前言
最近好忙好忙的说,连更新都慢了一周呢,收到豆瓣的催稿好就赶紧开始码字了,哭。
最近阿法狗好火,所以就特地讲下决策树。如果你喜欢本书或者想要支持我,可以直接在豆瓣购买哦!https://read.douban.com/column/3346397/
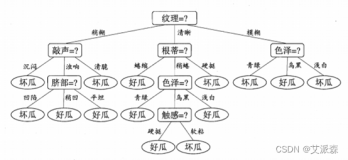
决策树就像是真的一棵树,它从一个主干逐渐分支,构成一个完整的决策树。
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:
- 决策树模型可以读性好,具有描述性,有助于人工分析。
- 效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
比如我现在我同事在我旁边,我问他“如果你找个女朋友喜欢什么样的?”
他回答“长得好看,身高不要太矮,170左右、开朗、善良、孝顺、脾气好”。

同事的回答可以整理成上述的决策树图,简单来说决策树就是根据多个条件将某个事物归于某个类别。
只要遇到个女生,想要直到是否是同事喜欢的只需要代入已经构建好的决策树模型中便可以轻松得知到底是喜欢还是不喜欢。
决策树可以按照如下步骤构建:
- 设立开始节点,所有的记录从这里出发。
- 决定哪些条件合适作为节点。
- 将节点继续分为两个子节点。
- 对子节点重复上面三个步骤。
决策树的变量可以有两种:
- 数字型:变量类型是整数或浮点数。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。
- 名称型:类似编程语言中的枚举类型,变量只能重有限的选项中选取,比如前面例子中的“婚姻情况”,只能是“单身”,“已婚”或“离婚”。使用“=”来分割。
虽然在选择节点的时候,很多人喜欢用数学的角度去分析哪些条件更适合,在对待一些涉及到人、情感等问题上,往往是人的主观意识更为重要。所以这里个人建议在涉及到人的主观意识类的问题不妨从纯粹的主观角度出发去思考。
在大数据领域有时候使用决策树并不能有很好的效果,因为决策树的模型是在得到数据之前就建立好的,如果数据繁多的话会浪费很多数据,决策树也可以看作是一种贪心算法,如果某一个节点有失误那么之后的决策就会出错。
注:贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
不妨在初期建立的决策树的决策条件放宽松点,经过长期大量的数据训练、完善后再将决策树的模型作为分析的核心。
当然也有人提倡说用随机森林,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数(出现最多的结果)而定。
在利用决策树分类的时候,如果样本数据缺失一些变量,但决策树的决策过程中并未用到这些变量,那么就可以将这些样本作为完整的样本。当决策用到了缺失的变量,不妨试试随机森林或者在当前节点做多数投票来预测这个缺失的变量是什么。
或者可以参照其它完整的样本的结果来进行预测。比如我们最开始的举的例子,如果不知道B喜欢男的女的,但是知道其它条件,那么可以用其它条件与其它完整的样本及其结果进行比较,预测下B喜欢男的女的。
可能讲到这里会有人问说什么样的特征适合作为变量呢?
一般是通过卡方检验、信息增益、相关系数等等算法来对不同的样本进行观测,看看哪些特征更适合作为变量。
个人建议是这些特征一般都有决定性作用并且不会出现歧义的情况就不妨拿来做变量试试。
讲到决策树就会讲到熵,玻尔兹曼认为,任何粒子的常态都是随机运动,也就是"无序运动",如果让粒子呈现"有序化",必须耗费能量。所以,能量可以被看作"有序化"的一种度量。热力学第二定律实际上是说,当一种形式的"有序化"转化为另一种形式的"有序化",必然伴随产生某种"无序化"。一旦能量以"无序化"的形式存在,就无法再利用了,除非从外界输入新的能量,让无序状态重新变成有序状态。
"熵"就是"无序化"的度量。考虑到"无序化"代表着混乱(实质是随机运动)。
熵是无序性(或不确定性)的度量指标。假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵定义为:

熵代表一个系统的杂乱程度,熵越大,系统越杂乱。对一个数据集中数据的分类就是使得该数据集熵减小的过程。
决策树算法就是一个划分数据集的过程。划分数据集的原则就是:将无序的数据变得更加有序。
在决策树中最出名的莫过于ID3,ID3算法(Iterative Dichotomiser 3 迭代二叉树3代)是一个由Ross Quinlan发明的用于决策树的算法。
这个算法是建立在奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树。
通过ID3可以选择到最适合的节点,我们接下来来做个简单的推导。(这里就使用我在网上找到的一个例子,感觉这个例子不错,我才不是懒得写表格呢(~ o ~)~zZ ,例子来源zhangchaoyang)

我们现在从别的地方扒来了一个表格,表格中统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),并已知这些天气是否打球(play)。如果给出新一天的气象指标数据:sunny,cool,high,TRUE,请亲爱的们判断一下会不会去打球。
构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,这样我们有望得到一棵高度最矮的决策树。
在没有给定任何天气信息时,根据历史数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为:

属性有4个:outlook,temperature,humidity,windy。我们首先要决定哪个属性作树的根节点。
对每项指标分别统计:在不同的取值下打球和不打球的次数。

下面我们计算当已知变量outlook的值时,信息熵为多少。
outlook=sunny时,2/5的概率打球,3/5的概率不打球。entropy=0.971
outlook=overcast时,entropy=0
outlook=rainy时,entropy=0.971
而根据历史统计数据,outlook取值为sunny、overcast、rainy的概率分别是5/14、4/14、5/14,所以当已知变量outlook的值时,信息熵为:5/14 × 0.971 + 4/14 × 0 + 5/14 × 0.971 = 0.693
这样的话系统熵就从0.940下降到了0.693,信息增溢gain(outlook)为0.940-0.693=0.247
同样可以计算出gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048。
gain(outlook)最大(即outlook在第一步使系统的信息熵下降得最快),所以决策树的根节点就取outlook。

接下来要确定N1取temperature、humidity还是windy?在已知outlook=sunny的情况,根据历史数据,我们作出类似table 2的一张表,分别计算gain(temperature)、gain(humidity)和gain(windy),选最大者为N1。
依此类推,构造决策树。当系统的信息熵降为0时,就没有必要再往下构造决策树了,此时叶子节点都是纯的--这是理想情况。最坏的情况下,决策树的高度为属性(决策变量)的个数,叶子节点不纯(这意味着我们要以一定的概率来作出决策)。