,通过CustomerKey主键进行关联,下面我们浏览下这两张表里面的数据:
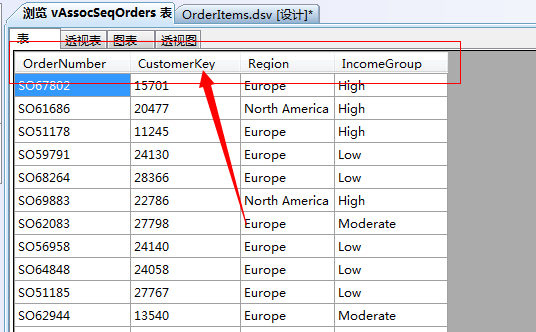
vAssocSeqOrders表内容很简单:订单号(逻辑主键)、客户号(客户表的外键)、地区、收入类型,别的没啥可预览的,这种表是太基础的内容,来看另外一张表:
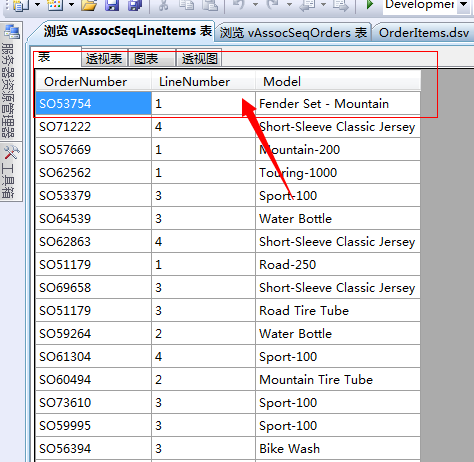
vAssocSeqLineItems表,订单号(外键)、购买数量、购买产品,很简单的一张表
(2)新建挖掘结构
这里我们新建这个数据的挖掘模型,很简单的下一步、下一步就行,有不明白的可以参照我以前的内容或者私信我,我们来看几个关键的步骤:
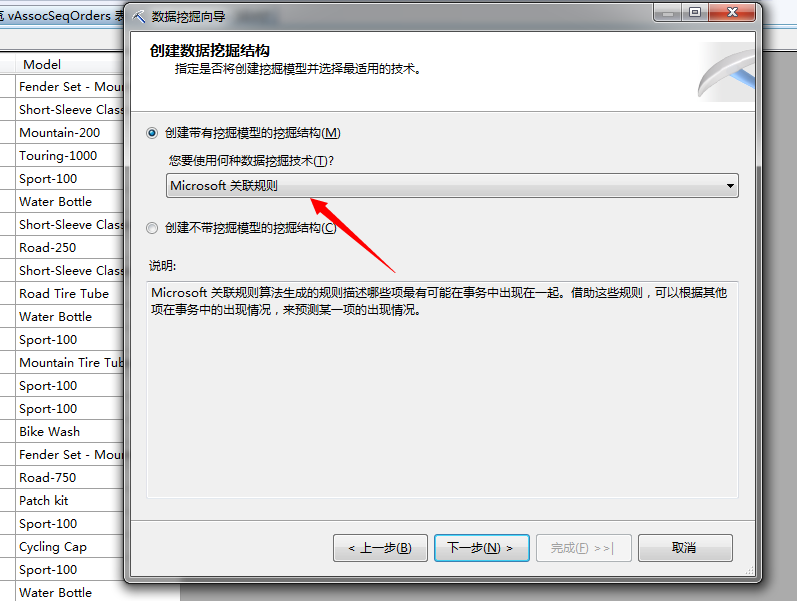
这里我们选择Microsoft关联规则算法,然后下一步:
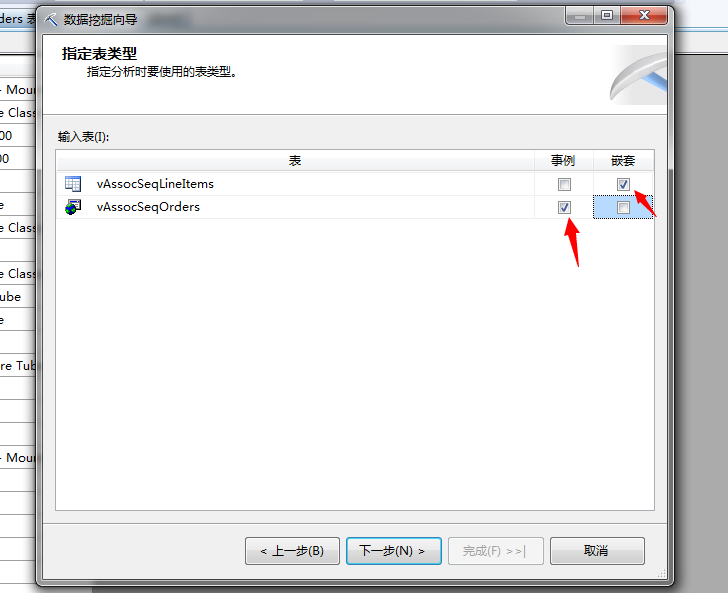
这里我们标示好事例表和嵌套表,下一步我们指定定型数据
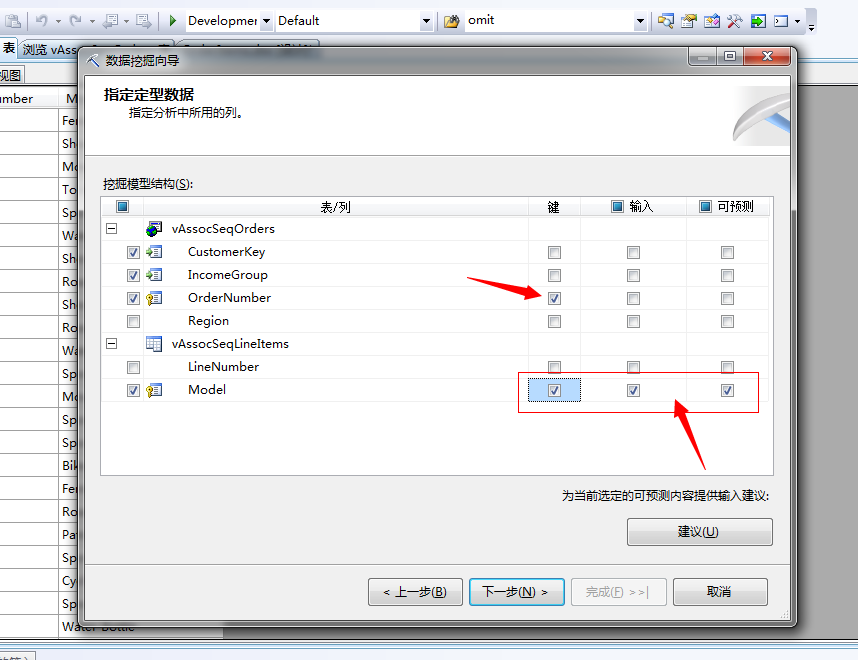
这这里面我们配置好键、和输入、输出预测列,然后起个名字:relevance
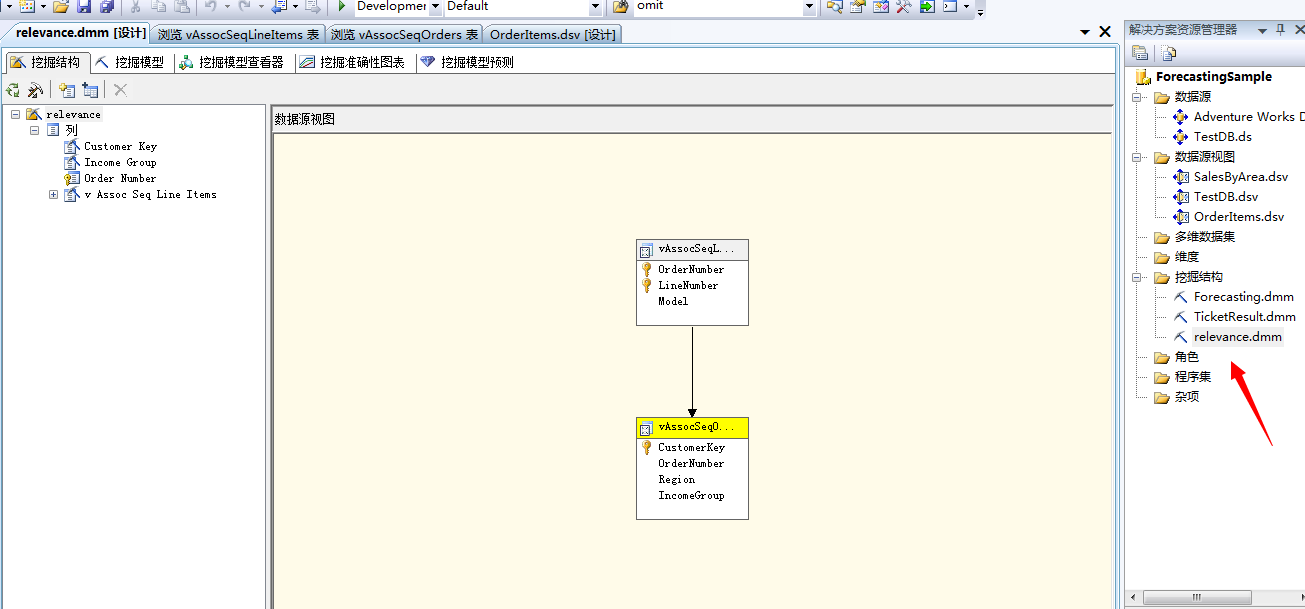
至此,我们的Microsoft关联规则分析算法已经初步建立好了,下面一步我们来配置该算法几个关键属性值。
(3)参数配置
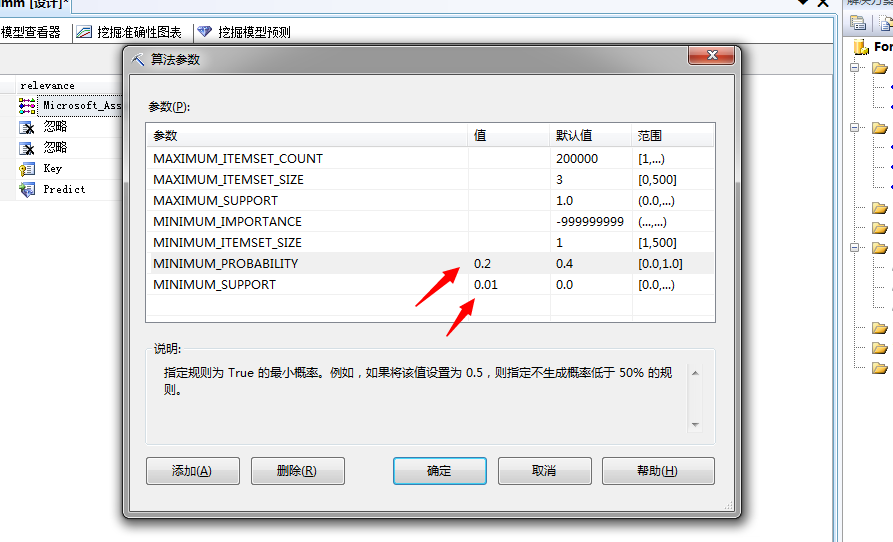
此种算法有两个参数比较重要,我们来看:
Support:定义规则被视为有效前必须存在的事例百分比。也就是说作为关联规则筛选的事例可能性,比如设置成10%,也就是说在只要在所有事例中所占比为10%的时候才能进行挖掘。
Probability:定义关联被视为有效前必须存在的可能性。该参数是作为结果筛选的一个预定参数,比如设置成10%,也就是说在预测结果中概率产生为10%以上的结果值才被展示。
我们将该模型的两个参数设置为:
MINIMUM_PROBABILITY = 0.2
MINIMUM_SUPPORT = 0.01
我们部署该模型,然后运行,我们来查看结果。
结果分析
部署完程序之后,我们通过“挖掘模型查看器”进行查看分析,不废话,我们直接看图:
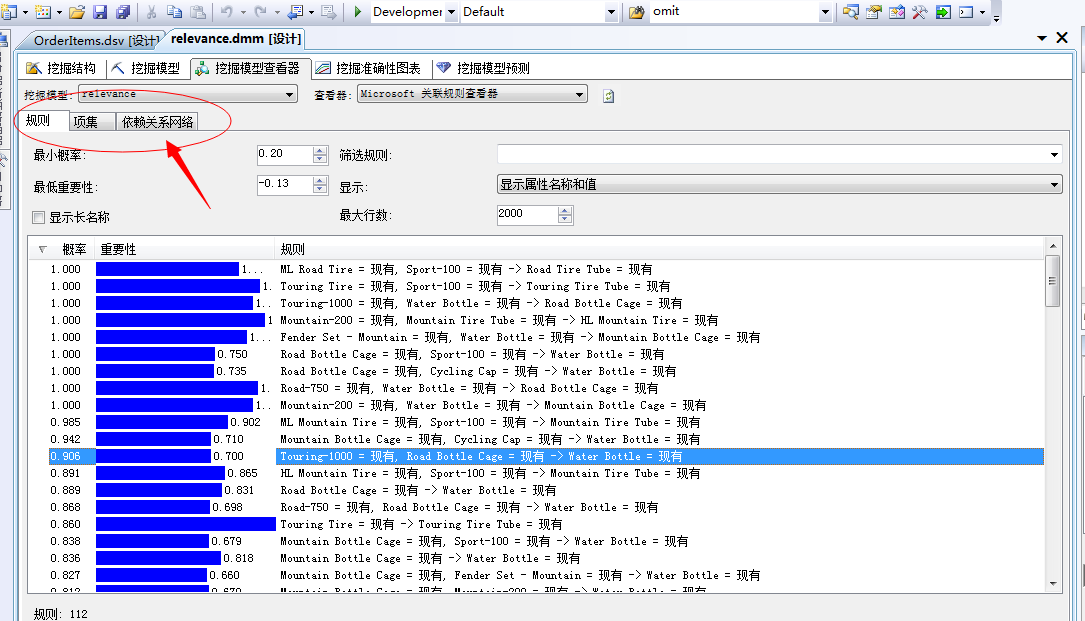
从上面的截图中我们可以看到,Microsoft关联规则算法有三个面板来展示结果:规则、项集、依赖关系网络
下面我们分别来介绍这三个面板,第一个,规则:
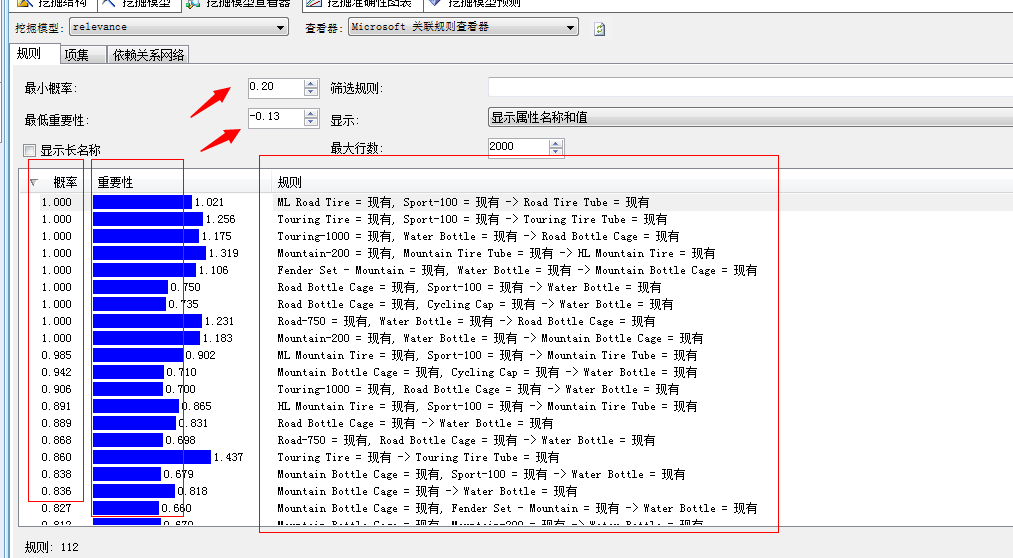
上面有几个条件筛选项,第一个就是设置最小概率值,也就是上面我们新建模型设置的参数,第二个是是筛选规则,通过它我们找到相应的产品方便我们查看,还有一个重要性的参数,同样的对于下面结果中的第二列可能性列,最大行数设置显示的行数。
下面结果的表格中,第一列概率的值就是产品之前会产生关联的概率,按照概率从大到小排序,第二列为可能性,该度量规则的有用性。该值越大则意味着规则越有用,设置该规则的目的是避免只使用概率可能发生误导,比如有时候超市里举行促销活动会每个人都免费给一间物品,如果仅仅根据概率去推测,这件物品的概率将是1,但是这个规则是不准确的,因为它没有和其它商品发生任何关联,也就是说该值是无意义的,所以才出现了“重要性”列。
第三列即为我们的挖掘出来的结果项,前面为已有的产品项,‘—>’后面的即为推测的产品项,我们举个例子,比如:
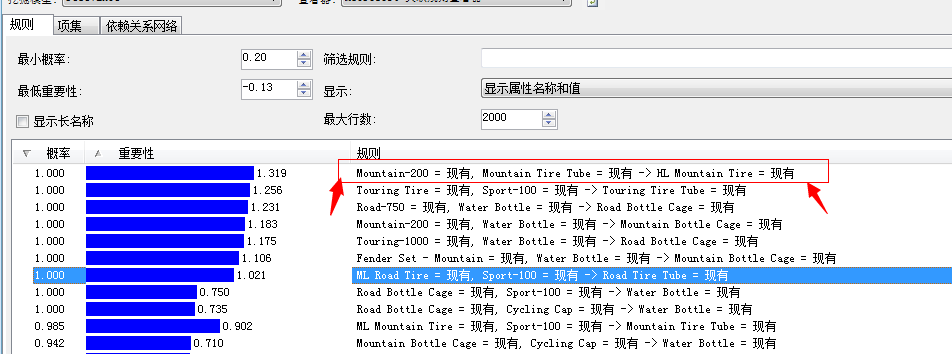
经过排序可以看到,上图中的该条规则项为关联规则最强的一种组合:前面的为:山地自行车(Mountain-200)、山地自行车内胎(Mountain Tire Tube)然后关联关系最强的为:自行车轮胎(HL Mountain Tire)
嗯,有道理的很呀,有了山地自行车了,然后同样也具备山地自行车内胎,剩下的就是需要自行车轮胎了。
其它的也是同样的分析方法,这里我们就不分析了,有兴趣的可以自己分析,嘿..我看到上面的第三条:
自行车(Road-750)、水壶(Water Bottle)->自行车水壶框(Road Bottle Cage)
....自行车、水壶,肯定得买个自行车水壶框了......
这个水壶好有个性,下面我们来具体看看跟这个利器有关的商品有哪些....嘿嘿...我们来看图:
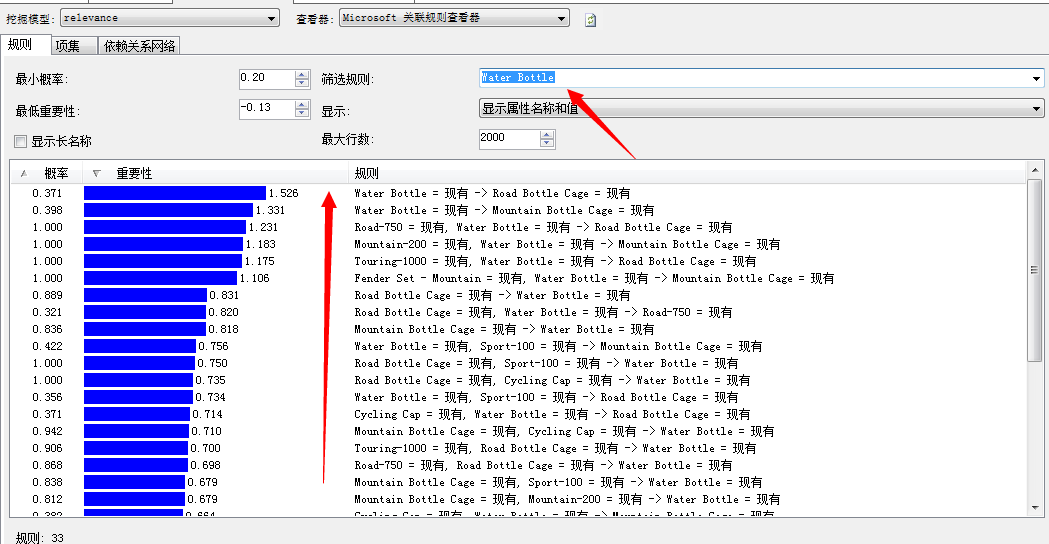
我那个去....瞅瞅...第一个结果:水壶框(Road Bottle Cage、Mountain Bottle Cage)...下面我目测了下...我可以明确的告诉你,丫的..这个名字叫Water Bottle(水壶...嘿嘿原谅我的E文能力)的利器最相关的就是水壶框(Bottle Cage)了...
超市里东西怎么摆放? 网站上该产品的相关推荐该推荐神马? 有一个顾客已经买了这个东西你推荐它啥懂了吧?......
下面我们来看第二个面板能告诉我们什么,我们打开“项集”面板:
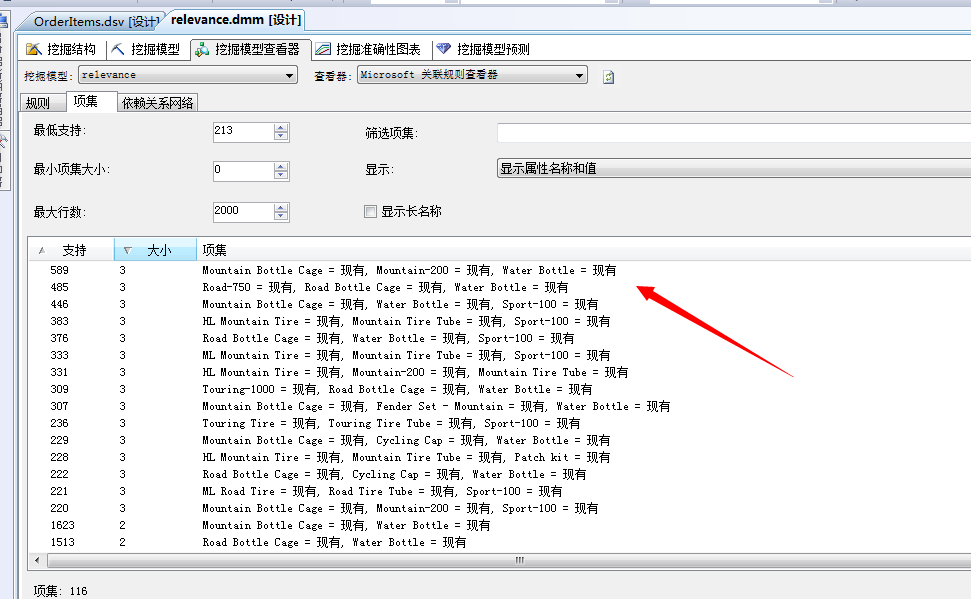
这个面板也简单的很,上面有几个筛选框设置我们的最低支持数,最小的项集大小,最大行数,这个没啥说的,很简单,下面的结果集显示的为我们的数据集合中“支持”的事例集合个数、然后“大小”就是该规则下里面的项集的个数,第三列就是项集的详细了。
我去...上面我们分析的水壶(Water Bottle)竟然排在了第一行,该行中的项集明细为:山地自行车(Mountain-200)、水壶(Water Bottle)、自行车水壶框(Road Bottle Cage),第二行也有,看来这厮看来很有分析价值,我们后续接着分析,嘿嘿
我们进入第三个面板“依赖关系网络”,我们来看:
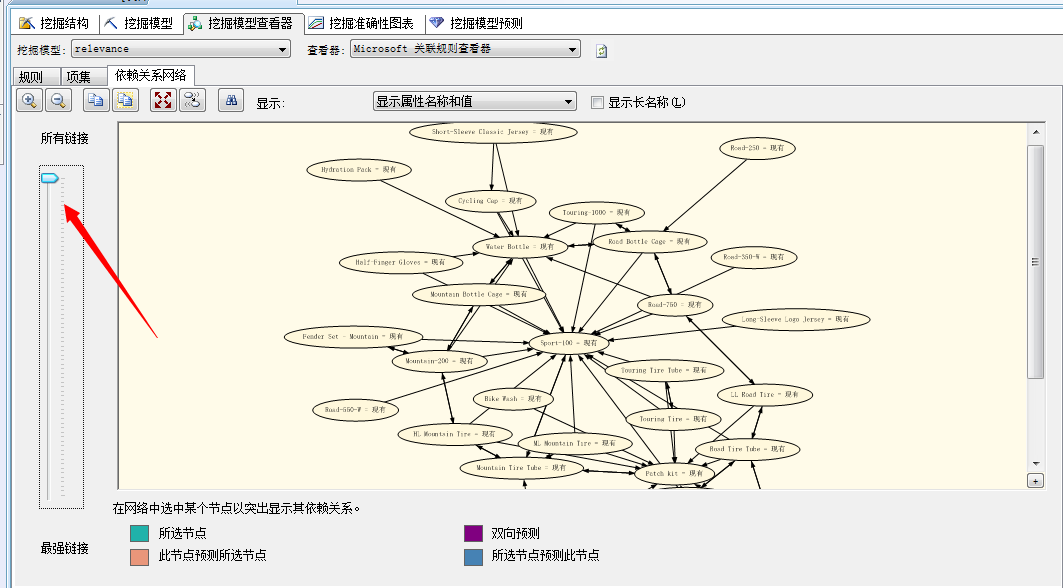
这幅图已经很熟悉了吧,前几篇文章中均有介绍,分析各种产品之间的关联关系的强弱,拖动右侧的滑动条然后进行分析
嘿嘿...我小心翼翼的拖动了这个滑动条...试图找找上面我们分析的哪款利器(Water Bottle):
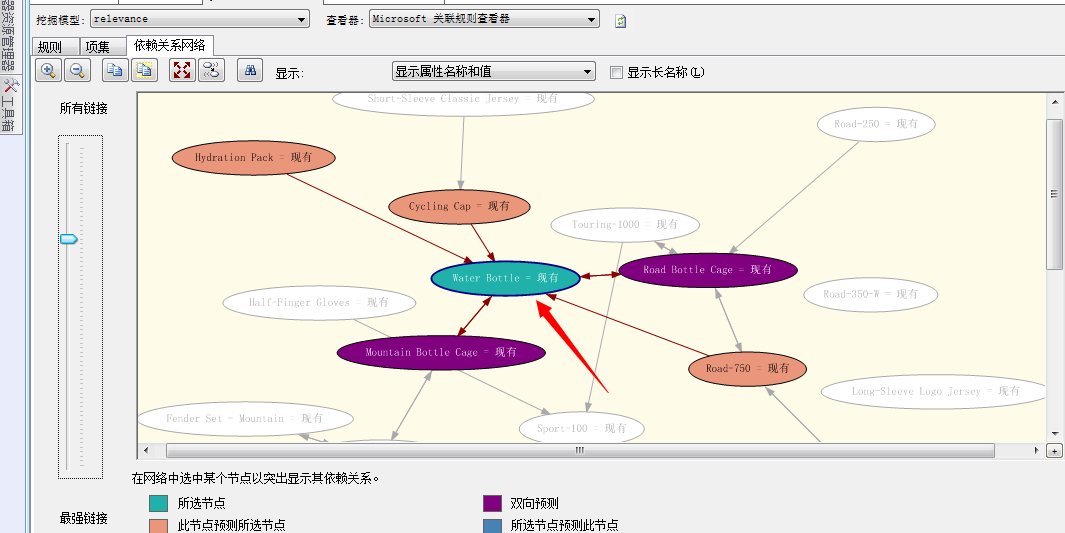
嘿嘿...找到了,上图中就标示了这玩意相关的商品,我们来看Mountain Bottle Cage、Road Bottle Cage这两个都是双向关联,然后Road-750、Cycling Cap、Hydration Pack...
其它的商品也利用这种规则进行分析,有兴趣的可以自己分析。
推测结果导出
我们到此步骤直接将该模型的分析结果进行预测,暂且不验证其准确性,直接将结果导出,来看看该算法的应用项,我们进入“挖掘模型预测”:
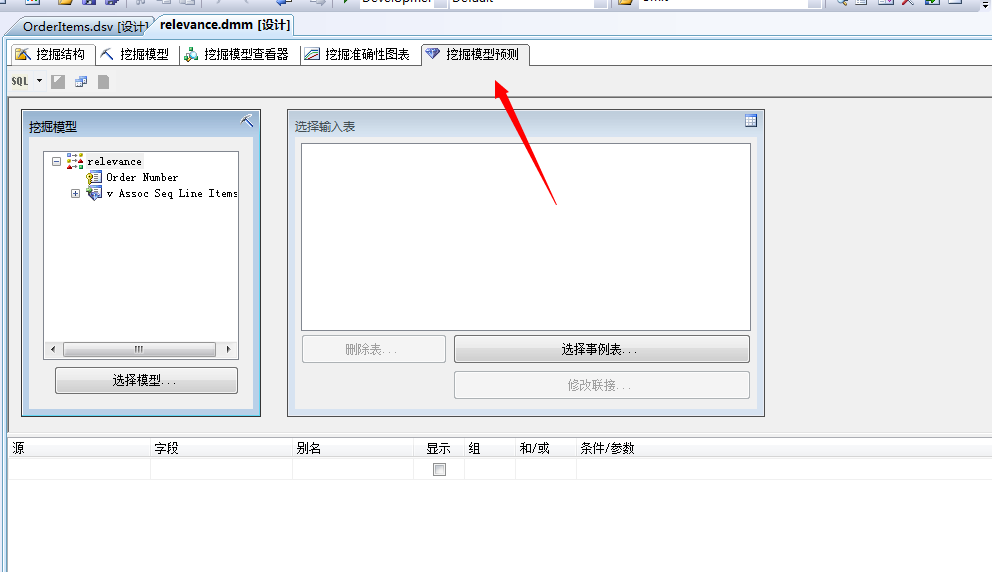
在下面的网格中设置我们的挖掘筛选规则,点击“源”,选择“预测函数”,选择PredictAssociation,将vAssocSeqLineItems,将其拖到网格中 PredictAssociation 函数的“条件/参数”框。然后设置该参数为[Association].[v Assoc Seq Line Items],3
我们点击运行,直接来查看结果:
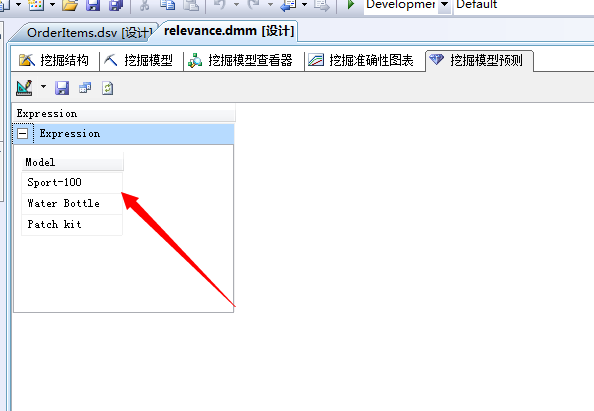
看,上面的Microsoft关联规则算法给我们推荐出来关联性最强的三种产品,分别为:Sport-100、Water Bottle、Patch kit...
当然有时候我需要只查看某一种商品,不关系其它的产品有什么关联关系,我们来做单独查询,我们在菜单中的“挖掘模型”,然后选择“单独查询”:
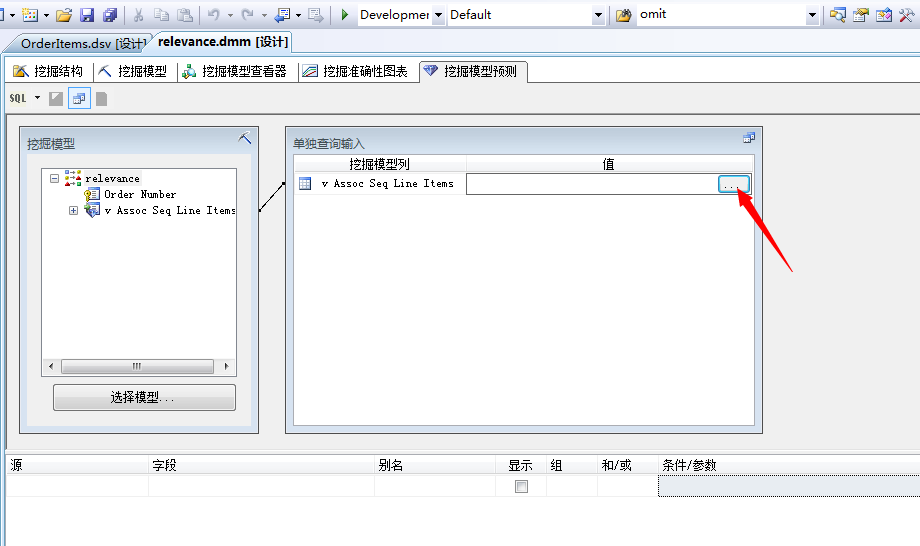
点击开单独筛选的条件框:
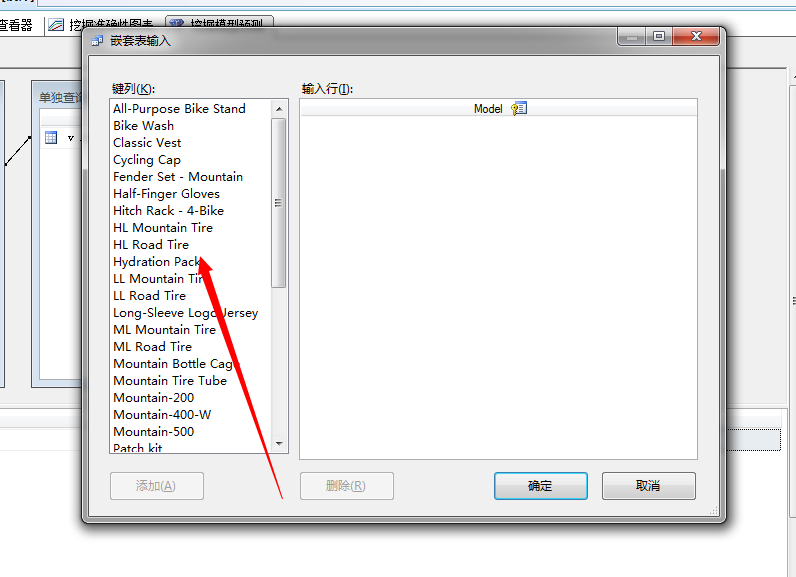
在“嵌套表输入”对话框中,选择“键列”窗格中的 Touring Tire
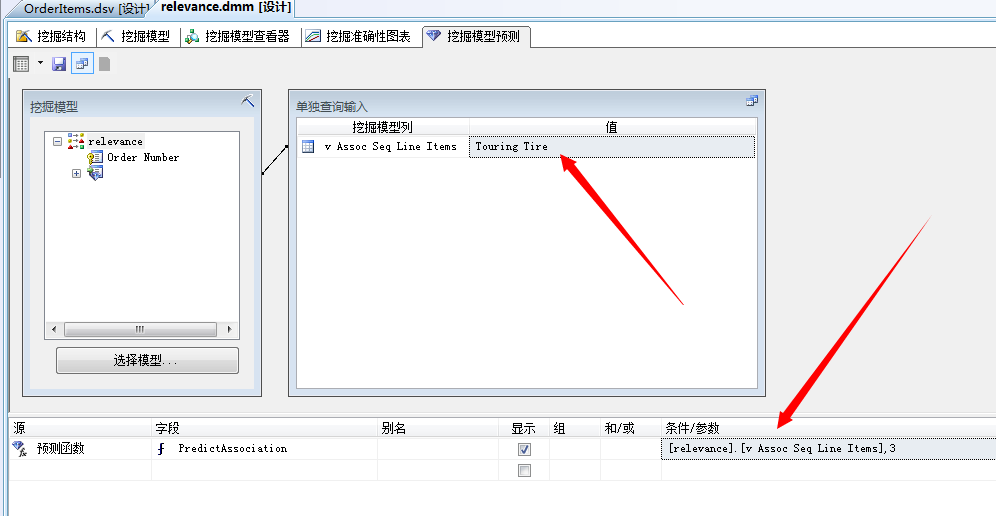
我们点击运行,来查看结果:
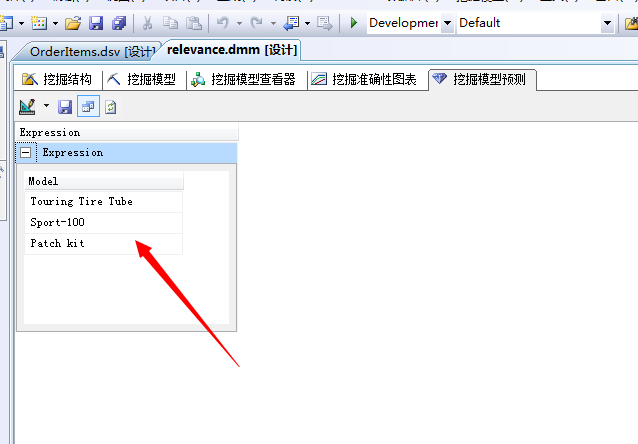
可以看到这里我们只是筛选出了该商品的关联关系结果集,当然这里我们可以显示出该产品之间的关联的关系值,这里我们直接写语句: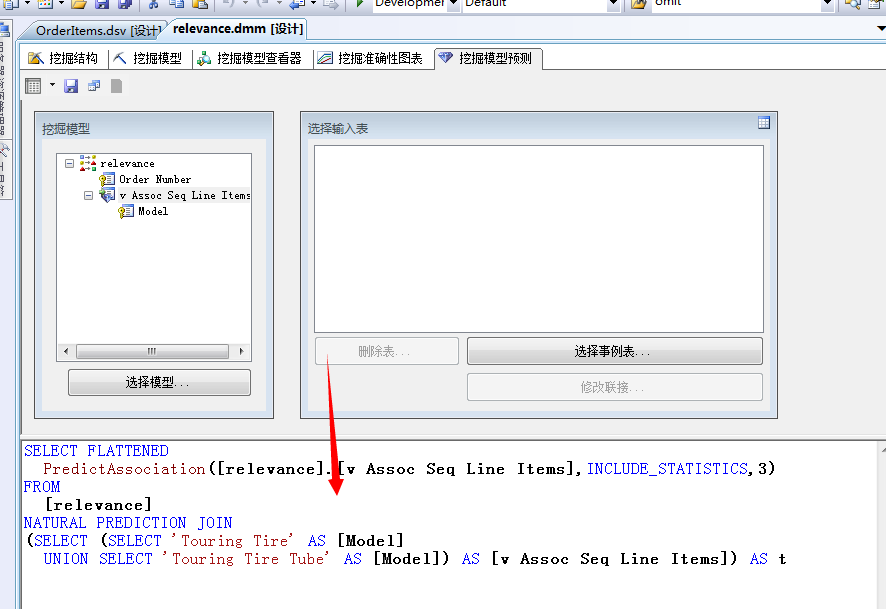
点击运行,我们来看结果:
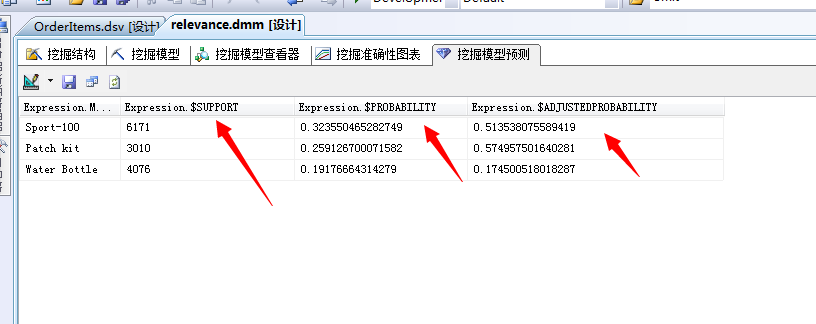
这里我们能看到,商品、支持的事例数,可能行、概率等明细值。
对于Microsoft关联规则算法还有一种更有趣的应用就是,根据现有的顾客已经买的的产品,然后利用它自己的挖掘模型进行推测,推测出这个顾客将下一个买什么产品,比如上面的例子中,如果某个顾客已经买了山地自行车、自行车内胎,那么利用该模型它会自动推测出该顾客下一步将会买自行车轮胎,这个用法其实很关键,通过该方法预测已经能推测出顾客下一步的购买意向!...
如果将该挖掘模型利用到电子商务网站...那么他们推荐的商品将更准确,同样所得到的精准销售也更到位...结果你懂的!
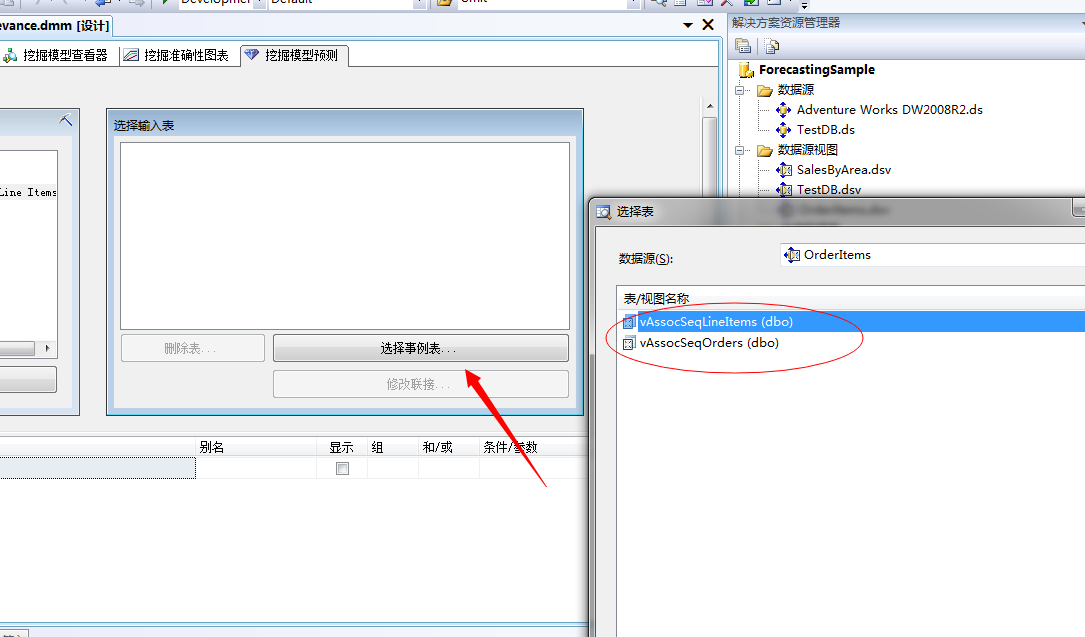
我们来看步骤:
我们来选择应用的事例表:
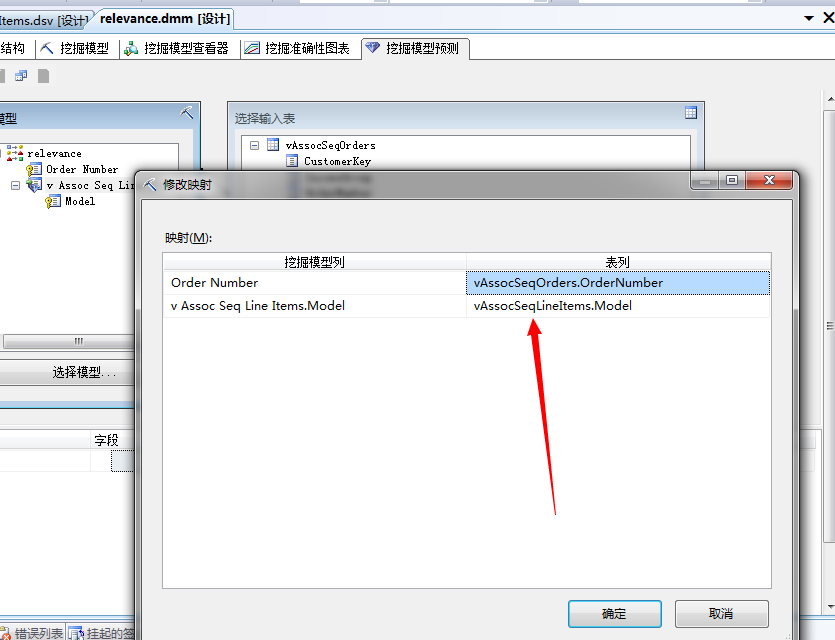
我们来选择两者的关联关系,可以右键直接编辑:
然后编辑筛选函数,直接看图:
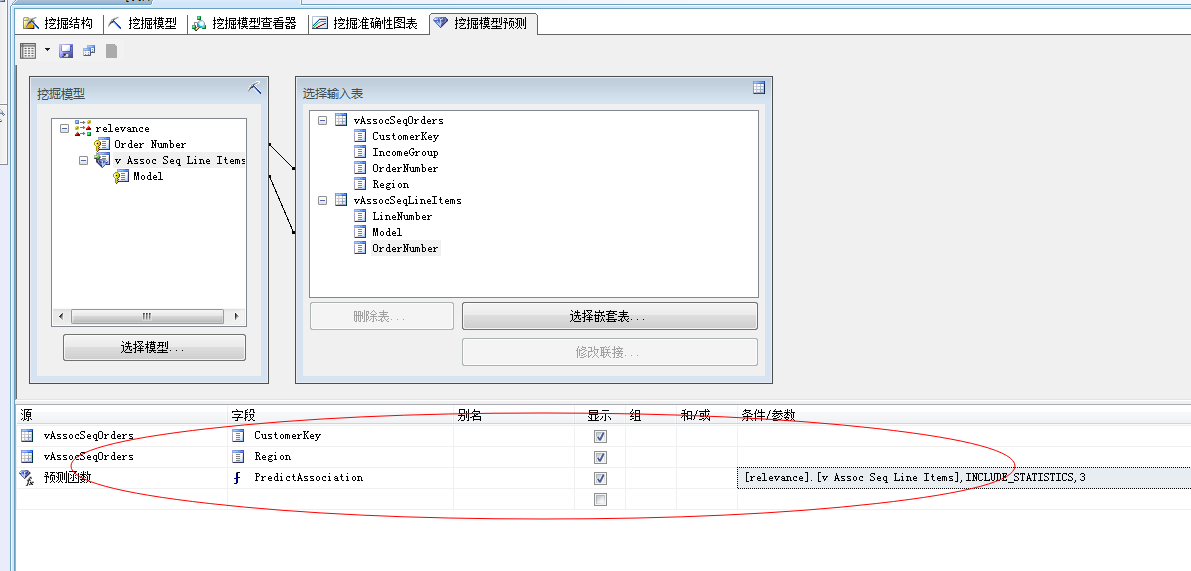
点击查看结果:
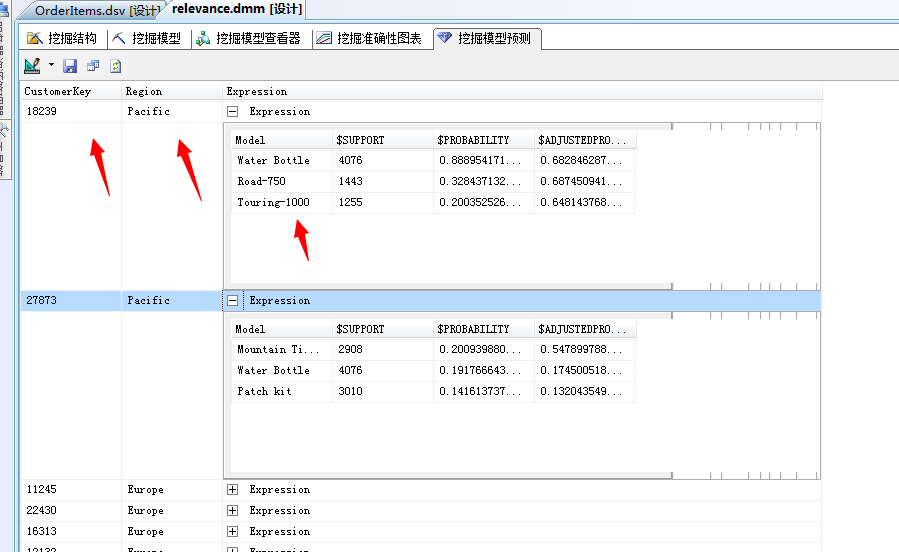
可以看到,这个顾客编号为:18239的他将买优先买三个产品:Water Bottle、Road-750、Touring-1000,后面还列出他的概率和可能性...
嘿嘿..我们打开数据库来看看这个顾客的情况:
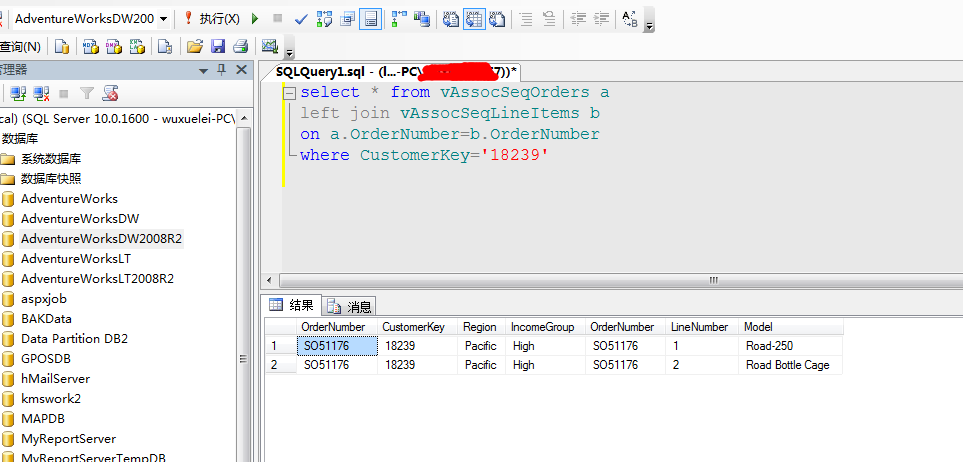
.....嘿嘿...这个顾客已经买了两个商品了,Road-250、Road Bottle Cage,根据上面的推算法则...这个顾客应该马上急需要买一个叫做Water Bottle的神器...用来喝水
然后,我们将这个结果保存到数据库..一段简单的代码就能搞出那些顾客急需要什么商品...
他们最可能买的商品有哪些....,剩下的工作你懂得!
结语
本篇文章到此结束了...结语就是我们后面还会继续分析其它的算法,有兴趣的童鞋可以提前关注。上面其实还有几部分需要补充,就是准确性验证和筛选条件挖掘,比如我想知道某些特定客户群体他们的购买的产品关联规则等等吧,后续文章继续分析这些问题。
文章的最后我们给出前几篇算法的文章连接:
如果您看了本篇博客,觉得对您有所收获,请不要吝啬您的“推荐”。