系列文章
前言
本文会介绍一款分布式NoSQL如何实现数据高可靠和服务高可用,这是一款云上的NoSQL服务,叫做表格存储。对于分布式NoSQL,大家可能会想到很多名字,比如HBase、Cassandra,AWS的DynamoDB等,这类NoSQL在设计之初就作为一个分布式系统支持超大规模的数据量与并发。此外大家可能还会想到MongoDB和Redis,这两个也提供集群功能,但是一般需要人为的配置sharding和复制集/主从等。
表格存储是阿里自主研发的一款NoSQL服务,在架构设计上参考了google的bigtable论文,与上述的HBase、Cassandra、DynamoDB有一些相似之处。表格存储的一些功能优势可以见下图。

本文会重点介绍表格存储在高可靠和高可用方面的技术。表格存储按照11个9的数据可靠性和4个9的服务可用性进行标准设计,作为一款云服务,提供10个9的可靠性和3个9的可用性SLA。
容错、高可靠、高可用
容错、高可靠、高可用是相互关联的几个概念。容错是指系统能够快速检测到软件或硬件的故障并快速从故障中恢复的能力,容错的一般实现方式是冗余,冗余可以保障一份坏掉系统不受影响。高可靠是衡量数据安全性,高可用是衡量系统的可用时间,一般高可靠和高可用的指标都用几个9来表示。
冗余可以实现容错,在数据层面一般表现为数据有多个副本,任意一份损坏不会影响数据完整性,在服务层面可以表现为有多个服务节点,任意一个节点宕机可以将服务迁移到另外的节点。服务高可用会依赖于数据高可靠,因为假如数据的完整性都没有保障,那么谈不上服务的可用性。
容错系统并非一定是高可用的,高可用衡量的是系统的可用时间,假如系统不支持热升级,或者不支持动态扩缩容等,就需要停机进行运维操作,这也是不满足高可用的。
为了获得更高的可用性,可以将两套系统或者多套系统组成主备,搭建容灾,常见的比如同城双机房场景。同城双机房配合自动切换或者快速的人工切换,可以使系统达到更高的可用性。此外,业务可以对应用进行一些弹性的架构设计,在某些服务出现异常时可以自动降级,提高业务的可用性。
表格存储如何实现高可靠和高可用
传统的MySQL主备同步方案,当主库出现故障时,HA模块会将服务迁移到备库,实现高可用。这种方式存在的问题就是,如果要保障数据的强一致,那么一定要主库和备库都写入成功才能返回,即最大保护模式。如果备库出现不可用,主库写入也会失败,所以实际上可用性和一致性无法兼得。
分布式系统中,单机故障率相同情况下,集群中存在单机故障的概率随着集群规模增加而增加,高可靠和高可用成为分布式系统最基本的设计目标。分布式系统中,实现数据高可靠往往通过多副本加Paxos等分布式一致性算法,实现高可用一般是实现快速的故障迁移机制,实现热升级和动态的扩缩容。
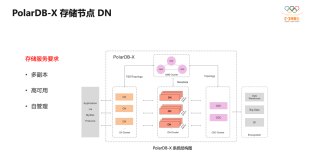
那么表格存储如何来实现高可靠和高可用呢,我们首先看下面的架构图:

图中的Table Worker代表表格存储的后端服务节点,在它下层有一个系统叫做盘古。盘古是阿里自研的一款先进的分布式存储系统,分布式存储是一种共享存储,Table Worker的任意一个节点都可以访问盘古中的任意一个文件。同时,这也是一种存储与计算分离的架构。
数据高可靠
盘古会专注于解决好分布式存储领域的问题,最基本的就是保证数据高可靠,并且提供强一致性保证。我们使用盘古时配置了三份数据副本,任意一份副本丢失不会影响读写和数据完整性。在写入时,盘古保证至少两份写成功后返回,并在后台修复可能存在的一份副本写入失败的情况。读取时,大部分情况只需要读取一份副本即可。
服务高可用
1. 表格存储的数据模型
首先我们来看一下表格存储的数据模型,如下图所示:

表格存储中的一张表由一系列行组成,每行分为主键和属性列,主键可以包含多个主键列,比如用如下方式表示的一个主键就包含三个主键列,三列的类型都为string:
PrimaryKey(pk1:string, pk2: string, pk3: string)
第一列主键列作为分片键(Partition Key),上面的例子中分片键就是pk1。表中的所有数据会按照主键(包含三个主键列)进行排序,按照分片键的范围进行分片。当一个表的数据或者访问量越来越多时,分片就会进行分裂,做动态的弹性扩展,一张较大数据量的表会有几百到几千个分片。
为什么要这样设计?简单来说,一方面所有数据按照主键排序,整个表就可以看作一个巨大的SortedMap,可以在任意主键区间进行范围查询,另一方面第一列主键列是分片键,所有第一列主键列相同的数据都在一个分片中,便于做分片内的功能,比如自增列、分片内的事务、LocalIndex等。
为什么分片键可以做成sorted key,而不是hash key?这是因为我们使用了共享存储的能力,对一个分片进行不断的切分时,不需要搬运数据,而且数据本身就已经被盘古打散了。假如没有共享存储,就需要考虑如何处理数据分布,比如使用一致性hash算法等,分片键一般都是hash key,就失去了全表任意主键区间范围查询的能力。
2. 高可用实现
那么回到正题,如何来实现服务高可用呢?假如一张表有100个分片,这些分片会被不同的worker加载,当一台worker挂掉时,上面的分片会自动迁移到其他可用的worker上。一方面,单台worker故障只会影响一部分分片,不会影响全部分片。另一方面,由于我们使用的是共享存储盘古,任意一台worker都可以加载任意一个分片,计算资源是与存储资源分离的,这就可以把failover过程做的非常快,架构也更加简单。
上面讲的是故障迁移(failover),其实这种架构下也可以做非常灵活的负载均衡(load balance)。当一个分片上的读写压力过大时,可以迅速的将一个分片切分成两个或者更多个分片,加载到不同的Worker上。分片切分时不需要将父分片的数据迁移到子分片中,而是在子分片中建立父分片的文件的link,后续再通过后台的compaction来将数据真正切分出来,消除link。一个分片切分后可以继续向下切分,所有分片会均摊到集群的不同Worker上,充分利用集群的CPU和网络资源。
3. 运维、升级、硬件更新
作为一款云服务,服务端的日常运维、升级、硬件更新换代对于用户而言是完全透明的,这些运维操作也都必须按照高可用标准进行设计。分布式系统的运维是一项非常复杂的工作,假如不使用云服务,运维将是一项繁重而且风险极高的事情,可能经常会有停机升级,还需要处理各种故障。另外,机器硬件也在不断更新换代,云服务为了提供给用户更好的性能,会不断更新新的硬件,建设更好的网络。我们相信,作为一款云上的数据库,可以提供给用户更好的性能,更高的可用性和更好的使用体验。
总结
表格存储通过共享存储盘古来实现数据高可靠,通过快速的failover、灵活的负载均衡实现高可用,在总结上面两个技术实现过程中,我们也可以看到共享存储带给分布式NoSQL很大的优势,而云服务又提供给用户非常大的便利,我们在此再做一些总结:
使用共享存储盘古的优势:
- 存储与计算的分离,带来架构的灵活性和功能解耦,存储层和应用层都可以专注于解决自身领域的问题。盘古除了提供基本的数据可靠性保障,还可提供混合存储、冷热数据分离、纠删码、跨可用区的多副本分布等能力。
- 盘古带来诸多功能优势的同时,还可以带来性能的提升。随着新硬件和新技术的使用,共享存储的性能已经开始超越应用层通过系统内核接口读写本地磁盘的性能。
表格存储作为一款云服务的优势:
- 提供给用户高可靠和高可用的SLA保障,自动化地快速解决分布式系统的单点故障问题、热点问题,运维、升级和硬件更新对用户完全透明,最大化的减少用户的运维负担。
- 即开即用,按量付费。通过数据分片和快速的分片切分能力,灵活的适应用户业务量的变化,提供千万级别的qps能力,并且用户也不会因为为了给高峰期预留资源而浪费成本。
- 服务端会定期的进行功能迭代和升级,推出新的功能,不断优化性能,提高可用性等,云上用户会得到越来越好的体验。
- 有任何使用上的问题,或者表设计上的疑问,都可以加我们钉钉公开群进行交流,我们的研发同学会在其中进行解答,二维码如下,钉钉公开群群号:11789671