最近读了阿里的《大数据之路-阿里巴巴大数据实践》,对于其机器学习平台也蛮感兴趣,正好阿里出了本新书《解析阿里云机器学习平台》,顺便读了下,感触也不少,结合最近团队机器学习的一些思考,特别在此分享于你。

一、机器学习的门槛降得更低了
这本书的第一章是这么描述阿里云机器学习平台的,“阿里云机器学习平台是构建在阿里云MaxCompute计算平台之上,集数据处理、建模、离网预测、在线预测为一体的机器学习算法平台,用户通过拖曳可视化的操作组件来进行试验,使得没有机器学习背景的工程师也可以轻易上手玩转数据挖掘。”
这说得对也不对,对的是机器学习平台的易用性的确很重要,不对的是机器学习平台只解决功能性问题,数据挖掘其实大多时候是在做业务分析、处理数据和分析数据,而不是选择算法和跑通流程,再便捷的可视化平台对于降低机器学习的成本还是非常有限的,否则,要那么多数据建模师干嘛?
相对于SASS,SPSS等,阿里云机器学习平台在易用性、算法完整性及数据处理上是有其特点的,甚至是有一些优势的,因为它有MaxCompute平台的背书,笔者相信任何企业的业务人员只要懂点基本的数据概念,上手这个平台是非常容易的,体现了阿里云机器学习平台在企业级市场的雄心。
怎么个使用简便法呢?看下面一张示意图,任何的机器学习都采用简单的流程就可以描述出来,步骤清晰而简洁,大多非常雷同。
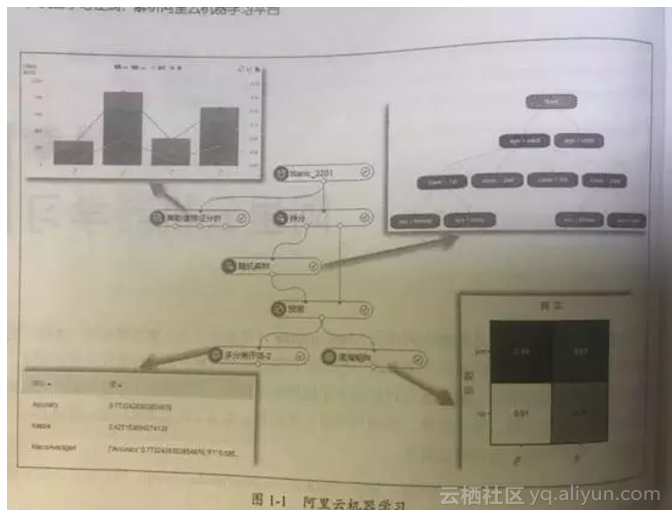
(1)离散值特征分析:就是分析离散变量与标签的关系,阿里云提供了很多变量分析方法,诸如直方图啥的
(2)拆分:就是将数据集拆分为训练和测试集
(3)随机森林:就是选择的算法,我看了下,包括逻辑回归、朴素贝叶斯、逻辑回归、GBDT、文本分析(比如LDA),协同过滤等大多算法,还支持TensorFlow,但只是打个包
(4)预测:就是用测试集数据进行验证
(5)评估:就是ROC,AUC诸如此类的传统评估方法
所有操作基本都是拖曳和配置,比较方便,对于不懂机器学习的人来讲,可以通过这个平台理解机器学习整体的流程,入门是相当的好,即使对于懂机器学习的人,也有助于开阔视野,加速自己的模型验证过程。
二、业务人员迎来新的机会
笔者以前提过,要做好数据挖掘,首先要有一定的业务积淀,这样做成的数据模型才可能有效, 数据挖掘中业务理解和数据准备占据70%以上的时间,外来和尚无法念好经往往不是算法不行,而是业务和数据理解力不行,因此,精通业务的人员其实至少已经是半个专业数据挖掘师了。
业务人员缺的倒是一些IT技能,以往这剩下的30%并不容易掌握,比如业务人员搞个逻辑回归可能还要学习一下语言,这个挑战还是比较大的,现在在这类易用的机器学习工具帮助下,他有可能基于丰富的业务经验让数据分析达到一个新的阶段。
当前在一些企业内部分业务人员已经开始自行进行取数,分析及挖掘了,但大多数企业仍然走的是取数流程或项目的方式,这个争议还是比较大的,但笔者相信,随着大数据应用的深入,由于其天生的创新性、迭代性的要求可能会引导业务人员逐步转型,或者组织上进行大的调整,比如数据挖掘师直接归属到业务部门。
IT人员则要专注于研发和改进诸如机器学习平台等中台类的工作,提升平台的体验,千方百计让业务人员用好这些平台,这也许是未来IT正确的姿势,也是双赢的局面。
现在很多企业的IT人员在从事数据挖掘、取数等工作,其处于IT,数据和业务的中间地带,从效率的角度讲,划到业务部门也未尝不可。
三、数据仓库建模师的机会
笔者相信未来这种易用型的机器学习平台将越来越多,意味着通用算法这部分技能行业门槛变得很低,仅仅懂几个算法的工程师在企业内的价值会贬值。
机器学习算法门槛的降低变相的提升了数据仓库建模师的价值,随着机器学习需求的增加,机器学习前期的数据理解、数据清洗和数据准备变得更为重要,谁能深入的理解业务,设计出好用的数据挖掘中台数据模型(这里的数据模型类似数据仓库建模),将极大降低数据挖掘的成本。
以前搞数据挖掘的数据中台其实笔者并不赞成,现在还是觉得有一定必要性了,一个当然是机器学习需求增长,数据中台的共享价值体现出来了,另一个则是当前的数据仓库模型并不能很好的支撑很多数据挖掘场景,团队的数据挖掘师各自为战,好的变量设计无法沉淀。
以下是阿里的关于电商购买预测中数据准备的一个案例,我觉得是需要有业务和数据经验的人体系化的去设计的,靠个人临时去准备一方面代价太大,另一方面也想不全面。
影响某个用户对某个品牌是否购买的特征有哪些呢?
首先是用户对品牌的关注,譬如:点击、发生过购买行为,收藏和假如过购物车,而在这些因素中,关注的行为离现在越近,即将购买的可能性就越大,所以我们会关注最近3天、最近一周、最近1个月、最近2个月、最近3个月和有记录的所有时间的情况,于是有了如下一些特征。
-
最近3天点击数、购买数、收藏数和加入购物车次数
-
最近1周点击数、购买数、收藏数和加入购物车次数
-
最近1个月点击数、购买数、收藏数和加入购物车次数
-
最近2个月点击数、购买数、收藏数和加入购物车次数
-
最近3个月点击数、购买数、收藏数和加入购物车次数
-
全部点击数、购买数、收藏数和加入购物车次数
有了关注时间段细分的关注次数还不够,还希望知道该数值的变化率,来刻画该关注的持续程度,我们还可以构造如下特征:
-
最近3天点击数变化率(最近3天点击数/最近4-6天点击数)、购买数变化率、收藏数变化率、加入购物车次数变化率
-
最近1周点击数变化率(最近1周点击数/上周点击数)、购买数变化率、收藏数变化率、加入购物车次数变化率
-
最近1月点击数变化率(最近1月点击数/上月点击数)、购买数变化率、收藏数变化率、加入购物车次数变化率
如果用户对该品牌曾有过购买行为,我们希望了解,通过多少次点击产生了一次购买,多少次收藏转化为一次购买,即购买转化率,构造特征如下:
-
最近3天点击转化率、收藏转化、加入购物车转化率
-
最近1周点击转化率、收藏转化、加入购物车转化率
-
最近1月点击转化率、收藏转化、加入购物车转化率
-
整体点击转化率、收藏转化、加入购物车转化率
其次,我们将注意力放在用户上,需要构造特征将用户的特点表现出来,重点是该用户对其关注的所有品牌的总体行为,用户最近对所有品牌的关注度,有如下特征:
-
最近3天点击数、购买数、收藏数和加入购物车次数
-
最近1周点击数、购买数、收藏数和加入购物车次数
-
最近1个月点击数、购买数、收藏数和加入购物车次数
-
最近2个月点击数、购买数、收藏数和加入购物车次数
-
最近3个月点击数、购买数、收藏数和加入购物车次数
-
全部点击数、购买数、收藏数和加入购物车次数
-
最近3天点击转化率、收藏转化、加入购物车转化率
-
最近1周点击转化率、收藏转化、加入购物车转化率
-
最近1月点击转化率、收藏转化、加入购物车转化率
-
整体点击转化率、收藏转化、加入购物车转化率
最后,单独看品牌这个因素的影响,有的热门品牌,关注度很高,而我们更关心其近期的情况,有如下特征。
-
最近3天被点击数、被购买数、被收藏数和被加入购物车次数
-
最近1周被点击数、被购买数、被收藏数和被加入购物车次数
-
最近1月被点击数、被购买数、被收藏数和被加入购物车次数
-
最近3月被点击数、被购买数、被收藏数和被加入购物车次数
-
全部被点击数、被购买数、被收藏数和被加入购物车次数
-
最近3天点击转化率、收藏转化、加入购物车转化率
-
最近1周点击转化率、收藏转化、加入购物车转化率
-
最近1月点击转化率、收藏转化、加入购物车转化率
-
整体点击转化率、收藏转化、加入购物车转化率
综上,某个用户对某个品牌是否购买的特征由刻画该用户对该品牌关注的各种特征,描述该用户的特征,以及描述该品牌的特征共同构成。
这么复杂的特征变量设计不应该每次做机器学习的时候去生成,而应该沉淀下来,其实每个企业都有类似的场景,但我们在做特征设计的时候,往往难以考虑的这么周全,想到哪做到哪,这体现出了数据挖掘数据中台的价值。
四、机器学习工程师价值的思考
读完阿里这本书,虽然更像是在看一本机器学习平台的说明书,也许专业人士会觉得LOW,但笔者是能体会到其在平台易用性上花的功夫的,团队也在做类似的一些事情,但还是有很大差距的,做了就知道了。
这本书引发的数据挖掘中台思考,也是不经意看案例时体会到的,企业实践的东西有这个好处,它在说一个事情,但过程却透露了很多实践的秘密,类似的东西还要很多,比如逻辑回归变量重要性的判断,我以前一直理解有误,比如特征哑元化的使用场景,比如KNN和随机森林在一些场景的表现,又如LDA的解释,由于案例放在那里,你很容易感性的得到理解,还有GBDT,笔者以前没听说过,团队说要用这个算法的时候,当时是一脸懵逼。
这周在与成员回顾某个数据挖掘的过程中,成员提到将矩阵算法换成GBDT时候付出了很大的代价,持续了很长时间,但效果提升了一点点,笔者也只能惭愧的笑笑了,要为自己的无知付出代价。
很多时候数据挖掘师很努力,但成果寥寥,我觉得最大问题是不理解客户的最终诉求,视野窄了,把算法当成了结果,数据挖掘师经常说案头苦干了1个月,XX算法提升了XX个点,非常不错,我说,到底带来了多少收入和用户?
其实不同企业的情况不同,在腾讯将推荐算法提升平均1个点当然是牛逼,但在我这个企业内,也许毫无价值,大家的起点完全不同。
其实作为客户,也根本不关注手段,要的就是效果,手段能简化就简化,用一个新数据往往好过新算法,以最低的代价获得最大的收益就是要做的事情,阿里云机器学习平台就是希望降低那个30%的成本时间,但也仅此而已。
未来是人工智能的时代,人工智能也在逐步平台化,今天你说掌握个深度学习好像还很先进,但被集成后就大幅贬值了,只有差异化才有价值,现在TensorFlow技术文章其实还不多,我们在试用TensorFlow On Spark的时候进度偏慢,这个时候你懂就有价值。
未来也许只有三类机器学习工程师有前途,一类是能改进和创造新的算法的,这是算法大师,二是做机器学习平台的,含功能,算法和数据,这是产品大师,三是能够深刻理解客户需求的,在某个行业有足够业务和数据底蕴,因此能够利用高效的平台工具创造价值的,这是应用大师。
有机会,你也可以去读读这本书。
阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……