从你的应用中收集数据有时候可能有点困难和艰辛。可能是缺少一个必须的API,或者是有太多的数据需要处理。这时候你就需要借助于web抓取。
不用说了,这可能是个法律雷区,所以要确保你没有逾越法律的边界。
目前有很多工具可以帮助你抓取内容,例如Import.io,但是有时这些工具并不能完全满足你的需要。又或者,像我一样,充满好奇心,希望深入地了解web抓取。
挑战
让我们从一个简单地挑战——网络爬虫开始,让这个爬虫爬取Techmeme,并获得一个当天热门新闻列表!
注意: 在这里我将会使用DZone,但在获取页面时会出现问题。后面会详细说明这个问题。
机器设置
您只需要做很少的工作来完成安装。我假设您已经安装了Node.js(我的意思是谁没有安装呢!)。尽管我们并不直接使用PhantomJS,但是您依然需要安装它。版本2.0.1目前已经可以使用了——您可以从其官网下载或使用homebrew或其他等效的包管理器安装。
如果您使用具有homebrew的Mac,您可以这样安装PhantomJS
brew install phantomjs
下载完成之后,您将需要用相同的方式安装CasperJS。您可以将CasperJS看做PhantomJS的伴侣。它实际上是给您提供相似的网页处理API。尽管它是为网页测试设计的。与PhantomJS相同,它具有丰富的功能使其也非常适合于抓取内容。
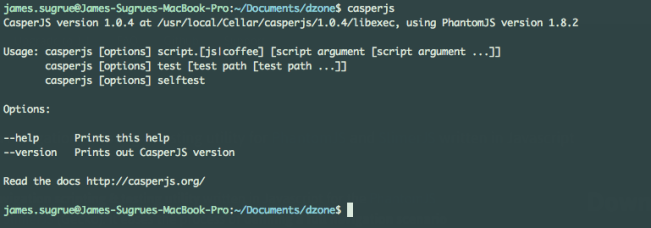
CasperJS允许我们编写JavaScript脚本。您可以通过在终端中输入casperjs以测试其是否正确安装并加入到PATH中。
编写脚本
下面我们将编写一个新的JavaScript脚本文件。在我的例子中,我称其为index.js。您需要做的第一件事就是在您的代码中创建一个casper实例。您还需要加入依赖的模块并向其传递一些基本参数。
- var casper = require("casper").create({
- waitTimeout: 10000,
- stepTimeout: 10000,
- verbose: true,
- pageSettings: {
- webSecurityEnabled: false
- },
- onWaitTimeout: function() {
- this.echo('** Wait-TimeOut **');
- },
- onStepTimeout: function() {
- this.echo('** Step-TimeOut **');
- }
- });
当您等待一个元素可见时,上面的onWaitTimeout回调将会被调用。例如,点击一个按钮之后,waitTimeout将被超出。
现在,您可以启动casper实例并将其指向我们希望爬取的页面。
- casper.start();
- casper.open("http://techmeme.com");
Casper使用一个可靠地框架来帮助您一步一步地运行所有任务。对于第一步,您将希望使用then函数。
- casper.then(function() {
- //logic here
- });
- //start your script
- casper.run();
为了使Casper打开网页并按您的想法运行,您需要调用run函数。
检查网页以获取想要的元素
当抓取到一个网页,您可以假设它具有特定的结构。在您编写脚本之前,可能已经浏览过了网页的源代码,或者已经使用开发者工具观察了页面对特定行为的变化。
所以,让我们开始于一个简单地逻辑,使用CasperJS维护系统确保一个特定的元素在继续之前处于合适的位置。如果元素不存在,脚本将会停止,但 是至少您将会知道其为何停止。这个维护行为对于观察您之前抓取页面的变化是无价的,但是可能会与您之前见到的页面具有不一样的结构。
如果您检查了Techmeme首页的元素,您将会注意到头条新闻部分在一个id为,topcol1的div中。
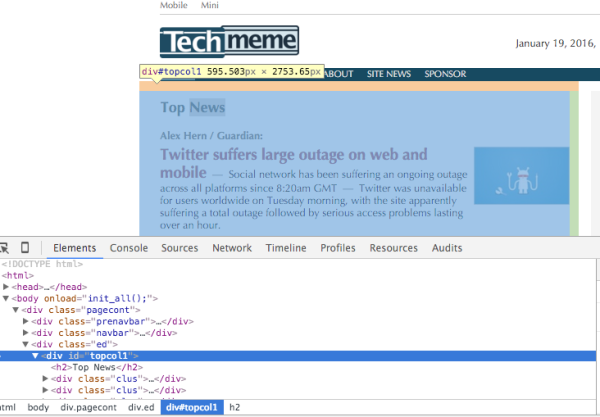
让我们使用维护功能确保这个元素存在:
- casper.then(function() {
- this.test.assertExists("#topcol1");
如果这个元素不存在,测试(例如我们的脚本)将会停止,否则它将继续运行。
您还可以使用waitForSelector函数来获得更为细致的结果:
- this.waitForSelector("#topcol1",
- function pass () {
- console.log("Continue");
- },
- function fail () {
- this.die("Did not load element... something is wrong");
- }
- );
使用这个函数的优点就是它允许页面加载元素并一直等待到执行。您在初始配置中指定的waitTimeout将会被用于确定失败前等待多久。
注意:有时,使用CasperJS查找元素可能会出问题。使用capture()函数截取一个CasperJS看到的页面的截图。
this.capture(‘screener.png’);
从页面中提取内容
下面,让我们看看怎样从页面中找出标题。首先,找到包含您需要的内容的元素,在我们的例子中,为class=ii的div。
CasperJS自带一个evaluate函数,可以让您在页面中运行JavaScript,并且您还可以让函数返回一个值以供进一步处理。
这个JavaScript写起来并没有什么不同,您可能注意到,在本例中,我使用的是原始的纯DOM方法,而不是jQuery,同样,如果您愿意,您也可以在evaluate函数中使用jQuery;
- var links = this.evaluate(function(){
- var results = [];
- var elts = document.getElementsByClassName("ii");
- for(var i = 0; i < elts.length; i++){
- var link = elts[i].getElementsByTagName("a")[0].getAttribute("href");
- var headline = elts[i].firstChild.textContent;
- results.push({link: link, headline: headline});
- }
- return results;
- });
如果您在evaluate函数中使用console.log语句,它们将会通过remote.message句柄打印到您的控制台,这将会在下一节中详细介绍。
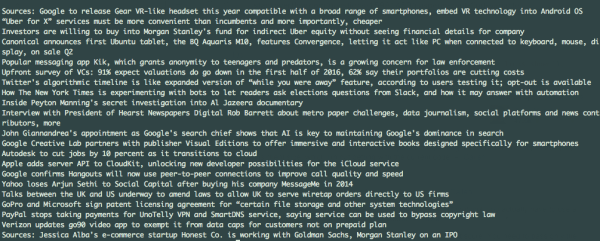
一旦运行结束,结果将会返回给您。您可以将它们写入文件系统,或者将它们打印到屏幕上:
- console.log("There were " + links.length + " stories");
- for(var i = 0; i < links.length; i++){
- console.log(links[i].headline);
- }
输出的结果如:
抓取中的错误处理
有时,您运行的JavaScript中可能存在错误,或者其对您抓取的页面的处理存在问题。这些情况中,您可以捕获错误并使用remote.message和page.error事件将其打印到控制台:
- casper.on('remote.message', function(msg) {
- this.echo('remote message caught: ' + msg);
- });
- casper.on('page.error', function(msg, trace) {
- this.echo('Error: ' + msg, 'ERROR');
- });
- 您同样还能观察到即将请求的资源,这些资源的加载使用的是resource.error和resource.received事件:
- casper.on('resource.error', function(msg) {
- this.echo('resource error: ' + msg);
- });
- casper.on('resource.received', function(resource) {
- console.log(resource.url);
- });
了解更多
本文只写了点关于使用CasperJS你所能做到的皮毛的东西。该项目的文档是完美的,所以要确保查看过 API ,看看你还可以用它来做些什么。
在本系列的下一篇文章中,我回来看看如何从网页上下载图片,而且我也会讨论下如何使用构建到CasperJS中的文件系统函数,其使用会受到比Node.js更多的限制。
来源:51CTO


