更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud
作为一个深度学习的老司机,你是不是以为只有Python才能够玩转深度学习?如果是这样的话,那么本文作者可能就要教你怎么“做人”了。毕竟大牛的世界我们不懂!
第一个版本C++的深度学习库(DLL)1.0发布了!DLL是一个关注速度和易用性的神经网络库。大约4年前,作者就开始编写这个库。为了获得博士学位,作者需要一个很好的库来训练和使用受限制的玻尔兹曼机器(RBMs),因为当时还没有很好的库来完成这项工作。所以我决定自己写一个库(大牛就是任性!)。它现在可以支持RBM和卷积RBM(CRBM)模型,也可以使用对比发散预先训练RBM(或深层信念网络(DBN))的堆栈,然后通过微型批量梯度下降或共轭梯度进行微调或用作特征提取器。近年来,该库已经可以处理人造神经网络(ANN)和卷积神经网络(CNN)。该网络还可以训练常规的自动编码器,还提供了几个高级层,如Dropout或批次规范化(BN),以及自适应学习率技术,如Adadelta和Adam。该库还集成了对几个数据集的支持:MNIST,CIFAR-10和ImageNet。
该库是使用C ++接口,它需要一个C ++ 14编译器。
在这篇文章中,我将介绍一些关于使用该库的例子,并提供有关库表现和项目路线图的一些信息。
小例子
我们来看看一个使用这个库的例子:
#include "dll/neural/dense_layer.hpp"
#include "dll/network.hpp"
#include "dll/datasets.hpp"
int main(int /*argc*/, char* /*argv*/ []) {
// Load the dataset
auto dataset = dll::make_mnist_dataset(dll::batch_size<100>{}, dll::normalize_pre{});
// Build the network
using network_t = dll::dyn_network_desc<
dll::network_layers<
dll::dense_layer<28 * 28, 500>,
dll::dense_layer<500, 250>,
dll::dense_layer<250, 10, dll::softmax>
>
, dll::updater<dll::updater_type::NADAM> // Nesterov Adam (NADAM)
, dll::batch_size<100> // The mini-batch size
, dll::shuffle // Shuffle before each epoch
>::network_t;
auto net = std::make_unique<network_t>();
// Train the network for performance sake
net->fine_tune(dataset.train(), 50);
// Test the network on test set
net->evaluate(dataset.test());
return 0;
}
这是在MNIST数据集上训练和测试一个简单的三层全连接神经网络。
首先,在头文件中,你需要列出你正在使用的层,这里只有密集层;然后,你需要包括network.hpp这是每个网络的基本包括;最后一个头文件是数据集。
在main函数中,首先我们需要完整的加载MNIST数据集并传递两个选项。在这里,我们要设置批量大小,并指示每个样本应归一化为具有零均值和单位方差。
之后是最重要的一部分,网络的声明。在DLL中,网络是一种类(Type)。这个类有两个部分:网络层(一个dll::network_layers)和选项(一个可选的选项列表,在网络层后)。在上述代码中,我们有三层,第一层有500个隐藏单元,第二层有250个隐藏单元,最后一层有10个。每层可以采用可选的选项列表。第三层使用softmax激活函数而不是默认的S形函数。我们正在使用Nesterov Adam(NAdam)更新器,批量大小为100(必须与数据集批量大小相同),数据集在每个时期之前被混洗。
最后,我们简单地创建网络std::make_unique,然后在训练集上训练50次,最后在测试集上进行测试。
如果你编译并运行这个程序,你应该看到这样的:
Network with 3 layers
Dense(dyn): 784 -> SIGMOID -> 500
Dense(dyn): 500 -> SIGMOID -> 250
Dense(dyn): 250 -> SOFTMAX -> 10
Total parameters: 519500
Dataset
Training: In-Memory Data Generator
Size: 60000
Batches: 600
Augmented Size: 60000
Testing: In-Memory Data Generator
Size: 10000
Batches: 100
Augmented Size: 10000
Train the network with "Stochastic Gradient Descent"
Updater: NADAM
Loss: CATEGORICAL_CROSS_ENTROPY
Early Stop: Goal(error)
With parameters:
epochs=50
batch_size=100
learning_rate=0.002
beta1=0.9
beta2=0.999
Epoch 0/50 - Classification error: 0.03248 Loss: 0.11162 Time 3187ms
Epoch 1/50 - Classification error: 0.02737 Loss: 0.08670 Time 3063ms
Epoch 2/50 - Classification error: 0.01517 Loss: 0.04954 Time 3540ms
Epoch 3/50 - Classification error: 0.01022 Loss: 0.03284 Time 2954ms
•••••••••••••••••••
Epoch 48/50 - Classification error: 0.00352 Loss: 0.01002 Time 2665ms
Epoch 49/50 - Classification error: 0.00232 Loss: 0.00668 Time 2747ms
Restore the best (error) weights from epoch 40
Training took 142s
error: 0.02040
loss: 0.08889
首先显示网络和数据集信息,如代码中所设定的,然后用数据训练网络,按次数划分。最后,评估结果。在大约2分半左右的时间里,我们训练了一个能够将MNIST数字分类出错率为2.04%的神经网络,这已经不错的,但仍然可以改进。
几个关于如何编译的信息:你可以直接sudo make install_headers在计算机上安装dll库。然后,你可以使用以下方式简单地编译文件:
clang ++ -std = c ++ 14 file.cpp或者,如果将dll复制到本地dll目录中,这编译的时候需要指定include文件夹:
clang++ -std=c++14 -Idll/include -Idll/etl/lib/include -dll/Ietl/include/ -Idll/mnist/include/-Idll/cifar-10/include/file.cpp
有几个编译选项,以提高性能:
1.-DETL_PARALLEL:允许并行计算。
2.-DETL_VECTORIZE_FULL:启用算法的全矢量化。
3.-DETL_BLAS_MODE:让库知道一个BLAS库(例如MKL)。然后,你必须为你选择的BLAS系列添加包含选项和链接选项。
4.-DETL_CUBLAS_MODE:让库知道NVIDIA cublas在本机上可用。然后必须添加相应的选项(包括目录和链接库)。
5.-DETL_CUDNN_MODE:让库知道NVIDIA cudnn在本机上可用。然后必须添加相应的选项(包括目录和链接库)。
6.-DETL_EGBLAS_MODE:让库知道你在本机上安装了etl-gpu-blas。然后必须添加相应的选项(包括目录和链接库)。
如果你想要最佳的CPU性能,你应该使用前三个选项。如果你想要最好的GPU性能,你只需启动第三个。理想情况下,你可以启用所有选项,因此你将获得最佳性能,因为GPU尚未完全支持。
我们再次进行相同的实验,但是使用具有两个卷积层和两个池层的卷积神经网络:
#include "dll/neural/conv_layer.hpp"
#include "dll/neural/dense_layer.hpp"
#include "dll/pooling/mp_layer.hpp"
#include "dll/network.hpp"
#include "dll/datasets.hpp"
#include "mnist/mnist_reader.hpp"
#include "mnist/mnist_utils.hpp"
int main(int /*argc*/, char* /*argv*/ []) {
// Load the dataset
auto dataset = dll::make_mnist_dataset(dll::batch_size<100>{}, dll::scale_pre<255>{});
// Build the network
using network_t = dll::dyn_network_desc<
dll::network_layers<
dll::conv_layer<1, 28, 28, 8, 5, 5>,
dll::mp_2d_layer<8, 24, 24, 2, 2>,
dll::conv_layer<8, 12, 12, 8, 5, 5>,
dll::mp_2d_layer<8, 8, 8, 2, 2>,
dll::dense_layer<8 * 4 * 4, 150>,
dll::dense_layer<150, 10, dll::softmax>
>
, dll::updater<dll::updater_type::NADAM> // Momentum
, dll::batch_size<100> // The mini-batch size
, dll::shuffle // Shuffle the dataset before each epoch
>::network_t;
auto net = std::make_unique<network_t>();
// Display the network and dataset
net->display();
dataset.display();
// Train the network
net->fine_tune(dataset.train(), 25);
// Test the network on test set
net->evaluate(dataset.test());
return 0;
}
与上一个例子相比,没有什么大的改变。网络现在以卷积层开始,随后是一个池层,然后有是卷积层和一个池层,最后是两个完全连接的层。另一个区别是我们将输入缩放为255,而不是归一化它们。最后,我们训练25次。
一旦编译并运行,输出应该是这样的:
Network with 6 layers
Conv(dyn): 1x28x28 -> (8x5x5) -> SIGMOID -> 8x24x24
MP(2d): 8x24x24 -> (2x2) -> 8x12x12
Conv(dyn): 8x12x12 -> (8x5x5) -> SIGMOID -> 8x8x8
MP(2d): 8x8x8 -> (2x2) -> 8x4x4
Dense(dyn): 128 -> SIGMOID -> 150
Dense(dyn): 150 -> SOFTMAX -> 10
Total parameters: 21100
Dataset
Training: In-Memory Data Generator
Size: 60000
Batches: 600
Augmented Size: 60000
Testing: In-Memory Data Generator
Size: 10000
Batches: 100
Augmented Size: 10000
Train the network with "Stochastic Gradient Descent"
Updater: NADAM
Loss: CATEGORICAL_CROSS_ENTROPY
Early Stop: Goal(error)
With parameters:
epochs=25
batch_size=100
learning_rate=0.002
beta1=0.9
beta2=0.999
Epoch 0/25 - Classification error: 0.09392 Loss: 0.31740 Time 7298ms
Epoch 1/25 - Classification error: 0.07005 Loss: 0.23473 Time 7298ms
••••••
Epoch 24/25 - Classification error: 0.00682 Loss: 0.02327 Time 7335ms
Training took 186s
error: 0.01520
loss: 0.05183
这个网络性能比以前的网络好一点,在大约3分钟内达到1.52%的错误率。
如果你有兴趣,可以在Github信息库中找到更多的例子。
超高性能(重点)
我一直在做该库性能提升方面的工作。为了看看该库和其他流行的框架的差别,我决定比较DLL与TensorFlow,Keras,Torch和Caffe的性能。我也尝试过DeepLearning4J,但是我认为它的表现是相当差的,所以我放弃了。
我做的第一个实验是在MNIST数据集上训练一个三层的神经网络:
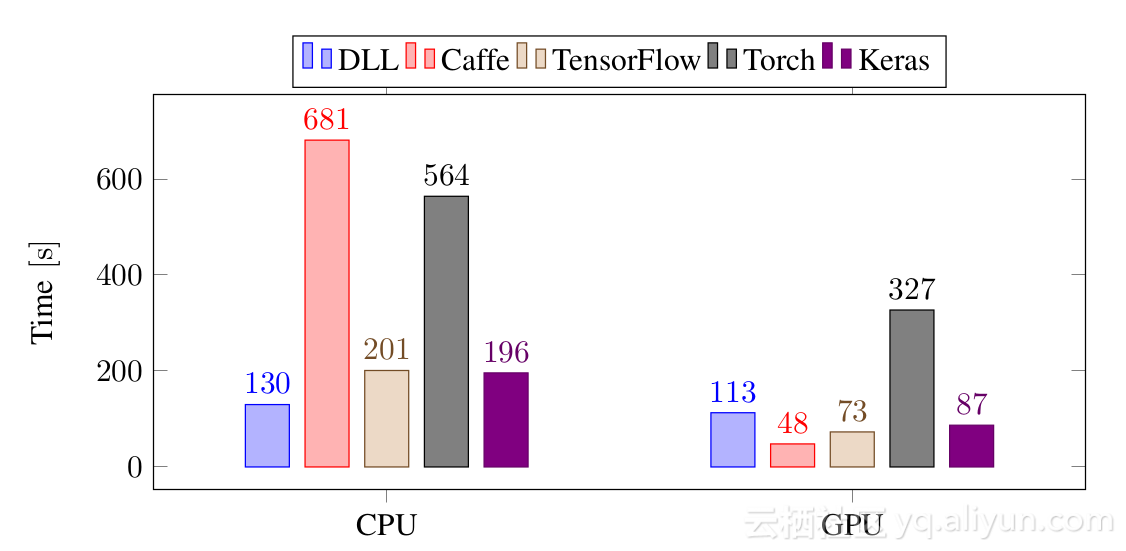
在CPU上,DLL是训练这个网络最快的框架,比TensorFlow和Keras快35%,比Torch快4倍,比Caffe快5倍。在GPU上,Caffe是最快的框架,其次是Keras和TensorFlow和DLL。
让我们来看看框架是如何与这些流行框架在一个小的CNN任务:
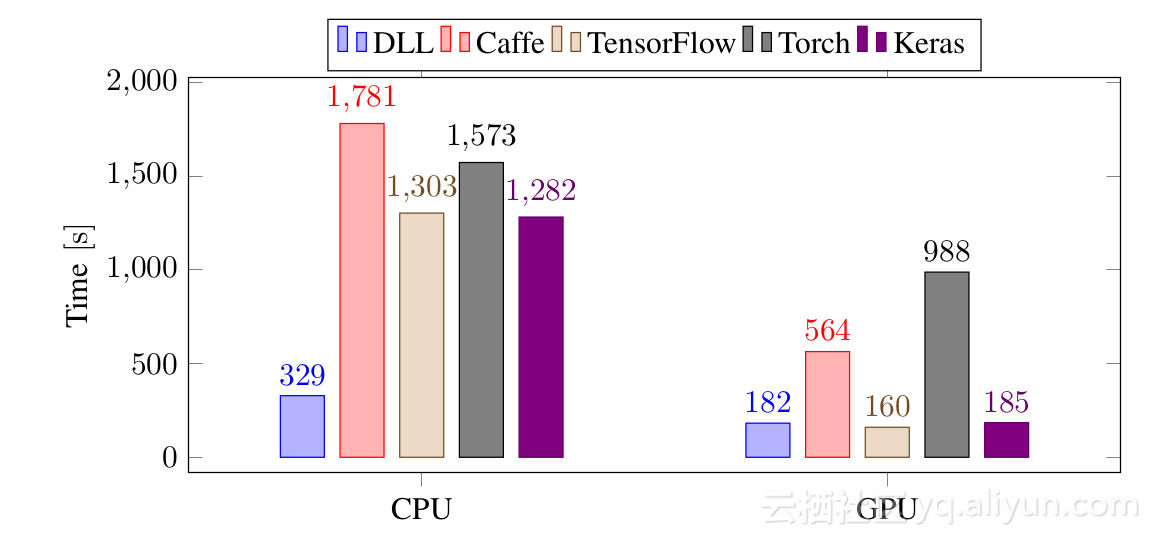
在CPU上,DLL是最快的框架,并且优势非常大,比TensorFlow和Keras快四倍,比Torch和Caffe快五倍。在GPU上,它与Keras和TensorFlow相当,比Caffe快3倍。
下一个测试是用较大的CNN在CIFAR-10上完成的:
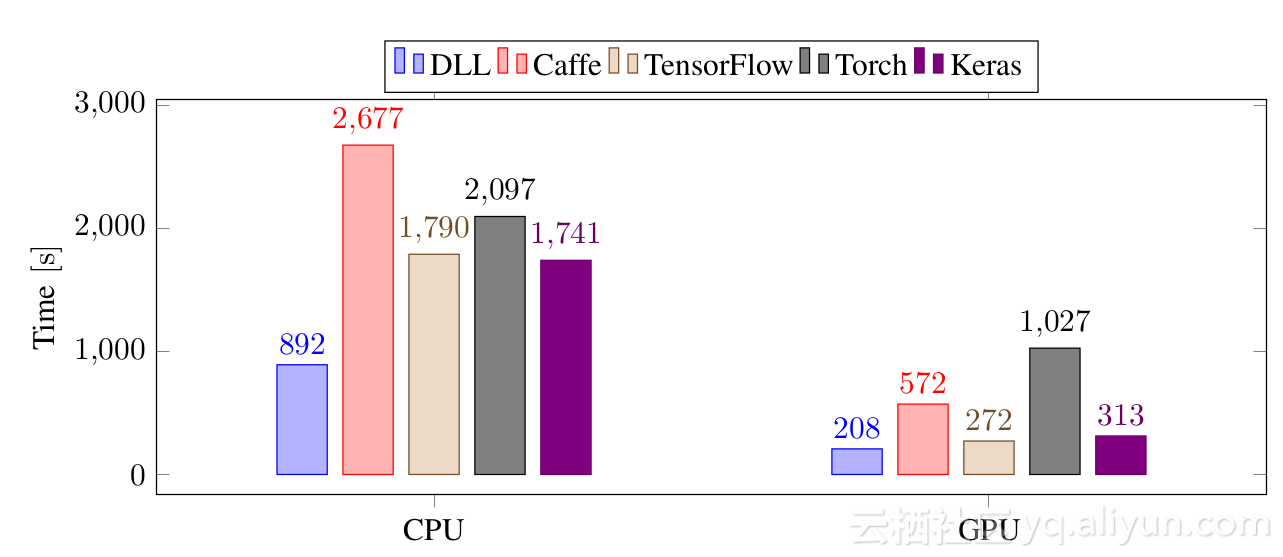
在这个更大的CNN上,差异不如以前那么令人印象深刻,但是,DLL仍然是CPU中最快的框架。它比TensorFlow,Keras和Torch还要快两倍,比Caffe快三倍。在GPU上,DLL比Keras和TensorFlow稍快,比Caffe快2.7倍,比Torch快5倍。
最后一次测试是在Imagenet上完成的,具有12层CNN。这一次,性能体现主要是在必要的时间训练了128个图像。
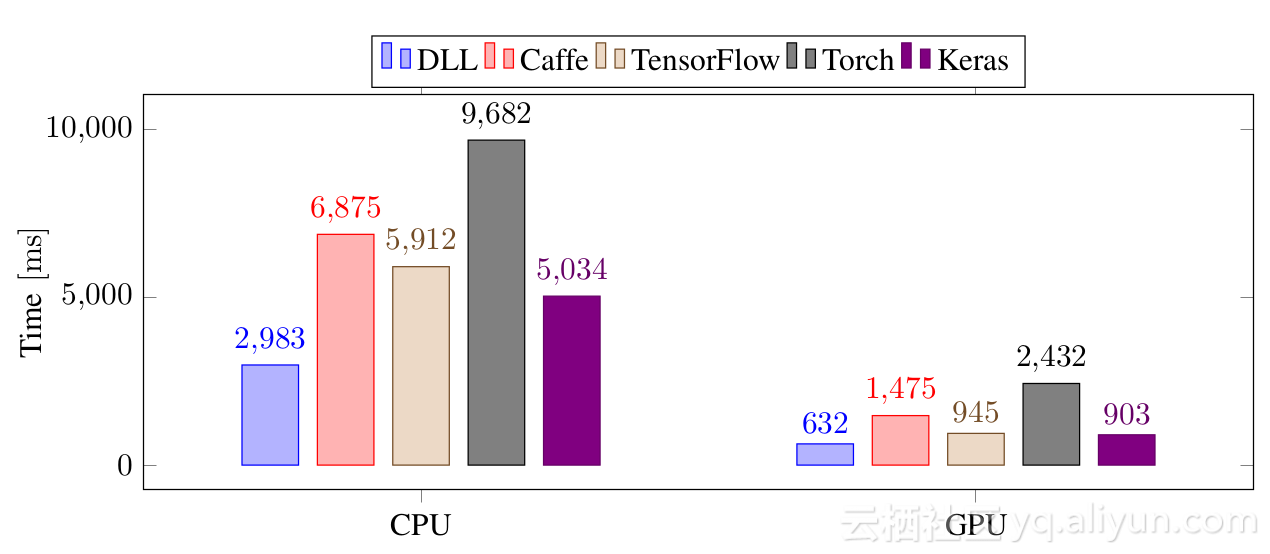
再次,DLL比CPU和GPU上的所有其他框架更快。DLL和TensorFlow和Keras之间的巨大差异主要是由于从Python代码读取Imagenet图像的性能差,而代码在DLL中进行了优化。
总的来说,在所有测试实验中,DLL总是CPU上最快的框架。在GPU上,除了一个非常小的全连接网络,它也是比TensorFlow和Keras快。
如果你有兴趣,可以查找这些实验的代码。
未来在哪里?
我不知道下一个版本的DLL将包含什么,但我知道我将要开发的方向。我想使用DLL来分类文本。第一次打算,我计划增加对文本嵌入学习的支持,并能够在嵌入之上使用CNN,希望这不会花太长时间。第二次打算,我希望将支持循环神经网络(RNNs)纳,以及增加对LSTM和GRU单元的支持,这可能会需要一些时间。
虽然该框架性能表现已经相当不错了,但还有一些事情要改善。现在有些操作在GPU上实现时并不高效,例如Batch Normalization and Dropout。我想保证所有的操作都可以在GPU上进行有效的计算。还有一些在CPU上效率不高的情况,例如,批处理标准化目前很差。一些SGD优化器,如Nadam也很慢。
下载DLL
你可以在Github上下载DLL 。如果你只对1.0版本感兴趣,可以查看 版本页面或克隆标签1.0。有几个分支:
1.master是前进的发展分支,可能是不稳定的。
2.stable分支总是指向最后一个标签,这里没有开发。
对于文档,这是关于这个框架迄今为止最好的文档是可用的示例。你还可以查看使用库的每个功能的测试源。
如果你对此图书馆有任何意见或任何问题,请随时给予评论。如果你在使用此库时遇到问题,或者如果你想对该库有所贡献,请及时与我联系我期待你的到来。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题:《deep-learning-library-1.0-fast-neural-network-library》
作者:Baptiste Wicht
现年28岁。我是弗里堡大学应用科学大学计算机科学博士生,主要从事机器学习。目前,主要从事开发C ++高性能应用程序。
Twitter:@wichtounet
LinkedIn:我的LinkedIn个人资料
译者:袁虎,审校:
文章为简译,更为详细的内容,请查看原文
