本节书摘来自华章社区《Hadoop大数据分析与挖掘实战》一书中的第3章,第3.2节Hive原理,作者张良均 樊哲 赵云龙 李成华 ,更多章节内容可以访问云栖社区“华章社区”公众号查看
3.2 Hive原理
3.2.1 Hive架构
Hive的架构如图3-2所示。
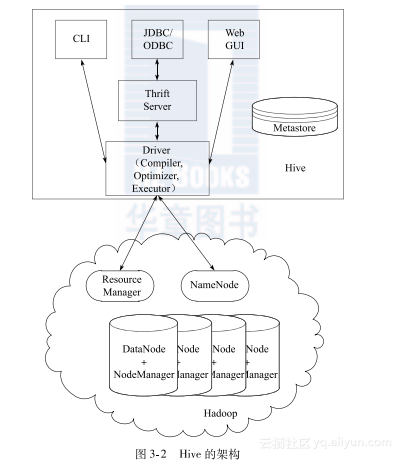
从图3-2中可以看到,Hive包含用户访问接口(CLI、JDBC/ODBC、GUI和Thrift Server)、元数据存储(Metastore)、驱动组件(包括编译、优化、执行驱动)。
用户访问接口即用户用来访问Hive数据仓库所使用的工具接口。CLI(command line interface)即命令行接口。Thrift Server是Facebook开发的一个软件框架,它用来开发可扩展且跨语言的服务,Hive集成了该服务,能让不同的编程语言调用Hive的接口。Hive客户端提供了通过网页的方式访问Hive提供的服务,这个接口对应Hive的HWI组件(Hive web interface),使用前要启动HWI服务。
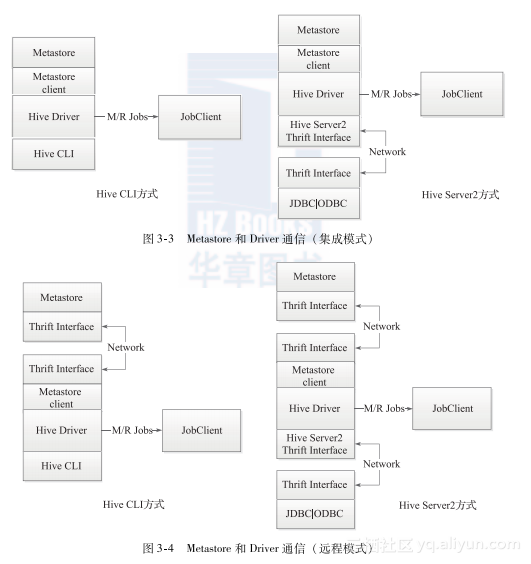
Metastore是Hive中的元数据存储,主要存储Hive中的元数据,包括表的名称、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等,一般使用MySQL或Derby数据库。Metastore和Hive Driver驱动的互联有两种方式,一种是集成模式,如图3-3所示;一种是远程模式,如图3-4所示。
驱动组件包括编译器、优化器和执行引擎,分别完成HQL查询语句的词法分析、语法分析、编译、优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
3.2.2 Hive的数据模型
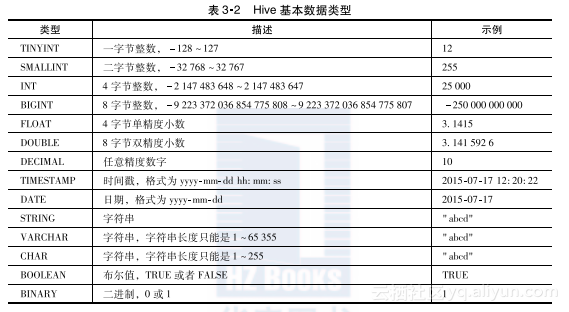
Hive支持多种基本数据类型,具体如表3-2所示。
Hive中的所有数据都存储在HDFS中,Hive中包含以下数据模型:表、外部表、分区、桶。
1)表(Table):Hive中的表和关系型数据库中的表在概念很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过$HIVE_HOME/conf/hive-site.xml配置文件中的hive.metastore.warehouse.dir属性来配置,这个属性的默认值是/user/hive/warehouse(这个目录在HDFS上),可以根据实际情况来修改这个配置。如果有一个表employees,那么在HDFS中会创建/user/hive/warehouse/ employees目录,employees表的所有数据都存放在这个目录中。
2)外部表(External Table):Hive中的外部表和表很类似,但是其数据不是放在hive.metastore.warehouse.dir配置的目录中,而是放在建立表时指定的目录。创建外部表可以在删除该外部表时,不删除该外部表所指向的数据,它只会删除外部表对应的元数据;但是如果要删除表,该表对应的所有数据包括元数据都会被删除。
3)分区(Partition):在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都存储在对应的目录中。比如,针对下面的建表语句:crea
te table employees (id int, name string, salary double)
partitioned by (dept string);在HDFS中,其数据的目录如下:/user/hive/warehouse/employees
/dept=hr/
/dept=support/
/dept=engineering/
/dept=training/即在进行数据存储时,指定的分区列的每一个值都会新建一个目录。4)桶(Bucket):对指定的列计算其哈希值,根据哈希值切分数据,目的是并行,每一个桶对应一个文件(注意和分区的区别)。例如,将employees表的id列分散至8个桶中,那么首先会对每个桶进行编号,从0~7,然后对id列的值计算哈希值,再把计算的哈希值使用求余运算得到0~7的某个数字,把该数据放入数字对应的桶中

