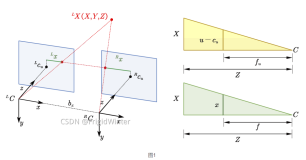
3.5 从深度图像到骨骼图
现在Kinect通过红外摄像头已经可以看到三维的世界了,下一件事就是分辨出视野中可能是人体的移动物体,就像人眼下意识地聚焦在移动物体上。
这个过程非常重要,下面重点探讨如何从深度图像生成骨骼图,从而使游戏中的Avatar和你的身体动作一致,如图3-33所示。
3.5.1 动静分离,识别人体
识别人体的第一步是从深度图像中将人体从背景环境中区分出来,这并不简单。
在介绍原理前,我们不妨来看一个天文观察问题。夏威夷风光迤逦,景色迷人,诸多星罗棋布的海岛中有座叫莫纳克亚的山峰,堪称世界上独一无二的天文观测点 — 那里远离城市,没有光源污染,天空处于极度黑暗的状态,可以观测到宇宙最边缘的微小星系,为全世界天文学家所青睐。足够黑是天文观测的一个必备条件。从技术的角度来说,当你看到群星璀璨的时,天空大多数的像素都是黑色的。但如果你是一名天文爱好者,同时生活在上海,你想观测的星云都淹没在霓虹灯下了。中科院上海天文台就已从佘山迁移到浙江安吉的天荒坪,那里夏季可以清晰地看见银河。
正如城市被光源污染的天空,Kinect的视野也不是像好莱坞动作捕捉工作室那样的绿色幕布背景。要能分辨出活动的人体,也面临着一些干扰,比如你身后的沙发、椅子、书架或者环绕音响。这是一个从噪声中提炼有用信息的过程,从某种意义上来说,红外摄像头就是我们的“望远镜”。
Kinect会对景深图像进行“像素级”评估,评估过程和人眼看物体的过程差不多一样,先看清轮廓,再看细节。这一环节中,输入的是深度图像,输出的是目标人体轮廓。再次强调“深度”,因为其环境光照无关性,其可以获得比彩色图像更小的噪声。
Kinect系统如何基于深度数据来做判断人体轮廓呢?
首先分析比较接近Kinect的区域,这也是最有可能是“人体”的目标。前面我们已经穿插过一段题外话:任何“大”字形的物体都有可能被Kinect for Xbox跟踪为“玩家”。
其次会逐点扫描这些区域深度图像的像素,来判断属于人体的哪些部位。当然,这一过程为计算机图形视觉技术,包括边缘检测、噪声阈值处理、对人体目标特征点的“分类”等环节。通过这一技术最终将人体从背景环境中区分出来。
边缘检测可以被定义为在局部区域内图像特性的差别,它表现为图像上的不连续性(如表现在图像上灰度级的突变,纹理结构的突变以及彩色的变化等)。目标特征点提取中所谓的物体特征点通常指的是角点、特定灰度值点、特征向量、特征线段等。
Kinect可以主动追踪最多2个玩家的全身骨架,或者被动追踪最多6名玩家的形体和位置。在这一阶段,通过约定的字节编码,系统为每个被追踪的玩家在深度图像中创建了所谓的“分割遮罩”,这是一种将背景物体(比如椅子和宠物等)剔除后的用户深度图像。并在后续的处理流程中仅仅传送这部分数据,从而降低计算压力,如图3-34、图3-35所示。

提示 更多细节推荐访问微软研究院的网站,阅读Jamie Shotton发表的Object recognition and segmentation in photos,以及Jamie Shotton和Alex Kimpman等人联合发表的重要论文Real-Time Human Pose Recognition in Parts from Single Depth Images,后面还会继续分析这篇重要论文,来帮助大家理解原理。
如果你去关注计算机视觉领域的相关技术,很多文章都会描述“Classification”(分类)这一主题,包括如何进行像素扫描、特征提取、区域分割等。这是一个重要的技术环节,也有很多有趣的做法,比如“通过计算机视觉的方法来分析比萨馅料的比例和分布”,如图3-36所示。

此外,Algorithms for Image Processing and Computer Vision一书的第8章举了个很生动的例子—如何从果盘中分辨出西红柿和胡萝卜,这里采用了一个有效的特征值—Hue(色相)综合Luminance(亮度)—西红色表面光滑,会比胡萝卜有明显的反光,如图3-37所示。尽管是基于彩色图片分析的,并不是深度数据,但手法基本一致。
3.5.2 人体部位分类
在上一个环节,系统将玩家从背景图像中剥离出来,或者说是对人体与背景的分类。这一环节的主要工作是从深度图像中将人体各个部位识别出来,比如头部、躯干、四肢、手臂、腿等大块关联的肢体。如图3-38所示,我们用不同的颜色标注出人体的部位,这是进一步的分类过程,Kinect for Xbox的机器学习有32个不同人体部位。

在Xbox 360设计的游戏场景中,人们会跳舞、模拟开车、拳击甚至驾驶赛车。由于身高、背景文化的差异,人体姿态也是呈现出不同的状态。系统是无法穷举人体的所有姿态和行为的,只能通过机器学习去抽象常见的姿态和行为,进而去推测、理解人类的意图。智能的系统就出现在这一环节,带来更为友好的人机互动。
比如我们玩Kinect赛车游戏,你是如何握方向盘的呢?让100个人来模仿如何开车,可能会有100种答案。有些人会将两手分别握住面前的10点和2点位置,有些人可能会只用一手握住12点位置;有些人可能会背靠椅子坐着;同样地,模仿脚踩油门、刹车和离合器的方式也会五花八门。所有这些方式都能让我们驾驶,而技术的工作就是要能识别所有这些方式—让机器理解你。
比如你路上遇到一熟人,上去寒暄。此时大脑并不是通过遍历所有认识的人脸来进行比对的,而是基于音容笑貌的一些特点。同样,人体部位是通过特征值来快速分类的。这一过程要足够快而精确,会用到“机器学习”算法,后面会详细介绍。
3.5.3 从人体部位识别关节
我们已经获得了32个不同的人体部位,接下来要进一步识别人体的关节点。
图3-39为达芬奇的“维特鲁威人”图,“维特鲁威人”也是达芬奇以比例最精准的男性为蓝本,因此后来常以“完美比例”来形容其中的男性。

从图中大家可以看出,人体的关节连接着躯干、四肢、头颅等,包括指关节、腕关节、肘关节、膝关节、髋关节、肩关节、胸锁关节、下颌关节、趾关节。找到这些关节,人体的骨骼识别就大功告成了,接下来还可以基于这些关节点做运动分析、姿态分析。那么如何定位这些关节点呢?答案还是基于机器学习进行分类(Classification)。
这当中也有一些复杂的问题,比如人体在运动中某些部位会重叠,如图3-40所示。
如图3-40所示,从左到右的各列分别是:
1)人体深度图—第一轮分类,从背景环境中剥离;
2)已经分类的32个人体部位,相邻不同色着色—第二轮分类;
3)考虑到人体部位的重叠,分别从正面、侧面、复试角度去分析、机器学习,根据每一个可能的像素来确定关节点。

最后,系统根据“骨骼跟踪”的20个关节点来生成一幅骨架系统。通过这种方式Kinect能够基于充分的信息最准确地评估人体实际所处位置。
Kinect的骨骼识别可以兼容不同身高的人体,从幼儿到成人都可以识别得准确;除了站姿之外,还可以分辨出坐立在椅子或沙发上的人体,如图3-41所示。
Kinect是先识别人体部位进而再推断出关节点,这是一个近似度概率匹配、评估的过程:逐个像素扫描,先局部再总体。
问:“为什么我手里提着一个包,Kinect依然可以很准确地识别我的手关节?”
答:Kinect具备区分人手和物体的能力,就是前面多次提到的“分类”技术。通常情况下手的颜色会与物体的颜色有很大的差别,传统计算机视觉的分类技术可以通过设定颜色特征阈值来实现。通过“肤色分割”的方法应该是最为简单高效的,但这种方法并不完美,当物体颜色与肤色接近时,就会发生误判断。因此,Kinect还是从深度信息着手。通常物体边缘的深度信息会与手指深度信息有着明显的不同,将色彩与深度两者结合起来考虑,就能够很好地将物体和手指分割开。如果物体边缘过于凹凸不平,而且颜色与肤色接近,识别也会出现偏差的情况。
有人可能还会问:“那么,穿着长裙或民族服装的用户,Kinect可以很好地进行骨骼识别吗?”在回答这个问题之前,我们不妨看一下汽车导航软件的优化。GPS信号在高架或者隧道里会丢失,一些好的GPS软件会结合陀螺仪地球重力场以及当前车速,通过水准移动插值法来拟合、推测行车轨迹。Kinect的处理机制也很类似,对于被遮盖或重叠的人体部位,通过相邻的关节点以及机器学习的结果,来进行准确的部位推测。因此,即使你穿着长裙,Kinect还是可以准确识别或者推测出你的腿骨和膝关节。后面章节介绍Kinect SDK时会提到骨骼跟踪的每个关节指点(Joint)的状态有三种:Tracked(已跟踪)、Not Tracked(未跟踪)和Infered(推测而来)。
扩展阅读 如果你对以上Kinect相关的模式识别、计算机图形视觉、人工智能感兴趣,推荐你进一步阅读以下文章:
Jamie Shotton和Alex Kimpman等人联合发表的重要论文,也是Kinect原理基础Real-Time Human Pose Recognition in Parts from Single Depth Images。
Real-time body part recognition for Kinect,作者Jamie Shotton。
Efficient offset regression of body joint positions,作者Jamie Shotton。
Real-Time Classification of Dance Gestures from Skeleton Animation,作者MichalisRaptis、DarkoKirovski、Hugues Hoppe。
3.5.4 会“机器学习”的“Kinect大脑”
现在,我们就要谈Kinect最具智慧的部分—Kinect骨骼跟踪的机器学习技术,该技术获得2011年MacRobert Award工程创新大奖,其被誉为“Kinect大脑”,实至名归。
正如现实世界的物体在人眼视网膜成像后,通过视神经传输给大脑一样,Kinect通过红外摄像头看到三维的世界后,将这部分深度数据传输到“Kinect大脑”去处理。接着深度图像的每一个像素会被进行分析评估,其特征变量都会被分类,在一个称为“随机决策库”里进行搜索,来判断它是人体的哪个部位,这是一个概率推测的过程。比如一个像素有60%的几率属于脚,70%的几率属于腿,80%的几率属于头部。这个概率的评估也是动态的过程,会随着像素的不断扫描而修正。如图3-42所示,同一个人的同一只手,在不同姿态下的特征表现差异也是很大的。
我们来看Kinect在养成阶段的“机器学习”过程。
机器学习需要大量的输入数据,故需要不同身高、体型、着装、肤色、文化背景的志愿者参与进来,提供了大量的训练数据。这些数据首先被记录在一个庞大的影像数据库中;接着通过机器学习技术,Kinect归纳出各种特征值,不断提高搜索的准确度和速度。

开发人员安排志愿者在摄像机前进行运动,系统的成像会对人体进行分类,将人体特征分为几组变量。这些变量是人们日常生活中常见的,比如“基本特点”是对对象的性别、年龄、身高、胖瘦程度等的辨别;“姿势和动作”则是对人体静态姿态和动态运动的辨别。其他还有诸如“旋转三维”、“头发和衣服”、“体重和高度变量”等多个类别组,如图3-43所示。
最初系统需要分析数百万张图像,都是预先用可识别人体部位(如手臂、腿和躯干等)的深度图像。1000多台服务器集群,每天“消化”掉这些深度图像,大量分析结果被编排成能够迅速决策识别人体各部位的树状图,如图3-44所示。一旦树状图构建完毕,便可以根据Kinect采集到的深度数据进行像素扫描,从而识别出32组人体部位。

微软Game Studio开发这一套人工智能被称为Exemplar(模型)系统。数以TB计的数据被输入到集群系统中,Kinect以像素级的“眼光”来辨认手、脚以及它看到的其他身体部位。如图3-45所示,右图就是用来训练和测试Exemplar的数据之一,百万张的训练图片需要计算机进行模式识别和分类,这里面涉及先进的算法和DryadLINQ (large-scale distributed cluster computing from MS Research)并行处理技术,左图为Kinect Lab里处理训练照片的服务器群。
在这个过程中,系统会收集到大量的运动捕捉数据——在最初的研究中,像哪怕跳舞、踢球或跑步这样的运动,都会产生50万的数据帧。研究者后来将数据帧数量限制在10万左右。
你之前可能会有这样的疑虑:Kinect SDK中是否有用于存储一个人体部位并与动作姿态相关的、用于运行时匹配模式数据库?
现在你肯定明白SDK并不包含这样的数据库,只有提炼过的人体部位特征值信息以及最终训练结果的“决策树”。通过海量样本数据输入,在经验学习中不断改善识别算法的性能,这就是“机器学习”的目标。前面已经谈到过,体态、姿势的无穷组合,也是无法枚举的。
谈到机器学习,不得不再提一下平凡而又神奇的“贝叶斯算法”,其涉及先验概率分布估计、决策树裁剪,从而不断优化以提高命中的精度和速度,如图3-46所示。
机器学习的应用非常广泛,日常你使用的数码相机中的人脸检测也是基于机器学习的,现在更为高级的还支持“笑脸快门”模式。
3.5.5 骨骼跟踪的精度和效率
2011年,斯皮尔伯格监制的《丁丁历险记》中的3D人物栩栩如生,该电影制作过程中就应用了大量的动作捕捉。动作捕捉技术在“二战”后由斯坦福大学神经生物力学实验室发明,最初运用于中风及脑损伤患者康复。迪士尼率先想到把这一技术运用到动画制作领域,让不完美的动画效果更为逼真和流畅。我们在《丁丁历险记》片场看到,大多为光学式捕捉技术—演员套上黑色衣服,身体关键关节及部位被贴上特制发光点(术语“Marker”),视觉系统将识别和处理这些“Marker”。电影《最终幻想》和《阿凡达》也采用了动作捕捉技术,摄影机则把表演者的连续动图像序列保存下来,然后进行后期处理和合成。
之所以要提“动作捕捉”,是因为Kinect要在人体未穿戴任何“Marker”的情况下,识别人体的各个关节,这个环节也就是我们多次提到的“骨骼跟踪”。
打个比方,Kinect的骨骼跟踪就是给每个玩家穿上动作捕捉的“Marker”点,如图3-47所示。
你也许已经想到,是否可以用Kinect来做电影动作捕捉呢?传统电影里面动作捕捉,在美国是一个小时几千美金啊。为什么不呢?那么精度和实时性够吗?下面讨论关于Kinect骨骼跟踪的精度和效率问题。
目前Kinect for Xbox 360后台游戏系统可以对人体的32个部位进行实时追踪,在Kinect for Windows SDK v1.0中骨骼对象(Skeleton)只暴露了20个骨骼关节支点(Joint),在单个Kinect工作的情况下,还无法识别人体的正面或背面,因此用Kinect来做电影动作捕捉效果有限,但肯定可以达到一些平面动画的合成效果。
前面我们在硬件构成章节已经分析了Kinect的一些技术参数。比如其红外摄影机的默认工作在30FPS上和其分辨率为320×240,这意味着“动作传递”将有33ms(1/30s)的延迟。
问:这会不会造成骨骼跟踪乃至游戏中动作捕捉上的延迟?为何不使用60FPS以上的规格采样?
答:PrimeSense公司提供的PS1080芯片处理能力有限,只能处理视频流640×480/30FPS,深度流320×240/30FPS。因为设计之初是针对Xbox 360的游戏,后面我们会展开分析,刷新率对延迟的影响并不大。
为什么说30FPS影像更新频率造成的延迟会很有限?因为人类对事物的反应速度几乎都超过100ms,已经大于30FPS所带来的33ms延迟,你是意识不到的。但这只是PS1080芯片采样后处理的环节,后面还有传输、深度图像到人体骨骼的跟踪,再到对动作的识别,包括速度、方向、轨迹的实时计算,以及游戏中的Avatar表面图像的渲染等,这些处理环节的快慢将直接影响到最终的用户体验。因此,Kinect硬件采集、芯片处理不是延迟的主因,软件处理是主要考验的环节,也是我们要分析一探究竟的地方。
根据互联网一些第三方的实际测试,Kinect对于远在2m左右范围的物体而言,X和Y 维度上的空间精度是3mm,Z维度上的空间精度为1cm。这样的精度已经相当了得了。
- 出拳的速度
比如Kinect for Xbox 360运动会(Sports)里的拳击游戏,能充分体现出Kinect对高速运动物体的捕捉能力,如图3-48所示。

作为一个拳击入门的成年人来说,空拳每秒4次是没问题的,这也基本是游戏玩家的极限,这种出拳的速度和击打节奏能在游戏里面很清晰地表达出来。专业级的拳击手,每秒出拳速度会在7次以上。
- 测量你的体重
如果说Kinect可以用来测量你的身高,你可能会觉得稀松平常,很容易理解。那么,用Kinect来测量你的体重,你是否会感到惊讶呢?或者你会反问这有意义吗?
美国太空总署表示考虑用Kinect在太空中给宇航员测量体重。宇航员长期在空间站生活,零重力的环境会导致肌肉萎缩,因此体重也是作为一项关键的体征信息被监控。但在没有重力的状态下,这的确是个难题。之前通过弹簧共振的原理来测量,但不是很方便。现在通过Kinect的深度测量,构成人体的三维模型,同时结合庞大的数据库来进行匹配。Kinect通过“目测”判断你的体重,而且准确率可达97%。