随着移动互联网的快速发展,数据量急剧膨胀,新经济模式下,如何从积累的海量数据中挖掘出新的价值,支撑企业及社会发展,是当前大数据大热的内在驱动力。大数据应用所需要的IT设施的计算资源、存储资源越来越大,但目前很多处于探索期的大数据应用能否最终挖掘出价值也需持续的投入与不断尝试,如何以更快、更省的方式捕捉到大数据的业务商机,是大数据应用企业不得不考虑的现实问题。
大数据应用一般采用Hadoop数据库,主要得益于其在数据提取、转换和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,其最核心的设计就是分布式文件系统(Hadoop Distributed File System,简称HDFS)和MapReduce。HDFS为海量的数据提供了分布式存储,则MapReduce为海量的数据提供了分布式计算。Hadoop实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到HDFS里,从而充分利用云化的计算与存储资源,高效完成大数据应用中的业务逻辑处理流程。
TPCx-BB基准测试
TPCx-BB是国际标准组织TPC制定的衡量基于Hadoop的大数据系统的性能基准测试标准TPC Benchmark Express-BigBench的简称,华为香农实验室得益于DC3.0项目积累的丰富大数据底层技术及应用研究经验,是此标准的重要贡献者之一,也是唯一参与此标准制定的中国公司。此性能测试指标排名在工业和商业领域中具有很大的影响力。
TPCx-BB测试通过模拟零售商的30个应用场景,执行30个查询算法来衡量基于Hadoop大数据系统的服务器软硬件性能,其中一些场景还用到了当前热门的机器学习算法,如K-Means、Naive Bayes等。TPCx-BB的测试结果,可以全面准确的反映大数据系统端到端的整体运行性能。
TPCx-BB测试的负载特征:
l涉及结构化、半结构化和非结构化数据类型;
l30项用例模拟,大数据处理、分析与报表生成;
l包含短时间(数秒)与长时间(数小时)的大数据任务运行;
l多种数据集规模的灵活扩展;
l并行线程支持不同特点的多个Job运行在单个集群上并支持节点扩展;
l性能和价格指标提供了有意义的性能与成本洞察;
l支持基于MapReduce、Spark及Tez的Hive的灵活性并扩展覆盖未来其他框架。
TPCx-BB测试结果评估指标:
lBig Bench 每分钟查询 (BBQpm),该指标反映了在三个测试阶段(负载测试、能力测试、吞吐量测试),并行运行多个作业测试出的大数据应用集群的性能效率。
l价格性能比(Price/BBQpm),该指标反映了取得单位性能的成本投入,主要衡量的是性价比。
华为FusionServer 2288H V3测试情况
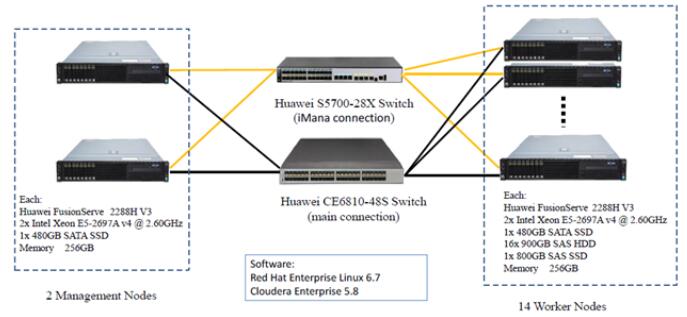
此次华为FusionServer 2288H V3重点参与了TPCx-BB@3000的测试(3000表示测试数据量为3TB),组网图见上。具体测试结果如下:
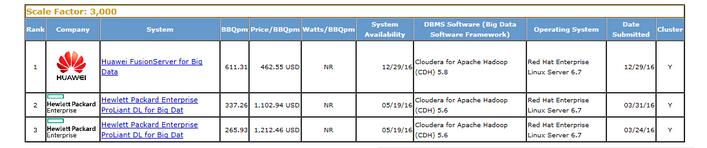

详细测试数据可以访问如下TPC官方网站进行查询了解:
http://www.tpc.org/tpcx-bb/results/tpcxbb_perf_results.asp
通过此次测试结果可以看到,华为FusionServer 2288H V3在基于Hadoop的大数据应用中,性能及性价比在2路x86机架服务器中处于领先地位,显示出了华为服务器强大的硬件性能及出色的软硬一体化调优能力。华为近期推出的可支持12及24个NVMe SSD硬盘的2288H V3的升级版,进一步突破服务器的IO性能瓶颈,提升了服务器的整体性能。华为FusionServer 2288H V3是互联网、电信、金融、能源等行业构建大数据应用计算平台的最佳选择。
华为FusionSever服务器
- 高性能
华为FusionServer 2288H V3,配备2颗英特尔®至强™E5-2600 v3/v4系列CPU,最大单处理器可达22核,提供强大的计算性能;支持24条DDR4内存插槽及4/12/24个NVMe SSD硬盘;支持16个3.5英寸或28个2.5英寸硬盘的超大本地存储空间。
- 高可靠
华为FusionServer服务器元器件采用降额设计,独特高效散热设计,严苛测试流程,保障极限情况下设备可靠性,实现40℃环温长期稳定运行,同时整体故障率低于业界15%。
- 高能效
在能耗管理上,采用华为特有DEMT动态能耗管理技术,96%转换效率的钛金电源,实现精确的处理器功耗管理、风扇调速等电源管理技术,毫瓦必省。
- 管理便捷
华为FusionServer服务器同时提供方便快捷的管理和维护,独立的iBMC管理模块提供SOL、远程KVM、远程开关机等管理功能及uMate等批量运维工具,易于管理。
根据Gartner的统计数据,截至2016年第3季度,华为服务器出货量排名全球前三(不含塔式),增长率全球第一。华为服务器已服务于全球超过5000家客户,涵盖政府及公共事业、互联网、电信、能源、金融、交通、医疗、教育、媒资、制造等行业。
原文发布时间为: 2017年2月10日
本文来自云栖社区合作伙伴至顶网,了解相关信息可以关注至顶网。

