作为 SVDS 研究团队的成员,我们会经常接触各种不同的语音识别技术,也差不多见证了语音识别技术近几年的发展。直到几年之前,最先进的语音技术方案大多都是以语音为基础的(phonetic-based),包括发音模型(Pronunciation models),声学模型(Acoustic Modelling)和语言模型(Language Model)等。通常情况下,这些模型大多都是以隐马尔可夫模型(HMM)和 N-gram 模型为核心的。未来,我们希望以这些传统模型为基础,探索一些诸如与百度 Deep Speech 等最新的语音识别系统相结合的新技术。当然,目前互联网上可以找到许多针对这些基础模型进行解释、汇总的文章和资料,但针对它们之间的差别和特点展开阐述的却并不多。
为此,我们对比了五款基于 HMM 和 N-gram 模型的语音识别工具:CMU Sphinx,Kaldi,HTK,Julius 和 ISIP。它们都是开源世界的顶级项目,与 Dragon 和 Cortana 等商业语音识别工具不同,这些开源、免费的工具可以为开发者提供更大的自由度以及更低的开发成本,因此在开发圈始终保持着强大的生命力。
需要提前说明的是:以下分析大多来源于我们的主观经验,同时也参考了互联网上的其他信息。而且这篇文章也并非一个覆盖所有语音识别开源工具的汇总类文章,我们只是对比了其中五款相对更主流的产品。另外,HTK 并不是严格开源的,它的代码并不能重新组织发布,也不能用于商业用途。
想知道更多语音识别工具的用户请点击以下链接,其中列出了几乎所有开源/非开源的语音识别工具,非常全面。
https://en.wikipedia.org/wiki/List_of_speech_recognition_software

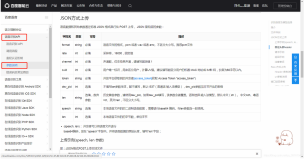
编程语言:
根据你对不同编程语言的熟悉程度,你可能会更偏爱某一种工具。如上图所示,这里列出的五款工具中,除了 ISIP 只支持 C++ 之外,全都支持 Python。你可以直接在它们的官网找到不同语言对应的下载链接。不过,Python 版有可能并不会覆盖工具包的全部功能,有些功能还可能是为其他语言的特性单独设计的。另外值得注意的是,CMU Sphinx 还支持 Java、C 和其他更多语言。
开发者活跃度:
这里列出的五个项目均源于学术研究。
从名字也能看出,CMU Sphinx 是一款源于卡内基梅隆大学的产品。它的研发历史大约可以追溯到 20 年前,目前在 GitHub 和 SourceForge 平台同步更新。在 GitHub 平台有 C 和 Java 两个版本,而且据说分别只有一个管理员维护。但在 SourceForge 平台却有 9 个管理员和十几个开发者。
Kaldi 源于 2009 年的一场研讨会,代码目前在 GitHub 平台开源,共有 121 位贡献者。
HTK 始于 1989 年的剑桥大学,曾一度商业化,但目前又回归剑桥。如前所述 HTK 现在并不是一款严格意义的开源工具,而且更新缓慢(虽然它的最新版本更新于 2015 年 12 月,但前一个版本的更新时间却是 2009 年,中间隔了差不多 6 年时间)。
Julius 始于 1997 年,最后一个主要版本更新于 2016 年 9 月,据称其 GitHub 平台有三名管理员维护。
ISIP 是第一个比较先进的开源语音识别系统,起源于密西西比州。它主要在 1996 年到 1999 年之间研发,最后一个版本发布于 2011 年,在 GitHub 平台出现之前就已经停止更新了。

社区活跃度:
这一部分我们考察了上述五个工具的邮件和社区讨论情况。
CMU Sphinx 的论坛讨论热烈,回帖积极。但其 SourceForge 和 GitHub 平台存在许多重复的 repository。相比之下,Kaldi 的用户则拥有更多交互方式,包括邮件、论坛和 GitHub repository 等。HTK 有邮件列表,但没有公开的 repository。Julius 官网上的论坛链接目前已经不可用,其日本官网上可能有更详细的信息。ISIP 主要用于教育目的,其邮件列表目前已不可用。
教程和示例:
CMU Sphinx 的文档简单易读,讲解深入浅出,且贴近实践操作。
Kaldi 的文档覆盖也很全面,但是在我看来更难理解。而且,Kaldi 同时包括了语音识别解决方案中的语音和深度学习方法。
如果你并不熟悉语音识别,那么可以通过对 HTK 官方文档(注册后可以使用)的学习对该领域有一个概括的认识。同时,HTK 的文档还适用于实际产品设计和使用等场景。
Julius 专注于日语,其最新的文档也是日语,但团队正在积极推动英文版的发布。
以下链接提供了一些基于 Julius 的语音识别样例。
https://github.com/julius-speech/dictation-kit
最后是 ISIP,虽然它也有一些文档,但是并不系统。
预训练模型:
即使你使用这些开源工具的主要目的是想要学习如何去训练一个专业的语音识别模型,但一个开箱即用的预先训练好的模型仍然是一个不可忽略的优点。
CMU Sphinx 包括英语、法语、西班牙语和意大利语在内的诸多可以直接使用的模型,详情可以参考它的说明文档。
Kaldi对现有模型进行解码的指令深藏在文档中,不太容易找到,但我们仍然发现了贡献者在 egs/voxforge 子目录下基于英文 VoxForge 语料库训练好的一个模型,并且还可以通过 online-data 子目录下的一个脚本直接运行。详情可以参考 Kaldi 项目的 repository。
我们没有深入挖掘其他三个软件包的模型训练情况,但它们应该至少包含一些简单可用的预训练模型,而且与 VoxForge 兼容(VoxForge 是一个非常活跃的众包语音识别数据库和经过训练的模型库)。
未来我们将陆续推出关于 CMU Sphinx 具体应用和如何将神经网络应用于语音识别的更多文章,欢迎大家继续关注。